AWS Big Data Blog
Introduction to Amazon QuickSight ML Insights
Amazon QuickSight was launched in November 2016 as a fast, cloud-powered business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from a variety of data sources. In 2018, ML Insights for QuickSight (Enterprise Edition) was announced to add machine learning (ML)-powered forecasting and anomaly detection with a few clicks. These insights are automatically generated as suggested insights, and you can also add custom insights to your analysis. Because they’re written out in narrative format, they’re easily consumable by any non-technical user and are a great way to increase adoption of your dashboards. Let’s dive deeper on how these insights are built and how to correctly set up your data to maximize the Suggested Insights feature.
What are ML Insights?
QuickSight uses ML to help uncover hidden insights and trends in your data. It does that by using an ML model that over time and with an increasing volume of data being fed into QuickSight, continually learns and improves its abilities to provide three key features (as of this writing):
- ML-powered anomaly detection – Detect outliers that show significant variance from the dataset. This can help identify significant changes in your business metrics such has low-performing stores or products, or top selling items.
- ML-powered forecasting – Detect trends and seasonality to forecast based on historical data. This can help project sales, orders, website traffic, and more.
- Autonarratives – Embed narratives in your dashboard to tell the story of your data in plain language. This can help convey a shared understanding of the data within your organization. You can use either the suggested autonarrative or you can customize the computations and language to meet your organization’s unique requirements.
How does the ML model work?
QuickSight uses a built-in version of the Random Cut Forest (RCF) algorithm. This is a special type of Random Forest (RF) algorithm, a widely used and successful technique in ML. It takes a set of random data points, cuts them down to the same number of points, and then builds a collection of models. In contrast, a model corresponds to a decision tree—thereby the name “forest.” Because RFs can’t be easily updated in an incremental manner, RCFs were invented with variables in tree construction that were designed to allow incremental updates.
The key takeaway is that RCF is great for finding anomalies and building forecasts. This algorithm is good at finding data points that are outliers or finding trends and patterns to forecast future values.
One important thing to know about ML models is that each model is good at a certain set of predictive activities, but no one model is good for all activities.
Now that you understand what the RCF model is good at, namely anomaly detection and forecasting, you need to make sure the data meets certain requirements, so let’s walk through those steps.
Best practices for setting up data
To maximize the RCF model’s efficiency, the data that is being imported needs to contain certain properties:
- At least one metric – Whatever you’re measuring (sold units, orders, and so on).
- At least one dimension – The category or slice by which you look at the metric (product category, industry, customer type, and so on).
- Data volumes – Your dataset requirements depend on your objective:
- Anomaly detection – Requires at least 15 data points. For example, if you have
Bicyclesas a product category and want to detect anomalies at a daily level, you need at least 15 days of transactions (you could have multiple rows for multiple transactions in a given day) forBicyclesin the dataset. - Forecasting – This works best with a large dataset simply because the more history you have, the better the model can extract patterns and trends and generate future probable values. If you have daily aggregates, you need at least 38 days of data.
- Anomaly detection – Requires at least 15 data points. For example, if you have
- At least one date column – If we want to analyze anomalies or forecasts in the dataset.
QuickSight supports a wide variety of connections, like Amazon Simple Storage Service (Amazon S3), Amazon Athena, and Apache Spark. For more information about supported connections and some connection examples, refer to Amazon QuickSight Connection examples.
Get started with Suggested Insights
Let’s use a sample dataset and walk through an example of how to use the Suggested Insights feature.
To get started, let’s download a sample dataset from the public domain. For this post, we use House Sales in King County, USA. You need to have a Kaggle account to download the resource.
- Download and unzip the file.
If you inspect the CVS file, you will notice it has the right grain (date), metrics (price, bedrooms) and categories (zipcode, waterfront).
