AWS Big Data Blog
How ZS created a multi-tenant self-service data orchestration platform using Amazon MWAA
This is post is co-authored by Manish Mehra, Anirudh Vohra, Sidrah Sayyad, and Abhishek I S (from ZS), and Parnab Basak (from AWS). The team at ZS collaborated closely with AWS to build a modern, cloud-native data orchestration platform.
ZS is a management consulting and technology firm focused on transforming global healthcare and beyond. We leverage our leading-edge analytics, plus the power of data, science, and products, to help our clients make more intelligent decisions, deliver innovative solutions, and improve outcomes for all. Founded in 1983, ZS has more than 12,000 employees in 35 offices worldwide.
ZAIDYNTM by ZS is an intelligent, cloud-native platform that helps life sciences organizations shape the future. Its analytics, algorithms, and workflows empower people, transform processes, and unlock real value. Designed to learn and grow with our clients, the platform is modular, future-ready, and fueled by global connectivity. And as more people engage, share, and build, our platform gets smarter—helping organizations fuel discovery, connect with customers, deliver treatments, and improve lives. ZAIDYN is helping companies of all sizes gain fluency in the full spectrum of life sciences so they can move faster, together through its Data & Analytics, Customer Engagement, Field Performance and Clinical Development offerings.
ZAIDYN Data & Analytics apps provide business users with self-service tools to innovate and scale insights delivery across the enterprise. ZAIDYN Data Hub (a part of the Data & Analytics product category) provides self-service options for guided workflows, data connectors, quality checks, and more. The elastic data processing offered by AWS helps prioritize processing speeds.
Data Hub customers wanted a one-stop solution for managing their data pipelines. A solution that does not require end users to gain additional knowledge about the nitty-gritties of the tool, one which is easy for users to get onboarded on, thereby increasing the demand for data orchestration capabilities within the application. A few of the sophisticated asks like start and stop of workflows, maintaining history of past runs, and providing real-time status updates for individual tasks of the workflow became increasingly important for end clients. We needed a mature orchestration tool, which led us to Amazon Managed Workflows for Apache Airflow (Amazon MWAA).
Amazon MWAA is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud at scale.
In this post, we share how ZS created a multi-tenant self-service data orchestration platform using Amazon MWAA.
Why we chose Amazon MWAA
Choosing the right orchestration tool was critical for us because we had to ensure that the service was operationally efficient and cost-effective, provided high availability, had extensive features to support our business cases, and yet was easy to adapt for our end-users (data engineers). We evaluated and experimented among Amazon MWAA, Azkaban on Amazon EMR, and AWS Step Functions before project initiation.
The following benefits of Amazon MWAA convinced us to adopt it:
- AWS managed service – With Amazon MWAA, we don’t have to manage the underlying infrastructure for scalability and availability to maintain quality of service. The built-in autoscaling mechanism of Amazon MWAA automatically increases the number of Apache Airflow workers in response to running and queued tasks, and disposes of extra workers when there are no more tasks queued or running. The default environment is already built for high availability with multiple Airflow schedulers and workers, and the metadata database distributed across multiple Availability Zones. We also evaluated hosting open-source Airflow on our ZS infrastructure. However, due to infrastructure maintenance overhead and the high investment needed to make and maintain it at production grade, we decided to drop that option.
- Security – With Amazon MWAA, our data is secure by default because workloads run in our own isolated and secure cloud environment using Amazon Virtual Private Cloud (Amazon VPC), and data is automatically encrypted using AWS Key Management Service (AWS KMS). We can control role-based authentication and authorization for Apache Airflow’s user interface via AWS Identity and Access Management (IAM), providing users single sign-on (SSO) access for scheduling and viewing workflow runs.
- Compatibility and active community support – Amazon MWAA hosts the same open-source Apache Airflow version without any forks. The open-source community for Apache Airflow is very active with multiple commits, files changes, issue resolutions, and community advice.
- Language and connector support – The flow definitions for Apache Airflow are based on Python, which is easy for our engineers to adapt. An extensive list of features and connectors is available out of the box in Amazon MWAA, including connectors for Hive, Amazon EMR, Livy, and Kubernetes. We needed to run all our Data Hub jobs (ingestion, applying custom rules and quality checks, or exporting data to third-party systems) on Amazon EMR. The necessary Amazon EMR operators are already available as a part of the Amazon-provided package for Airflow (
apache-airflow-providers-amazon), which we could supplement rather than construct one from the ground up. - Cost – Cost was the most important aspect for us when adopting Amazon MWAA. Amazon MWAA is useful for those who are running thousands of tasks in the prod environment, which is why we decided to the make the Amazon MWAA environment multi-tenant such that the cost can be shared among clients. With our large Amazon MWAA environment, we only pay for what we use, with no minimum fees or upfront commitments. We estimated paying less than $1,000 per month, combined for our environment usage and additional worker instance pricing, yet achieve the scale of being able to run 200 concurrent tasks running 3 hours per day over 10 concurrent workers. This meant reduced operational costs and engineering overhead while meeting the on-demand monitoring needs of end-to-end data pipeline orchestration.
