AWS Big Data Blog
How Klarna Bank AB built real-time decision-making with Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
This is a joint post co-authored with Nir Tsruya from Klarna Bank AB.
Klarna is a leading global payments and shopping service, providing smarter and more flexible shopping and purchase experiences to 150 million active consumers across more than 500,000 merchants in 45 countries. Klarna offers direct payments, pay after delivery options, and instalment plans in a smooth one-click purchase experience that lets consumers pay when and how they prefer to. The ability to utilize data to make near-real-time decisions is a source of competitive advantage for Klarna.
This post presents a reference architecture for real-time queries and decision-making on AWS using Amazon Kinesis Data Analytics for Apache Flink. In addition, we explain why the Klarna Decision Tooling team selected Kinesis Data Analytics for Apache Flink for their first real-time decision query service. We show how Klarna uses Kinesis Data Analytics for Apache Flink as part of an end-to-end solution including Amazon DynamoDB and Apache Kafka to process real-time decision-making.
AWS offers a rich set of services that you can use to realize real-time insights. These services include Kinesis Data Analytics for Apache Flink, the solution Klarna that uses to underpin automated decision-making in their business today. Kinesis Data Analytics for Apache Flink allows you to easily build stream processing applications for a variety of sources including Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), and Amazon MQ.
The challenge: Real-time decision-making at scale
Klarna’s customers expect a real-time, frictionless, online experience when shopping and paying online. In the background, Klarna needs to assess risks such as credit risk, fraud attempts, and money laundering for every customer credit request in every operating geography. The outcome of this risk assessment is called a decision. Decisions generate millions of risk assessment transactions a day that must be run in near-real time. The final decision is the record of whether Klarna has approved or rejected the request to extend credit to a consumer. These underwriting decisions are critical artefacts. First, they contain information that must be persisted for legal reasons. Second, they are used to build profiles and models that are fed into underwriting policies to improve the decision process. Under the hood, a decision is the sum of a number of transactions (for example, credit checks), coordinated and persisted via a decision store.
Klarna wanted to build a framework to ensure decisions persist successfully, ensuring timely risk assessment and quick decisions for customers. First, the Klarna team looked to solve the problem of producing and capturing decisions by using a combination of Apache Kafka and AWS Lambda. By publishing decision artefacts directly to a Kafka topic, the Klarna team found that high latency could cause long transaction wait times or transactions to be rejected altogether, leading to delays in getting ratified decisions to customers in a timely fashion and potential lost revenue. This approach also caused operational overhead for the Klarna team, including management of the schema evolution, replaying old events, and native integration of Lambda with their self-managed Apache Kafka clusters.
Design requirements
Klarna was able to set out their requirements for a solution to capture risk assessment artefacts (decisions), acting as a source of truth for all underwriting decisions within Klarna. The key requirements included at-least once reliability and millisecond latency, enabling real-time access to decision-making and the ability to replay past events in case of missing data in downstream systems. Additionally, the team needed a system that could scale to keep pace with Klarna’s rapid [10 times] growth.
Solution overview
The solution consists of two components: a combination of an highly available API with DynamoDB as the data store to store each decision, and Amazon DynamoDB Streams with Kinesis Data Analytics. Kinesis Data Analytics is a fully managed Apache Flink service and used to stream, process, enrich, and standardize the decision in real time and replay past events (if needed).
The following diagram illustrates the overall flow from end-user to the downstream systems.
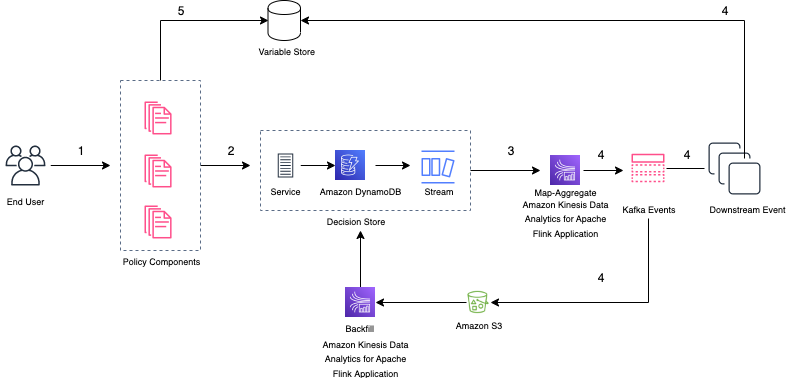
The flow includes the following steps:
- As the end-user makes a purchase, the policy components assess risk and the decision is sent to a decision store via the Decision Store API.
- The Decision Store API persists the data in DynamoDB and responds to the requester. Decisions for each transaction are time-ordered and streamed by DynamoDB Streams. Decision Store also enables centralised schema management and handles evolution of event schemas.
- The Kinesis Data Analytics for Apache Flink application is the consumer of DynamoDB streams. The application makes sure that the decisions captured are conforming to the expected event schema that is then published to a Kafka topic to be consumed by various downstream systems. Here, Kinesis Data Analytics for Apache Flink plays a vital part in the delivery of those events: aggregating, enriching, and mapping data to adhere to the event schema. This provides a standardized way for consumers to access decisions from their respective producers. The application enables at-least once delivery capability, and Flink’s checkpoint and retry mechanism guarantees that every event is processed and persisted.
- The published Kafka events are consumed by the downstream systems and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The events stored in Amazon S3 reflect every decision ever taken by the producing policy components, and can be used by the decision store to backfill and replay any past events. In addition to preserving the history of decision events, events are also stored as a set of variables in the variable store.