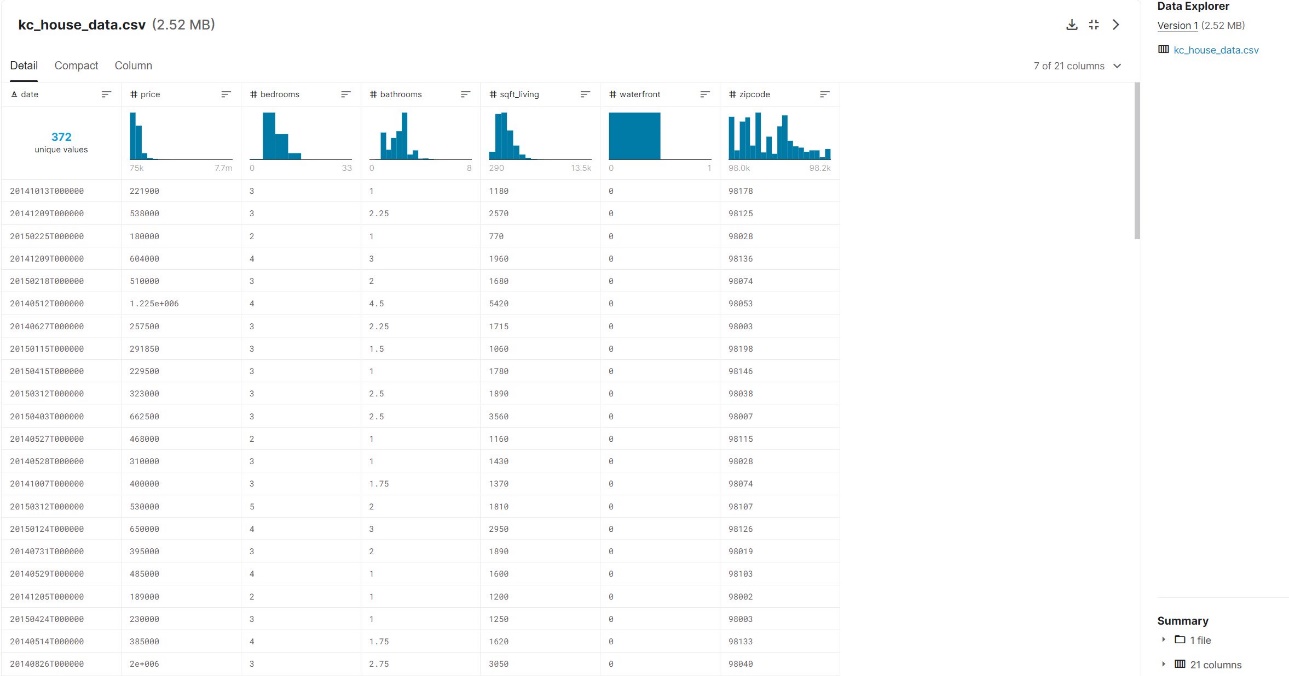
Depending on what your analysis needs are, even bedrooms could be a category by which you analyze price. So your metrics and categories ultimately depend on your analysis goals.
- Log in to your QuickSight account or sign up for a QuickSight Enterprise Edition account to use ML Insights.
We need to create a dataset first before we can create a QuickSight analysis.
- Choose New dataset.
- Choose Upload a file.
- Choose the unzipped CSV file.
- In the pop-up window, confirm the file upload settings, then choose Edit settings and prepare data.
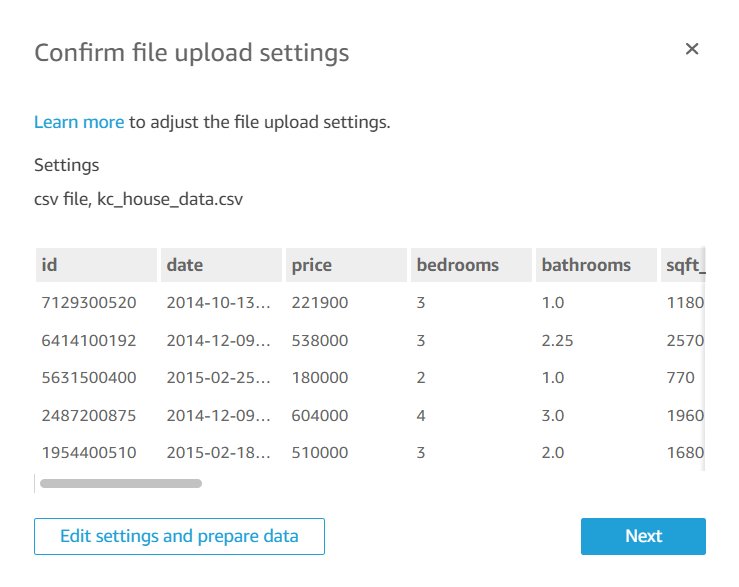
You’re redirected to the data preparation editor. This is one of the most important yet overlooked functions in QuickSight.

This editor allows you to review your imported fields and their data types, specify if the field will be used as a dimension or measure, along with many other important data import functions. For production datasets, you should spend time reviewing how the dataset has been set up here.
For our sample CSV file, it’s imported into a QuickSight SPICE by default. SPICE is an in-memory engine for fast querying of imported data. For more details, see Importing data into SPICE.
- Choose Save & publish to start importing the CSV file into the SPICE engine.
