AWS Big Data Blog
Simplify analytics on Amazon Redshift using PIVOT and UNPIVOT
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Many customers look to build their data warehouse on Amazon Redshift, and they have many requirements where they want to convert data from row level to column level and vice versa. Amazon Redshift now natively supports PIVOT and UNPIVOT SQL operators with built-in optimizations that you can use for data modeling, data analysis, and data presentation. You can apply PIVOT and UNPIVOT to tables, sub-queries, and common table expressions (CTEs). PIVOT supports the COUNT, SUM, MIN, MAX, and AVG aggregate functions.
You can use PIVOT tables as a statistics tool that summarizes and reorganizes selected columns and rows of data from a dataset. The following are a few scenarios where this can be useful:
- Group the values by at least one column
- Convert the unique values of a selected column into new column names
- Use in combination with aggregate functions to derive complex reports
- Filter specific values in rows and convert them into columns or vice versa
- Use these operators to generate a multidimensional reporting
In this post, we discuss the benefits of PIVOT and UNPIVOT, and how you can use them to simplify your analytics in Amazon Redshift.
PIVOT overview
The following code illustrates the PIVOT syntax:
The syntax contains the following parameters:
- <get_source_data> – The SELECT query that gets the data from the source table
- <alias_source_query> – The alias for the source query that gets the data
- <agg_func> – The aggregate function to apply
- <agg_col> – The column to aggregate
- <pivot_col> – The column whose value is pivoted
- <pivot_value_n> – A list of pivot column values separated by commas
- <alias_pivot> – The alias for the pivot table
- <optional ORDER BY clause> – An optional parameter to apply an ORDER BY clause on the result set
The following diagram illustrates how PIVOT works.
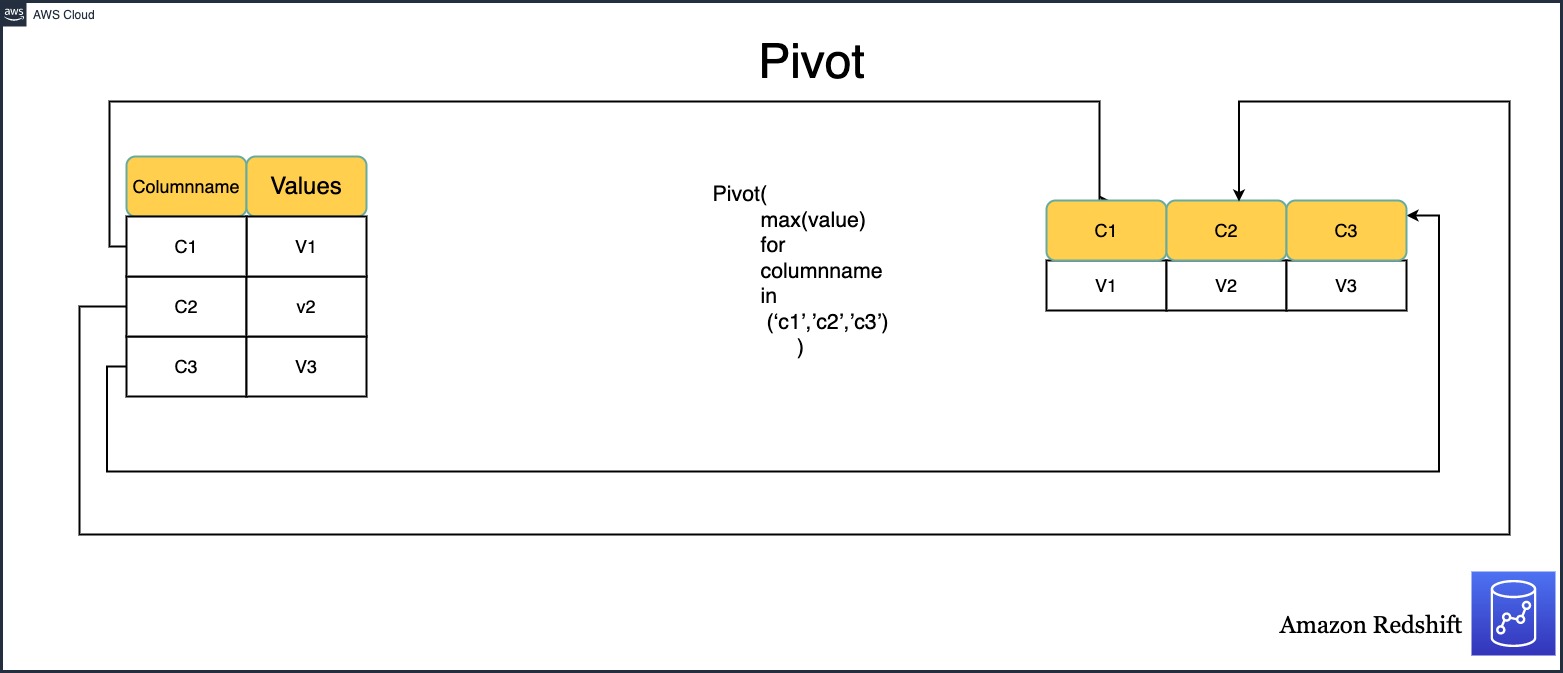
PIVOT instead of CASE statements
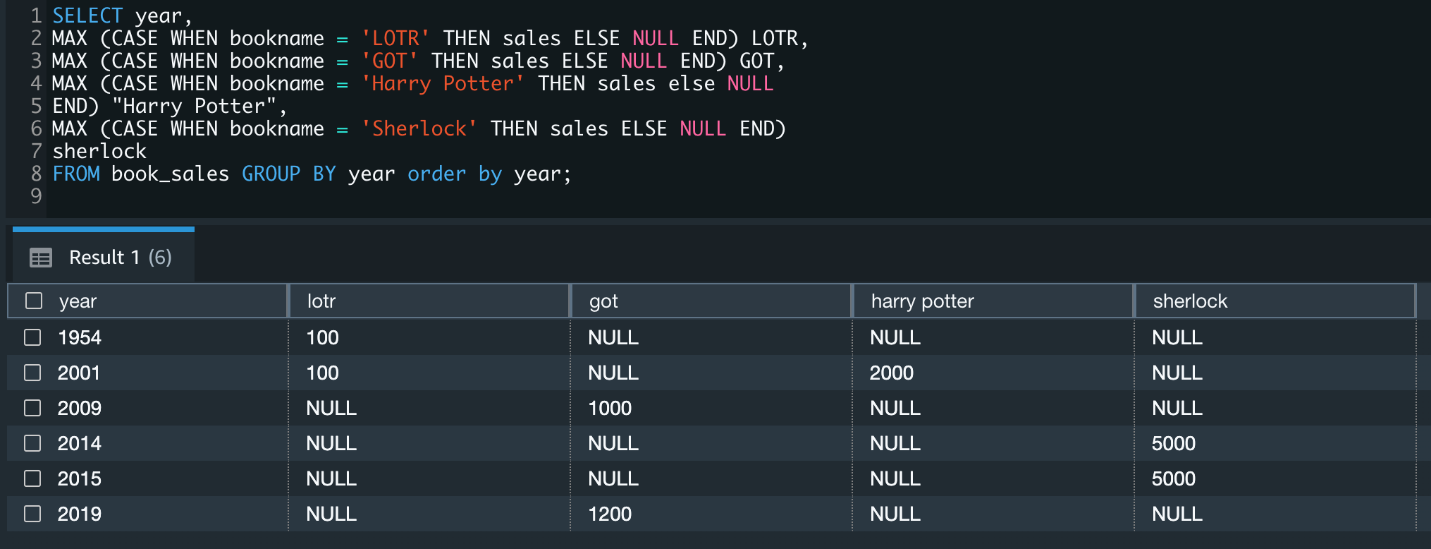
Let’s look at an example of analyzing data from a different perspective than how it’s stored in the table. In the following example, book sales data is stored by year for each book. We want to look at the book_sales dataset by year and analyze if there were any books sold or not, and if sold, how many books were sold for each title. The following screenshot shows our query.

The following screenshot shows our output.