- Policy components use the variable store to check for similar past decisions to determine if a request can be accepted or denied immediately. The request is then processed as described by the preceding workflow, and the next subsequent request will be answered by the variable store based on the result of the previous decision.
The decision store provides a standardized workflow for processing and producing events for downstream systems and customer support. With all the events captured and safely stored in DynamoDB, the decision store provides an API for support engineers (and other supporting tools like chatbots) to query and access past decisions in near-real time.
Solution impact
The solution provided benefits in three areas.
First, the managed nature of Kinesis Data Analytics allowed the Klarna team to focus on value-adding application development instead of managing infrastructure. The team is able to onboard new use cases in less than a week. They can take full advantage of the auto scaling feature in Kinesis Data Analytics and pre-built sources and destinations.
Second, the team can use Apache Flink to ensure the accuracy, completeness, consistency, and reliability of data. Flink’s native capability of stateful computation and data accuracy through the use of checkpoints and savepoints directly supports Klarna team’s vision to add more logic into the pipelines, allowing the team to expand to different use cases confidently. Additionally, the low latency of the service ensures that enriched decision artefacts are available to consumers and subsequently to the policy agents for future decision-making in near-real time.
Third, the solution enables the Klarna team to take advantage of the Apache Flink open-source community, which provides rich community support and the opportunity to contribute back to the community by bug fixing or adding new features.
This solution has proven to scale with increased adoption of a new use case, translating to a 10-times increase in events over 3 months.
Lessons learned
The Klarna team faced a few challenges with Flink serialization and upgrading Apache Flink versions. Flink serialization is an interesting concept and critical for the application’s performance. Flink uses a different set of serializers in order to serialize data between the operators. It’s up to the team to configure the best and most efficient serializer based on the use case. The Klarna team configured the objects as Flink POJO, which reduced the pipeline runtime by 85%. For more information, refer to Flink Serialization Tuning Vol. 1: Choosing your Serializer — if you can before deploying a Flink application to production.
The other challenge faced by the team was upgrading the Apache Flink version in Kinesis Data Analytics. Presently, the Kinesis Data Analytics for Apache Flink application requires the creation of a new Kinesis Data Analytics for Apache Flink application. Currently, reusing a snapshot (the binary artefact representing the state of the Flink application, used to restore the application to the last checkpoint taken) is not possible between two different applications. For that reason, upgrading the Apache Flink version requires additional steps in order to ensure the application doesn’t lose data.
What’s next for Klarna and Kinesis Data Analytics for Apache Flink?
The team is looking into expanding the usage of Kinesis Data Analytics and Flink in Klarna. Because the team is already highly experienced in the technology, their first ambition will be to own the infrastructure of a Kinesis Data Analytics for Apache Flink deployment, and connect it to different Klarna data sources. The team then will host business logic provided by other departments in Klarna such as Fraud Prevention. This will allow the specialised teams to concentrate on the business logic and fraud detection algorithms, while decision tooling will handle the infrastructure.

Klarna, AWS, and the Flink community
A key part of choosing Kinesis Data Analytics for Apache Flink was the open-source community and support.
Several teams within Klarna created different implementations of a Flink DynamoDB connector, which were used internally by multiple teams. Klarna then identified the opportunity to create a single maintained DynamoDB Flink connector and contribute it to the open-source community. This has initiated a collaboration within Klarna, led by the Klarna Flink experts and accompanied by Flink open-source contributors from AWS.
The main principle for designing the DynamoDB Flink connector was utilizing the different write capacity modes of DynamoDB. DynamoDB supports On-demand and Provisioned capacity modes and each behaves differently when it comes to how it handles incoming throughput. On-demand mode will automatically scale up DynamoDB write capacity and apply itself to the incoming load. However, Provisioned mode is more limiting, and will throttle incoming traffic according to the provisioned write capacity.
To comply with this process, the DynamoDB Flink connector was designed to allow concurrent writes to DynamoDB. The number of concurrent requests can be configured to comply with DynamoDB’s capacity mode. In addition, the DynamoDB Flink connector supports backpressure handling in case the DynamoDB write provisioning is low compared to the incoming load from the Apache Flink application.
At the time of writing, the DynamoDB Flink connector has been open sourced.
Conclusion
Klarna has successfully been running Kinesis Data Analytics for Apache Flink in production since October 2020. It provides several key benefits. The Klarna development team can focus on development, not on cluster and operational management. Their applications can be quickly modified and uploaded. The low latency properties of the service ensure a near-real-time experience for end-users, data consumers, and producers, which underpin risk assessment and the decision-making processes underpinning continuous traffic growth. At the same time, exactly-once processing in combination with Flink checkpoints and savepoints means that critical decision-making and legal data is not lost.
To learn more about Kinesis Data Analytics and getting started, refer to Using a Studio notebook with Kinesis Data Analytics for Apache Flink and More Kinesis Data Analytics Solutions on GitHub.
About the authors
 Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering teams focusing mainly on real time data processing and analytics at large scale.
Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering teams focusing mainly on real time data processing and analytics at large scale.
 Ankit Gupta is a Senior Solutions Architect at Amazon Web Serves based in Stockholm, Sweden, where we helps customers across the Nordics succeed in Cloud. He’s particularly passionate about building strong Networking foundation in Cloud.
Ankit Gupta is a Senior Solutions Architect at Amazon Web Serves based in Stockholm, Sweden, where we helps customers across the Nordics succeed in Cloud. He’s particularly passionate about building strong Networking foundation in Cloud.
 Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.
Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.