The default dataset name is the file name that was imported, so in our case it’s kc_house_data. You can choose the dataset on the Datasets page to see the import stats for the dataset.
- Choose Create analysis to start creating your QuickSight analysis.

The analysis editor page starts by showing a blank Sheet 1 on your workspace. On the top right, your dataset’s import stats are shown again (this becomes important when importing or refreshing large datasets because the import job might still be in progress).
Let’s start by creating our first visual. The default visual type is AutoGraph, which will try to pick the best visual type based on the fields being selected.
- Choose the
datefield.
The visual changes to Count of Records by Date, with the date aggregation set to Day.
- To change the aggregation to monthly, choose the down arrow next to date on the X axis.

- Choose the
pricefield.
The AutoGraph detects that the date is a dimension (blue color) and the price is a measure (green color) because these were set up like that in the dataset editor screen (I mentioned earlier how important the data preparation editor was).
Because these fields are already set up as dimensions and measures, the AutoGraph automatically changes to Sum of Price by Date.
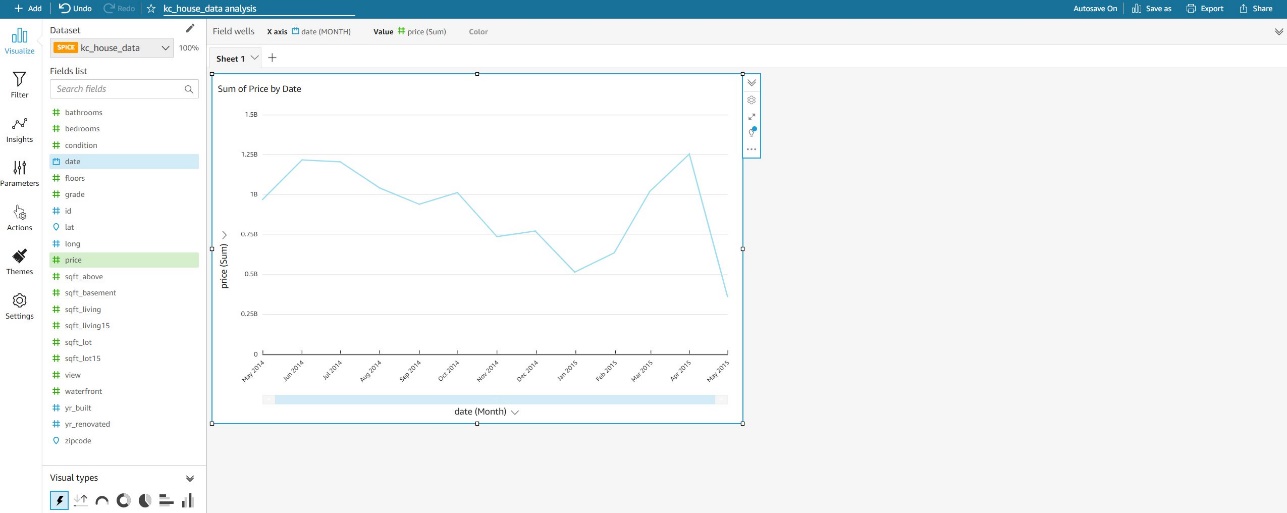
This visualization isn’t very helpful. What we’re really looking for is the average price per month.
- For Field wells, choose price for Value and change the aggregate to Average.
We now have a nice visual that shows us the average sale price of homes in Kings County by month.
Now comes the fun part—ML Insights!
- In the navigation pane, choose Insights.
Voila! QuickSight has already run the RCF model along with other statistical computations and has generated insights that are ready to be added.

These suggested insights change based on the type of visual and data that is currently in the visual. We look at how suggested insights change later in this post.
Two immediately useful insights are Highest Month and Lowest Month.
Hover over the Highest Month insight and choose the plus sign to add it to the current Sheet 1.