Solution overview
The following diagram illustrates the solution architecture.
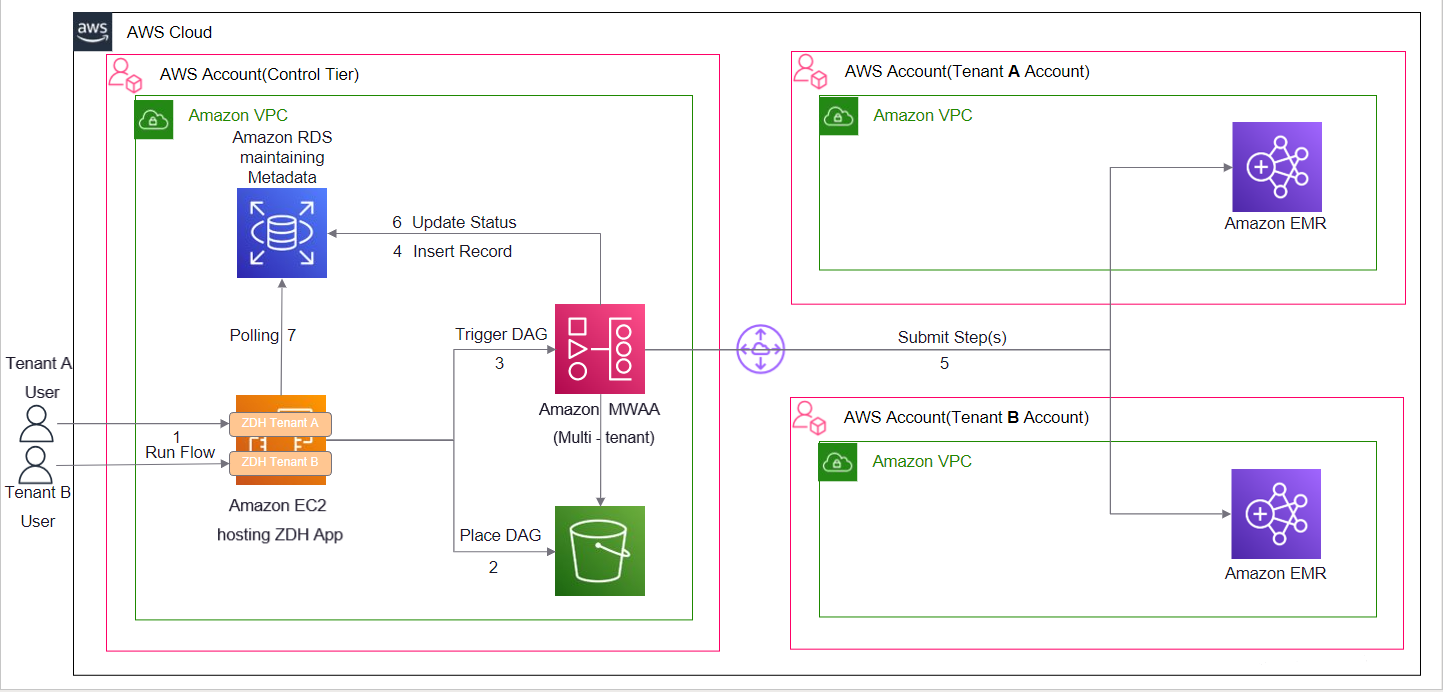
We have a common control tier account where we host our software as a service application (Data Hub) on Amazon Elastic Compute Cloud (Amazon EC2) instances. Each client has their own version of this application deployed on this shared infrastructure. Amazon MWAA is also hosted in the same common control tier account. The control tier account has connectivity with tenant-specific AWS accounts. This is to maintain strong physical isolation of client data by segregating the AWS accounts for each client. Each client-specific account hosts EMR clusters where data processing takes place. When a processing job is complete, data may reside on Amazon EMR (an HDFS cluster) or on Amazon Simple Storage Service (Amazon S3), an EMRFS cluster, depending on configuration. The DAG files generated by our Data Hub application contain metadata of the processes, and don’t contain any sensitive client information. When a job is submitted from Data Hub, the API request contains tenant-specific information needed to pull up the corresponding AWS connection details, which are stored as Airflow connection objects. These connection details are consumed by our custom implementation of Airflow EMR step operators (add and watch) to perform operations on the tenant EMR clusters.