Previously, you had to derive your desired results set using a CASE statement. This requires you to add an individual CASE statement with the column name for each title, as shown in the following code:
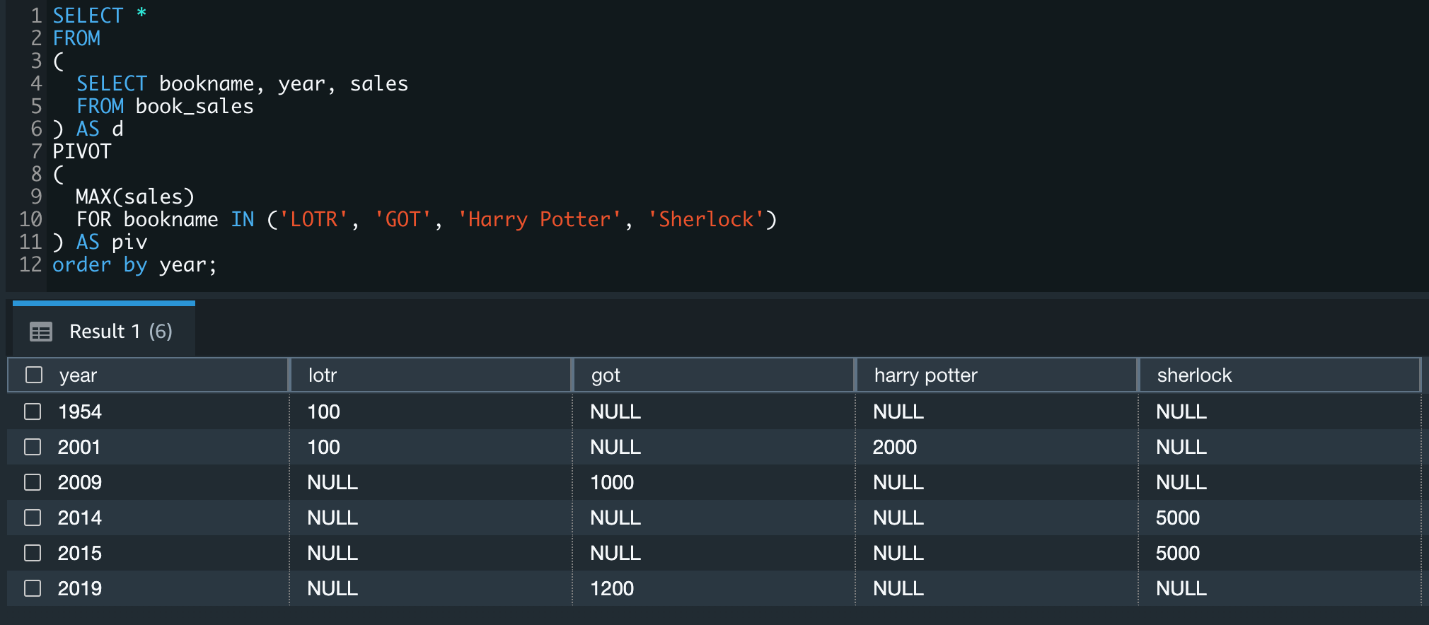
With the out-of-the-box PIVOT operator, you can use a simpler SQL statement to achieve the same results:
UNPIVOT overview
The following code illustrates the UNPIVOT syntax:
The code uses the following parameters:
- <get_source_data> – The SELECT query that gets the data from the source table.
- <alias_source_query> – The alias for the source query that gets the data.
- <optional INCLUDE NULLS> – An optional parameter to include NULL values in the result set. By default, NULLs in input columns aren’t inserted as result rows.
- <value_col> – The name assigned to the generated column that contains the row values from the column list.
- <name_col> – The name assigned to the generated column that contains the column names from the column list.
- <column_name_n> – The column names from the source table or subquery to populate
value_colandname_col. - <alias_unpivot> – The alias for the unpivot table.
- <optional ORDER BY clause> – An optional parameter to apply an ORDER BY clause on the result set.
The following diagram illustrates how UNPIVOT works.

UNPIVOT instead of UNION ALL queries
Let’s look at the following example query with book_sales_pivot.

We get the following output.