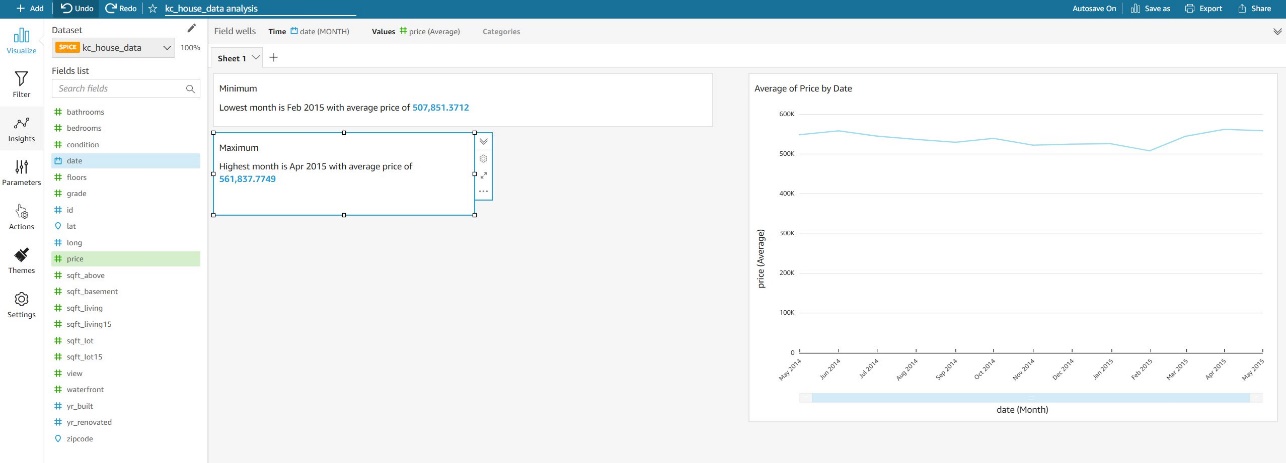
I can start rearranging insights and visuals and format the price field to give my current layout a more polished look.
- For this post, change the format of the
pricefield to 1,2345 to remove decimals. - You can also add titles for the insights and rename the X axis label date to Aggregate.
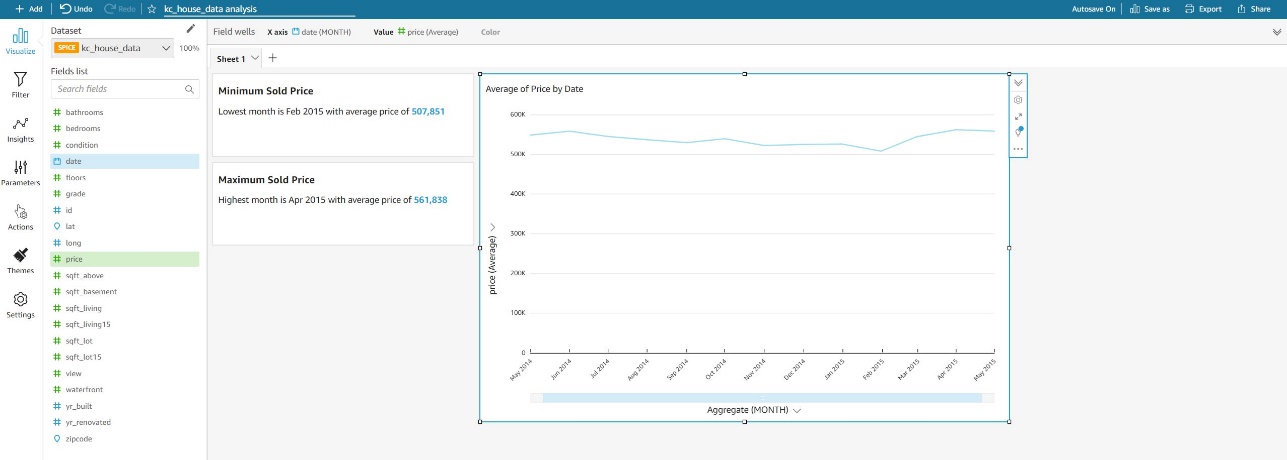
- To add another sheet, choose the plus sign next to Sheet 1.
By default, we start again with an AutoGraph visual.
- Under Visual types¸ choose the vertical bar chart.
- Choose the
priceandzipcodefields. - Change the aggregation of price from Sum to Average.
- Choose Insights in the navigation pane.

Suggested Insights now displays a completely different set of data highlights compared to Sheet 1.
Although the vertical bar chart may already tell you the top three and bottom three zip codes, Suggested Insights already recognized the type of analysis and selected the best insights to display.
Although you might eventually build a visual to portray the intended story, Suggested Insights speeds up the process of showcasing the highlights in your data and adding them to your worksheet to quickly give the reader the most important insights from your visuals.
Anomaly detection
An anomaly in QuickSight is described a data point that fall outside an overall pattern of distribution. ML-powered anomaly detection in QuickSight enables you to identify the causations and correlations to make data-driven decisions.
We already talked about data preparation for anomaly detection earlier. QuickSight already ran the RCF model during data import. As soon as a visual is added, QuickSight notifies you on the visual if it has detected an “Anomaly Insight.” This part of Suggested Insights. You can choose Setup anomaly detection to add this to your sheet.