Because the data orchestration capability is an application offering, the client teams create their processes on the Data Hub UI and don’t have access to the underlying Amazon MWAA environment.
The following screenshot shows how an end-user can configure Data Hub process on the application UI.

How Data Hub processes map to Amazon MWAA DAGs
Data Hub processes map to Amazon MWAA DAGs as follows:
- Each process in Data Hub corresponds to a DAG in Amazon MWAA, and each component is a task (denoted by Sn) that is submitted as a step on the client EMR clusters.
- The application generates the DAG file dynamically and updates it on the S3 bucket linked to the Amazon MWAA environment.
- Parsing dedicated structures representing a given process and submitting or tracking the Amazon EMR steps is abstracted from the end-user. Dynamic DAG generation is responsible for using the latest version of the underlying components and helps in managing the DAG schedule.
- Some Airflow tasks are created as a part of the DAG, which take care of interacting with the application APIs to ensure that the required metadata is captured in a separate Amazon Relational Database Service (Amazon RDS) database instance.
A user can trigger a given process to run from the Data Hub UI or can schedule it to run at a specified time. Because a single Amazon MWAA environment is responsible for the data orchestration needs of multiple clients, our DAG decode logic ensures that the correct EMR cluster ID and Airflow connection ID are picked up at runtime. The configs responsible for storing these details are placed and updated on the S3 buckets via an automated deployment pipeline. A dedicated connection ID is created per client in Airflow, which is then utilized in our custom implementation of EmrAddStepsOperator. The connection ID captures the Region and role ARN to be assumed to interact with the EMR cluster in the client account. These cross-account roles have access to limited resources in each client account, following the principle of least privilege.
Generating a DAG from a process defined on Data Hub UI
Our front-end application is built using Angular (version 11) and uses a third-party library that facilitates drag-and-drop of components from the left pane on a canvas. Components are stitched together with connections defining dependencies to form a process. This process is translated by our custom engine to generate a dynamic Airflow DAG. A sample DAG generated from the preceding example process defined on the UI looks like the following figure.
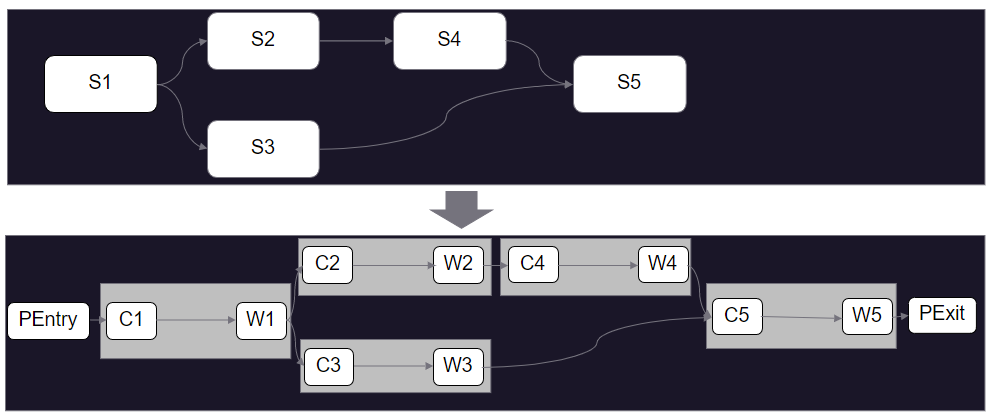
We wrap the DAG by PEntry and PExit Python operators, and for each of the components on the Data Hub UI, we create two tasks: Cn and Wn.
The relevant terms for this solution are as follows:
- PEntry – The Python operator used to insert an entry in the RDS database that the process run has started via API call.
- Cn – The ZS custom implementation of
EMRAddStepsOperatorused to submit a job (Data Hub component) on a running EMR cluster. This is followed by an API call to insert an entry in the database that the component job has started. - Wn – The custom implementation of Airflow Watcher (
EmrStepSensor), which checks the status of the step from our metadata database. - PExit – The Python operator used to update an entry in the RDS database (more of a finally block) via API call.