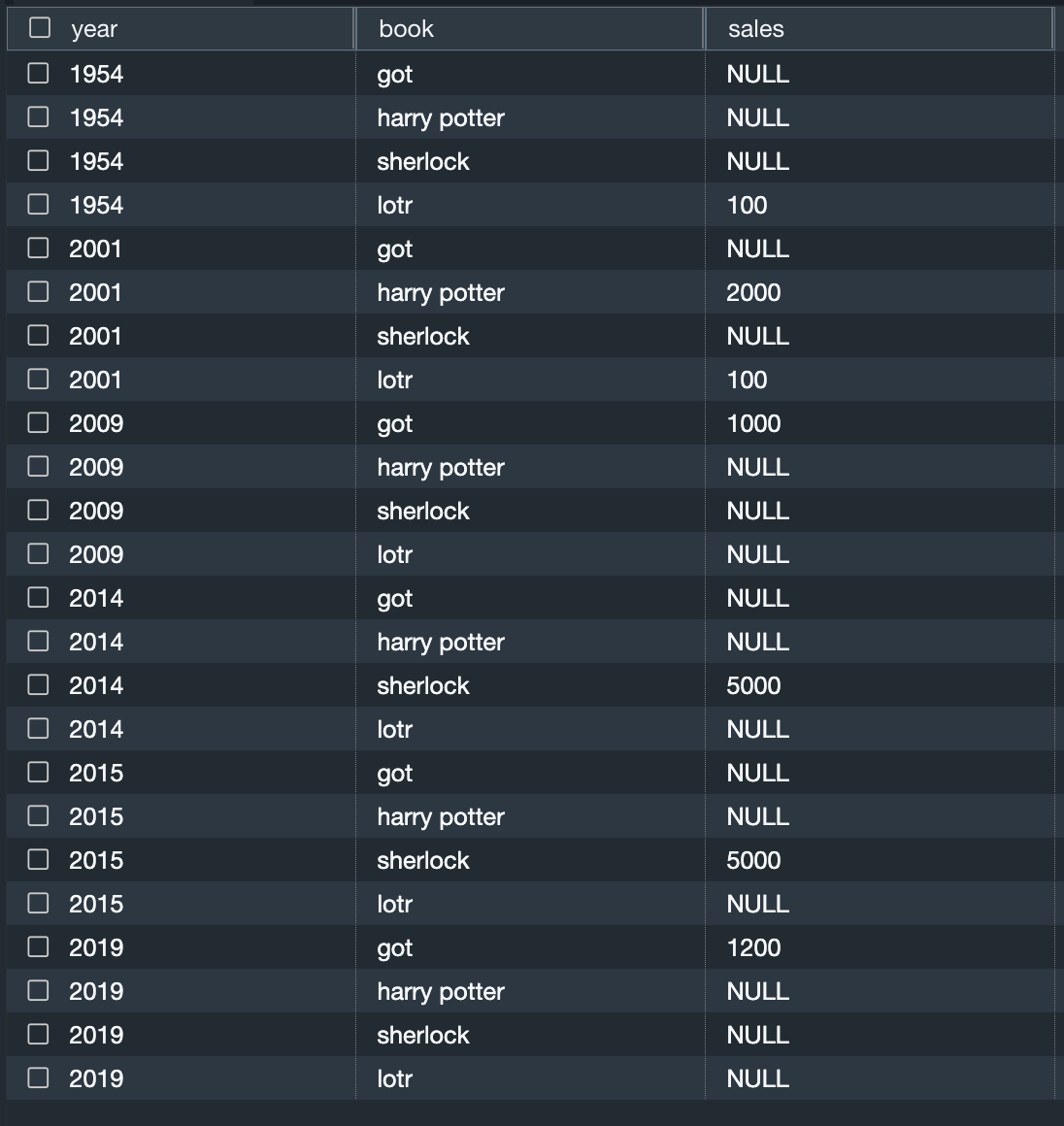
Previously, you had to derive this result set using UNION ALL, which resulted in a long and complex query form, as shown in the following code:

With UNPIVOT, you can use the following simplified query:

UNPIVOT is straightforward compared to UNION ALL. You can further clean this output by excluding NULL values from the result set. For example, you can exclude book titles from the result set if there were no sales in a year:

By default, NULL values in the input column are skipped and don’t yield a result row.
Now that we understand the basic interface and usability, let’s dive into a few complex use cases.