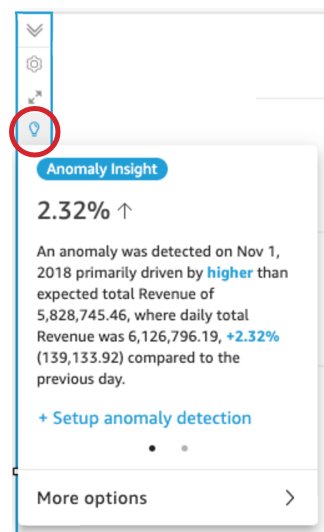
You can also manually add an ML insight to detect anomalies.
- Let’s go back to Sheet 1 with the line chart displayed.
- When you choose the first suggested insight, it starts creating a widget for anomaly detection.

You can add up to five dimensions fields (not calculated fields, unless they were created in the data prep screen). QuickSight splits the metrics using the fields in the Categories section. We use the date field (our time dimension), price (our metric), and yr_built (our category) to create an anomaly detection insight. The question we are trying to answer is “Were there any monthly outliers in price based on the year built?”
- Choose Get started to set up anomaly detection.

- For Combinations to be analyzed, choose your field combinations.
Choosing Exact means that the date and price are analyzed against the yr_built dimension. You can also choose Hierarchical or All. These latter options become relevant when you choose multiple dimensions in the Categories list. For more information about these options, refer to Adding an ML insight to detect outliers and key drivers.
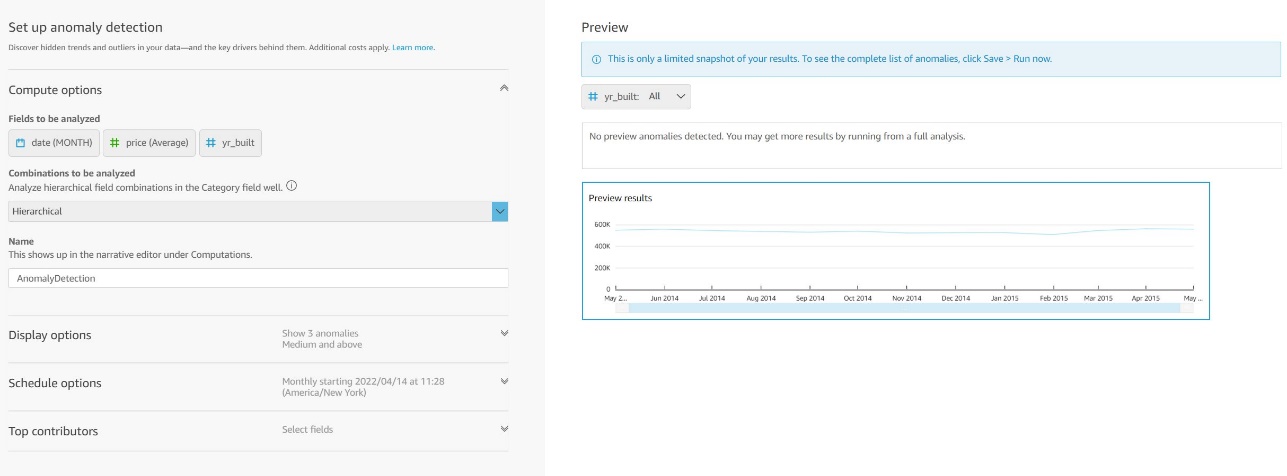
- Choose Save to return to Sheet 1.
Our widget is configured at this point.
- Choose Run now to start analyzing the data for anomalies.
Based on the volume of data and the number of data points in the analysis, it may take a while to run the anomaly detection.
Keep in mind that at least 15 data points are needed to run an anomaly, but then you can change the aggregation of a field to have a zoom-out view and therefore view anomalies at a higher level.
For example, if you choose the date field and change Aggregate to Monthly, you get the top anomalies at the monthly level.
