AWS Big Data Blog
Category: Technical How-to

Introducing workload simulation workbench for Amazon MSK Express broker
In this post, we introduce the workload simulation workbench for Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express Broker. The simulation workbench is a tool that you can use to safely validate your streaming configurations through realistic testing scenarios.

Proactive monitoring for Amazon Redshift Serverless using AWS Lambda and Slack alerts
In this post, we show you how to build a serverless, low-cost monitoring solution for Amazon Redshift Serverless that proactively detects performance anomalies and sends actionable alerts directly to your selected Slack channels.

Modernize business intelligence workloads using Amazon Quick
In this post, we provide implementation guidance for building integrated analytics solutions that combine the generative BI features of Amazon Quick with Amazon Redshift and Amazon Athena SQL analytics capabilities.

Streamline Apache Kafka topic management with Amazon MSK
In this post, we show you how to use the new topic management capabilities of Amazon MSK to streamline your Apache Kafka operations. We demonstrate how to manage topics through the console, control access with AWS Identity and Access Management (IAM), and bring topic provisioning into your continuous integration and continuous delivery (CI/CD) pipelines.

How to set up an air-gapped VPC for Amazon SageMaker Unified Studio
In this post, we explore scenarios where customers need more control over their network infrastructure when building their unified data and analytics strategic layer. We’ll show how you can bring your own Amazon Virtual Private Cloud (Amazon VPC) and set up Amazon SageMaker Unified Studio for strict network control.

Navigating multi-account deployments in Amazon SageMaker Unified Studio: a governance-first approach
In this post, we explore SageMaker Unified Studio multi-account deployments in depth: what they entail, why they matter, and how to implement them effectively. We examine architecture patterns, evaluate trade-offs across security boundaries, operational overhead, and team autonomy. We also provide practical guidance to help you design a deployment that balances centralized control with distributed ownership across your organization.

Automated tag-based DAG permission management in Amazon MWAA
In this post, we show you how to use Apache Airflow tags to systematically manage DAG permissions, reducing operational burden while maintaining robust security controls that complement infrastructure-level security measures.
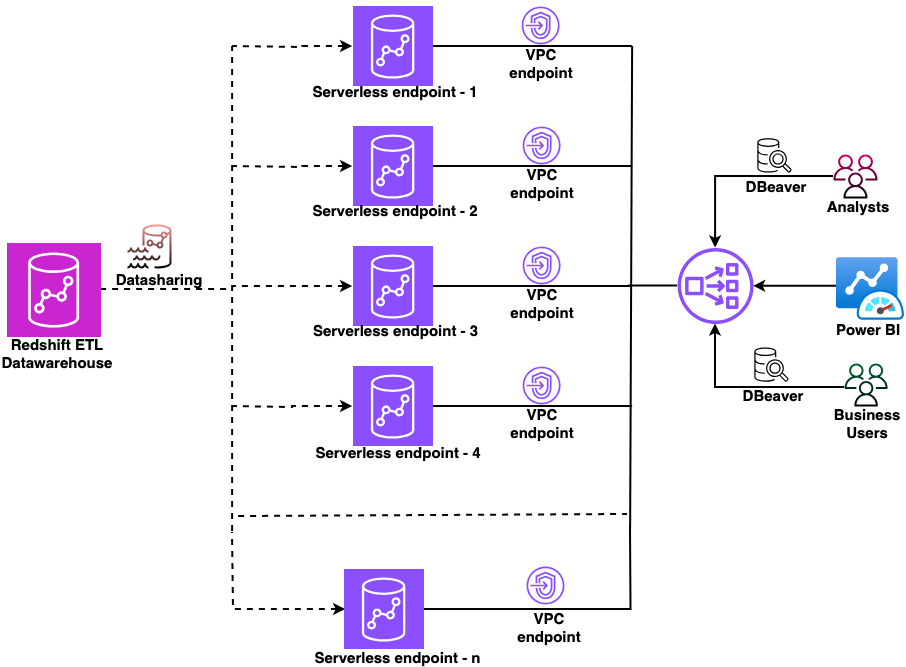
Secure multi-warehouse Amazon Redshift access behind a Network Load Balancer using Microsoft Entra ID
In this post, we show you how to configure a native identity provider (IdP) federation for Amazon Redshift Serverless using Network Load Balancer. You will learn how to enable secure connections from tools like DBeaver and Power BI while maintaining your enterprise security standards.

Securely connect Kafka client applications to your Amazon MSK Serverless cluster from different VPCs and AWS accounts
In this post, we show you how Kafka clients can use Zilla Plus to securely access your MSK Serverless clusters through Identity and Access Management (IAM) authentication over PrivateLink, from as many different AWS accounts or VPCs as needed. We also show you how the solution provides a way to support a custom domain name for your MSK Serverless cluster.

Build AWS Glue Data Quality pipeline using Terraform
AWS Glue Data Quality is a feature of AWS Glue that helps maintain trust in your data and support better decision-making and analytics across your organization. You can use Terraform to deploy AWS Glue Data Quality pipelines. Using Terraform to deploy AWS Glue Data Quality pipeline enables IaC best practices to ensure consistent, version controlled and repeatable deployments across multiple environments, while fostering collaboration and reducing errors due to manual configuration. In this post, we explore two complementary methods for implementing AWS Glue Data Quality using Terraform.