Dynamic PIVOT tables using stored procedures
The query of PIVOT is static, meaning that you have to enter a list of PIVOT column names manually. In some scenarios, you may not want to manually use your PIVOT values because your data keeps changing, and it gets difficult to maintain the list of values and update the PIVOT query manually.
To handle these scenarios, you can take advantage of the dynamic PIVOT stored procedure:
PIVOT example using CTEs
You can use PIVOT as part of a CTE (Common Table Expression). See the following example code:
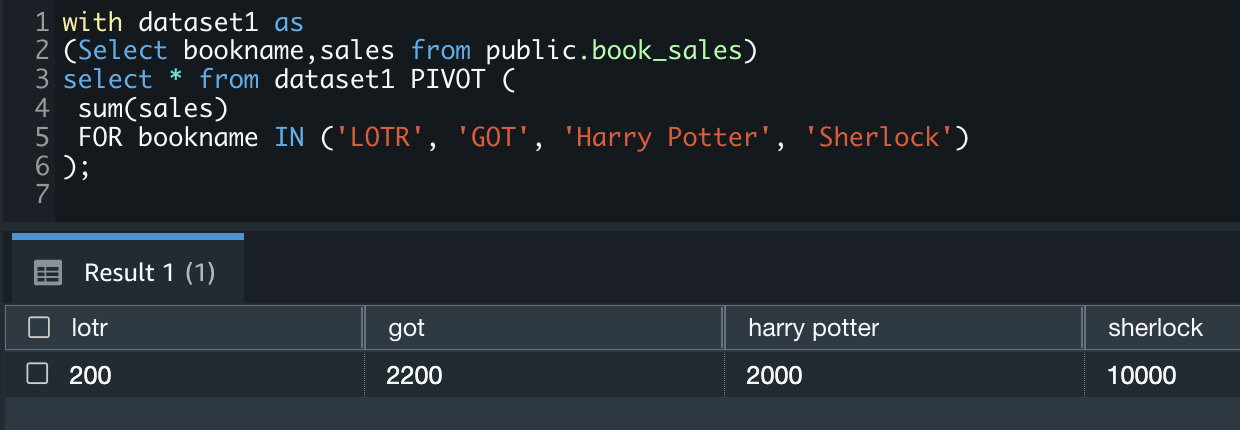
Multiple aggregations for PIVOT
The following code illustrates multiple aggregations for PIVOT:

Summary
Although PIVOT and UNPIVOT aren’t entirely new paradigms of SQL language, the new native support for these operators in Amazon Redshift can help you achieve many robust use cases without the hassle of using alternate operators. In this post, we explored a few ways in which the new operators may come in handy.
Adapt PIVOT and UNPIVOT into your workstreams now and work with us as we evolve the feature, incorporating more complex option sets. Please feel free to reach out to us if you need further help to achieve your custom use cases.
About the authors
 Ashish Agrawal is currently Sr. Technical Product Manager with Amazon Redshift building cloud-based data warehouse and analytics cloud service. Ashish has over 24 years of experience in IT. Ashish has expertise in data warehouse, data lake, Platform as a Service. Ashish is speaker at worldwide technical conferences.
Ashish Agrawal is currently Sr. Technical Product Manager with Amazon Redshift building cloud-based data warehouse and analytics cloud service. Ashish has over 24 years of experience in IT. Ashish has expertise in data warehouse, data lake, Platform as a Service. Ashish is speaker at worldwide technical conferences.
 Sai Teja Boddapati is a Database Engineer based out of Seattle. He works on solving complex database problems to contribute to building the most user friendly data warehouse available. In his spare time, he loves travelling, playing games and watching movies & documentaries.
Sai Teja Boddapati is a Database Engineer based out of Seattle. He works on solving complex database problems to contribute to building the most user friendly data warehouse available. In his spare time, he loves travelling, playing games and watching movies & documentaries.
 Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
 Eesha Kumar is an Analytics Solutions Architect with AWS. He works with customers to realize business value of data by helping them building solutions leveraging AWS platform and tools.
Eesha Kumar is an Analytics Solutions Architect with AWS. He works with customers to realize business value of data by helping them building solutions leveraging AWS platform and tools.