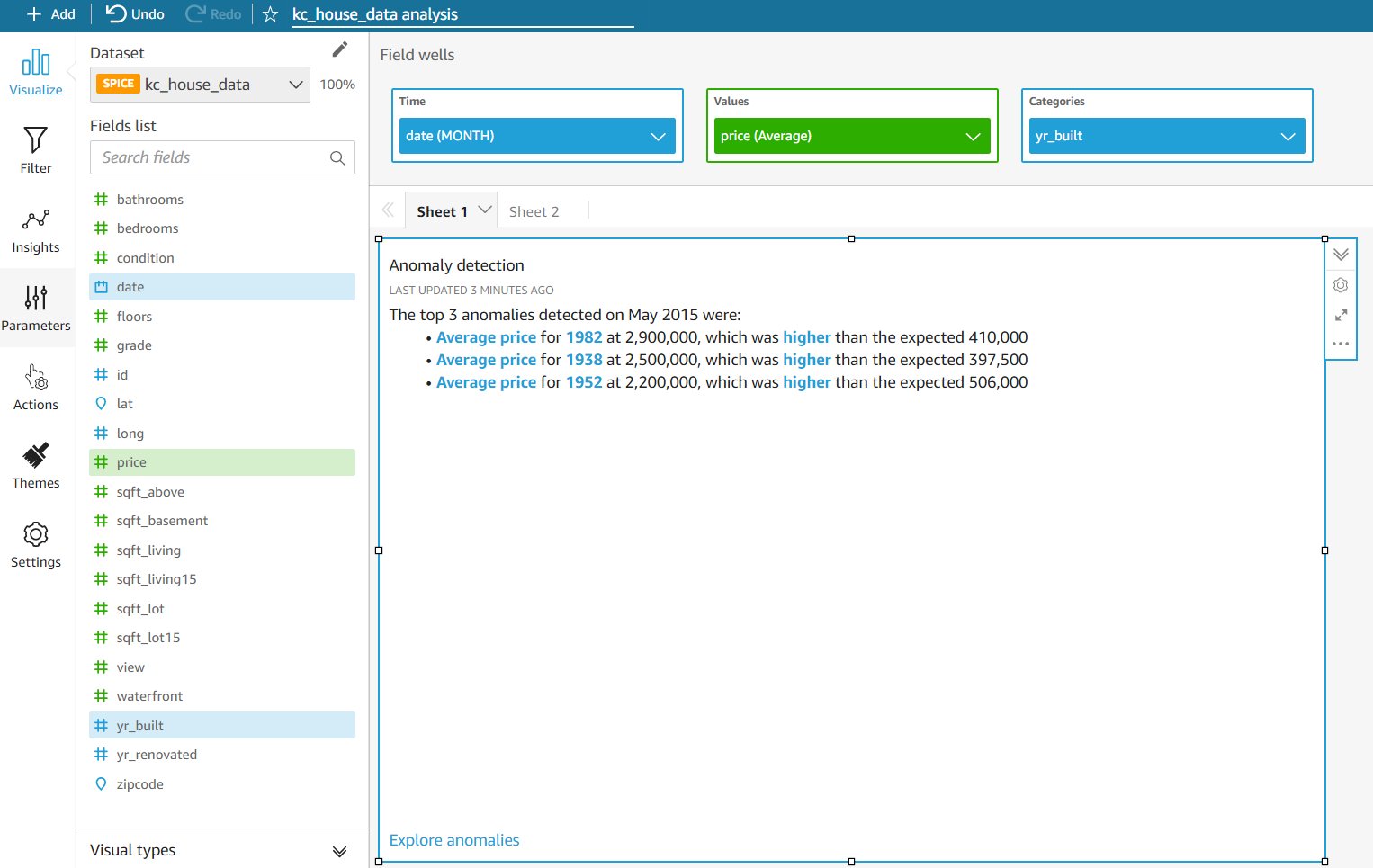
In our test case, QuickSight identified a top anomaly. This is a great widget that immediately draws the reader to highlights in data that are outliers and might require further investigation.
Forecast
With ML-powered forecasting, you can forecast your key business metrics in QuickSight easily. The ML algorithm in QuickSight is designed to handle complex real-world scenarios. Not only does QuickSight provide the capability to create forecasts, it also provides Forecast as a Suggested Insight.
- Going back to Sheet 1, choose the line chart and expand Insights.
At the bottom you will see a suggested forecast insight. Forecast insights, along with all other suggested insights, are dynamic in the sense that when your data updates or when a user applies filters, the values in the insight will update immediately. Once you add this to your sheet you can even customize how many periods in the future you want the insight to display for the forecast by editing the Narrative and then editing the forecast Calculation.
