AWS Big Data Blog
Tag: Apache Iceberg
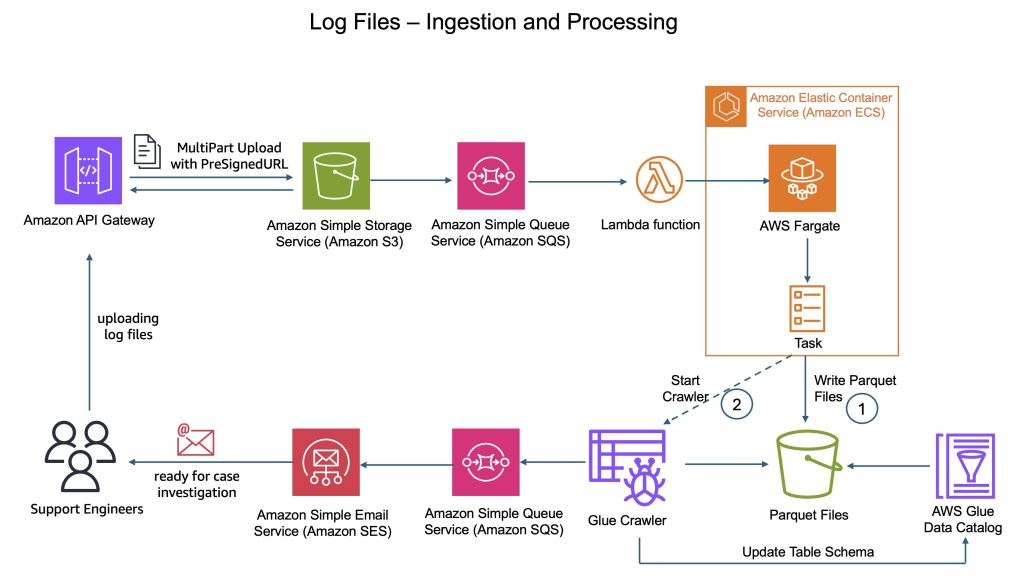
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.

How Ancestry optimizes a 100-billion-row Iceberg table
This is a guest post by Thomas Cardenas, Staff Software Engineer at Ancestry, in partnership with AWS. Ancestry, the global leader in family history and consumer genomics, uses family trees, historical records, and DNA to help people on their journeys of personal discovery. Ancestry has the largest collection of family history records, consisting of 40 […]

The Amazon SageMaker lakehouse architecture now automates optimization configuration of Apache Iceberg tables on Amazon S3
The Amazon SageMaker lakehouse architecture now automates optimization of Iceberg tables stored in Amazon S3 with catalog-level configuration, optimizing storage in your Iceberg tables and improving query performance. This post demonstrates an end-to-end flow to enable catalog level table optimization setting.

Configure cross-account access of Amazon SageMaker Lakehouse multi-catalog tables using AWS Glue 5.0 Spark
In this post, we show you how to share an Amazon Redshift table and Amazon S3 based Iceberg table from the account that owns the data to another account that consumes the data. In the recipient account, we run a join query on the shared data lake and data warehouse tables using Spark in AWS Glue 5.0. We walk you through the complete cross-account setup and provide the Spark configuration in a Python notebook.

Accelerate lightweight analytics using PyIceberg with AWS Lambda and an AWS Glue Iceberg REST endpoint
In this post, we demonstrate how PyIceberg, integrated with the AWS Glue Data Catalog and AWS Lambda, provides a lightweight approach to harness Iceberg’s powerful features through intuitive Python interfaces. We show how this integration enables teams to start working with Iceberg tables with minimal setup and infrastructure dependencies.

Manage concurrent write conflicts in Apache Iceberg on the AWS Glue Data Catalog
This post demonstrates how to implement reliable concurrent write handling mechanisms in Iceberg tables. We will explore Iceberg’s concurrency model, examine common conflict scenarios, and provide practical implementation patterns of both automatic retry mechanisms and situations requiring custom conflict resolution logic for building resilient data pipelines. We will also cover the pattern with automatic compaction through AWS Glue Data Catalog table optimization.

Build a high-performance quant research platform with Apache Iceberg
In our previous post Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg, we showed how to use Apache Iceberg in the context of strategy backtesting. In this post, we focus on data management implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Our experiments are based on real-world historical full order book data, provided by our partner CryptoStruct, and compare the trade-offs between these choices, focusing on performance, cost, and quant developer productivity.

Accelerate queries on Apache Iceberg tables through AWS Glue auto compaction
In this post, we explore new features of the AWS Glue Data Catalog, which now supports improved automatic compaction of Iceberg tables for streaming data, making it straightforward for you to keep your transactional data lakes consistently performant. Enabling automatic compaction on Iceberg tables reduces metadata overhead on your Iceberg tables and improves query performance

Build Write-Audit-Publish pattern with Apache Iceberg branching and AWS Glue Data Quality
This post explores robust strategies for maintaining data quality when ingesting data into Apache Iceberg tables using AWS Glue Data Quality and Iceberg branches. We discuss two common strategies to verify the quality of published data. We dive deep into the Write-Audit-Publish (WAP) pattern, demonstrating how it works with Apache Iceberg.

Implement historical record lookup and Slowly Changing Dimensions Type-2 using Apache Iceberg
This post will explore how to look up the history of records and tables using Apache Iceberg, focusing on Slowly Changing Dimensions (SCD) Type-2. This method creates new records for each data change while preserving old ones, thus maintaining a full history. By the end, you’ll understand how to use Apache Iceberg to manage historical records effectively on a typical CDC architecture.