Lessons learned during the implementation
When implementing this solution, we learned the following:
- We faced challenges in being able to consistently predict when a DAG will be parsed and made available in the Airflow UI in Amazon MWAA after the DAG file is synced to the linked S3 bucket. Depending on how complex the DAG is, it could happen within seconds or several minutes. Due to the lack of availability of an API or AWS Command Line Interface (AWS CLI) command to ascertain this, we put in some blanket restrictions (delay) on user operations from our UI to overcome this limitation.
- Within Airflow, data pipelines are represented by DAGs, and these DAGs change over time as business needs evolve. A key challenge faced by Airflow users is looking at how a DAG was run in the past, and when it was replaced by a newer version of the DAG. This is because within Airflow (as of this writing), only the current (latest) version of the DAG is represented within the user interface, without any reference to prior versions of the DAG. To overcome this limitation, we implemented a backend way of generating a DAG from the available metadata, and use it to version control over runs.
- Airflow CLI commands when invoked in DAGs always return an HTTP 200 response. You can’t solely rely on the HTTP response code to ascertain the status of commands. We applied additional parsing logic (particularly to analyze the errors on failure) to determine the true status of commands.
- Airflow doesn’t have a command to gracefully stop a DAG that is currently running. You can stop a DAG (unmark as running) and clear the task’s state or even delete it in the UI. The actual running tasks in the executor won’t stop, but might be stopped if the executor realizes that it’s not in the database anymore.
Conclusion
Amazon MWAA sets up Apache Airflow for you using the same Apache Airflow user interface and open-source code. With Amazon MWAA, you can use Airflow and Python to create workflows without having to manage the underlying infrastructure for scalability, availability, and security. Amazon MWAA automatically scales its workflow run capacity to meet your needs, and is integrated with AWS security services to help provide you with fast and secure access to your data. In this post, we discussed how you can build a bridge tenancy isolation model with a central Amazon MWAA orchestrating task against independent infrastructure stacks in dedicated accounts deployed for each of your tenants. Through a custom UI, you can enable self-service workflow runs via Airflow dynamic DAGs using the power and flexibility of Python. This enables you to achieve economies of scale and operational efficiency while meeting your regulatory, security, and cost considerations.
About the Authors
 Manish Mehra is a Software Architect, working with the SD group in ZS. He has more than 11 years of experience working in banking, gaming, and life science domains. He is currently looking into the architecture of the Data & Analytics product category of the ZAIDYN Platform. He has expertise in full-stack application development and building robust, scalable, enterprise-grade big data applications.
Manish Mehra is a Software Architect, working with the SD group in ZS. He has more than 11 years of experience working in banking, gaming, and life science domains. He is currently looking into the architecture of the Data & Analytics product category of the ZAIDYN Platform. He has expertise in full-stack application development and building robust, scalable, enterprise-grade big data applications.
 Anirudh Vohra is a Director of Cloud Architecture, working within the Cloud Center of Excellence space at ZS. He is passionate about being a developer advocate for internal engineering teams, also designing and building cloud platforms and abstractions to empower developers and troubleshoot complex systems.
Anirudh Vohra is a Director of Cloud Architecture, working within the Cloud Center of Excellence space at ZS. He is passionate about being a developer advocate for internal engineering teams, also designing and building cloud platforms and abstractions to empower developers and troubleshoot complex systems.
 Abhishek I S is Associate Cloud Architect at ZS Associates working within the Cloud Centre of Excellence space. He has diverse experience ranging from application development to cloud engineering. Currently, he is primarily focusing on architecture design and automation for the cloud-native solutions of various ZS products.
Abhishek I S is Associate Cloud Architect at ZS Associates working within the Cloud Centre of Excellence space. He has diverse experience ranging from application development to cloud engineering. Currently, he is primarily focusing on architecture design and automation for the cloud-native solutions of various ZS products.
 Sidrah Sayyad is an Associate Software Architect at ZS working within the Software Development (SD) group. She has 9 years of experience, which includes working on identity management, infrastructure management, and ETL applications. She is passionate about coding and helps architect and build applications to achieve business outcomes.
Sidrah Sayyad is an Associate Software Architect at ZS working within the Software Development (SD) group. She has 9 years of experience, which includes working on identity management, infrastructure management, and ETL applications. She is passionate about coding and helps architect and build applications to achieve business outcomes.
 Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab was closely involved with the engagement with ZS, providing architectural guidance as well as helping the team overcome technical challenges during the implementation.
Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab was closely involved with the engagement with ZS, providing architectural guidance as well as helping the team overcome technical challenges during the implementation.