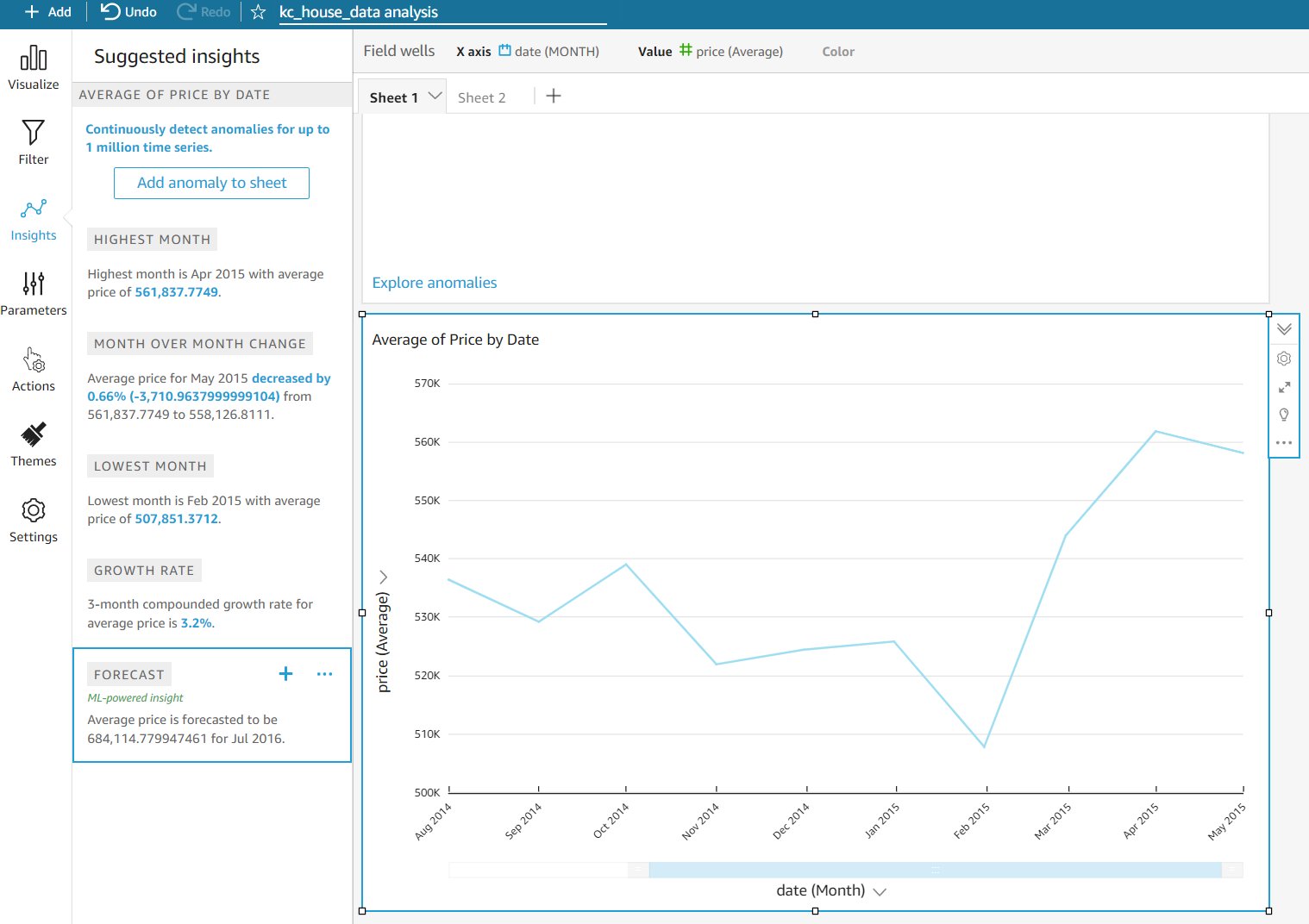
What if we wanted to customize the price forecasting on this line chart and add it in the visual?
- Choose the options menu (three dots) at the top right of the visual and choose Add forecast.

- For Periods forward, enter
6.
That is the time interval selected for the visual.
- Set Prediction interval to 70.
This is the amount of interval between data points. It causes the forecast to either go wider or narrower. A wider interval means wider gaps between data points, which means the net change is higher, and vice versa.
- Leave Seasonality set to Automatic.
Seasonality takes into account complex seasonal trends in your data. You can experiment with both settings to see how it affects the forecast. For our scenario, because house sales are seasonal, we chose Automatic.
- Choose Apply.
With just a few clicks, we have added a forecast to our visual, as shown in the following screenshot. The orange shaded area represents the upper and lower bound of the forecasted price.
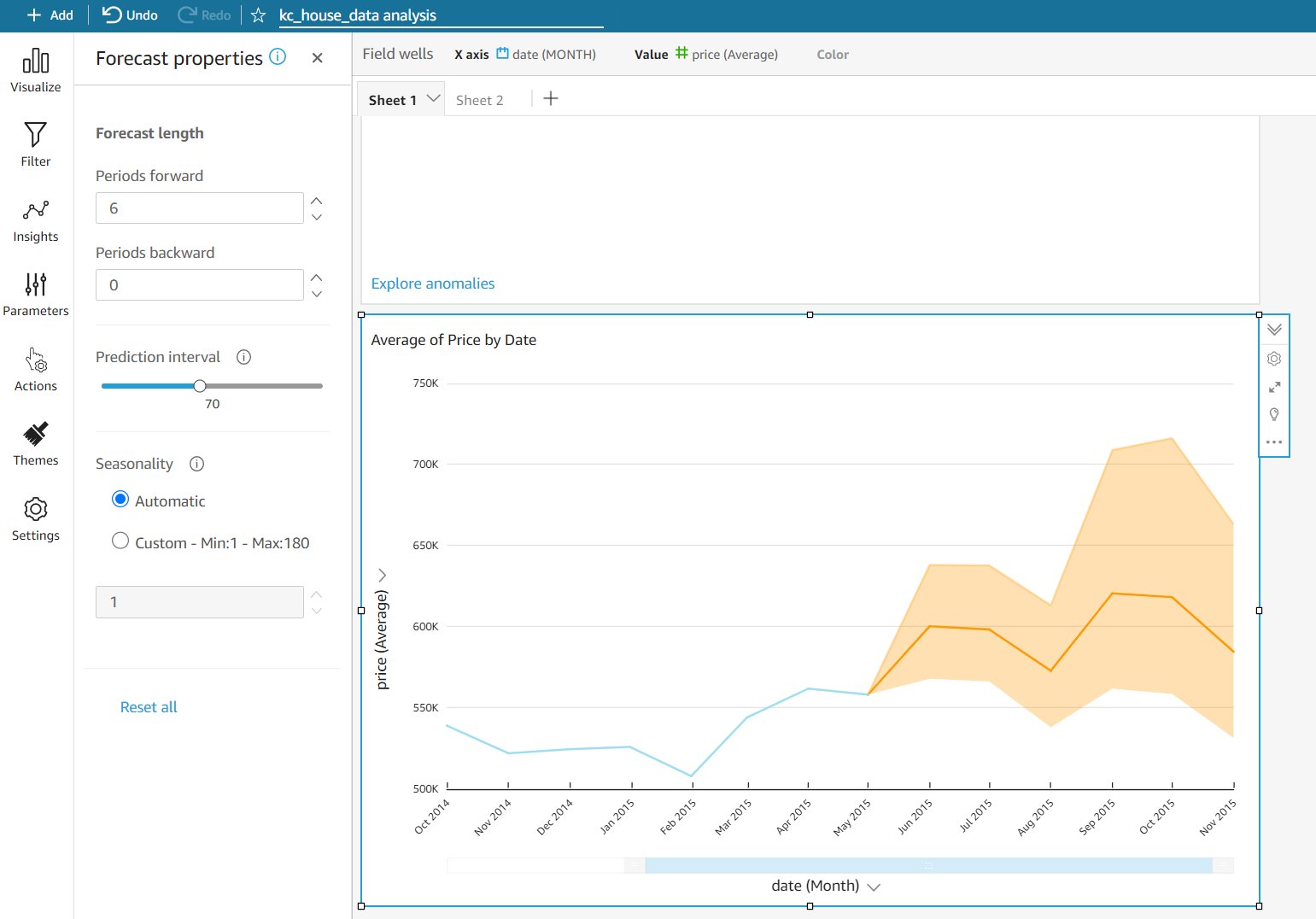
This is another great way to add intelligence to your data and quickly let analysts focus on key data points and trends.
Conclusion
The Suggested Insights feature in QuickSight allows you to speed up the discovery and highlighting of key data elements. You can find insights in your data faster, and because they’re written out in narrative format, they’re very easy for non-technical users to quickly gain insight into the most interesting trends in the data with no ML training needed.
For more details on QuickSight ML Insights, refer to the QuickSight documentation or interact with the QuickSight Community.
As always, AWS is customer obsessed and we are ready to help with any specific questions.
About the Author
 Rashid Sajjad is a Partner Management Solutions Architect focused on Big Data & Analytics with Amazon Web Services. He works with APN Partners to help develop their Migration, Data & Analytics and AI/ML Practices with enterprise, mission critical solutions for their end customers.r
Rashid Sajjad is a Partner Management Solutions Architect focused on Big Data & Analytics with Amazon Web Services. He works with APN Partners to help develop their Migration, Data & Analytics and AI/ML Practices with enterprise, mission critical solutions for their end customers.r