AWS Business Intelligence Blog
Super-charged pivot tables in Amazon QuickSight
| All your trusted BI capabilities of Amazon QuickSight now come with powerful new AI features that integrate chat agents, deep research, and automation in one seamless experience with Amazon Quick Suite! Learn more » |
Amazon QuickSight is a fast and cloud-powered business intelligence (BI) service that makes it easy to create and deliver insights to everyone in your organization without any servers or infrastructure. QuickSight dashboards can also be embedded into applications and portals to deliver insights to external stakeholders. Additionally, with Amazon QuickSight Q, end-users can simply ask questions in natural language to get machine learning (ML)-powered visual responses to their questions.
Recently, Amazon FinTech migrated all their financial reporting to QuickSight. This involved migrating complex tables and pivot tables, helping them slice and dice large datasets and deliver pixel-perfect views of their data to their stakeholders. Amazon FinTech, like all QuickSight customers, needs fast performance on very large pivot tables in order to drive adoption of their dashboards. We have specifically launched two new features focused on scaling our pivot tables with the following improvements:
- Faster loading of pivot tables during expand and collapse operations
- Increased field limits for rows, columns, and values
In this post, we discuss these improvements to pivot tables in QuickSight.
Blazing fast pivot tables during expand and collapse operations
Today, QuickSight pivot tables work as an infinite load. As users scroll vertically or horizontally on the visual, new queries are run to fetch additional rows and columns of data with fixed row and column configurations for every query request.
For example, in the following table, we would load all carrier/city combinations nested under Dec 7, 2014 before we can continue querying the next date. Let’s say we have more than 500 carrier/city rows for a specific date; this will take more than a single query to get to the next date. The count of queries run depends on the cardinality of the dimension used in the pivot table.
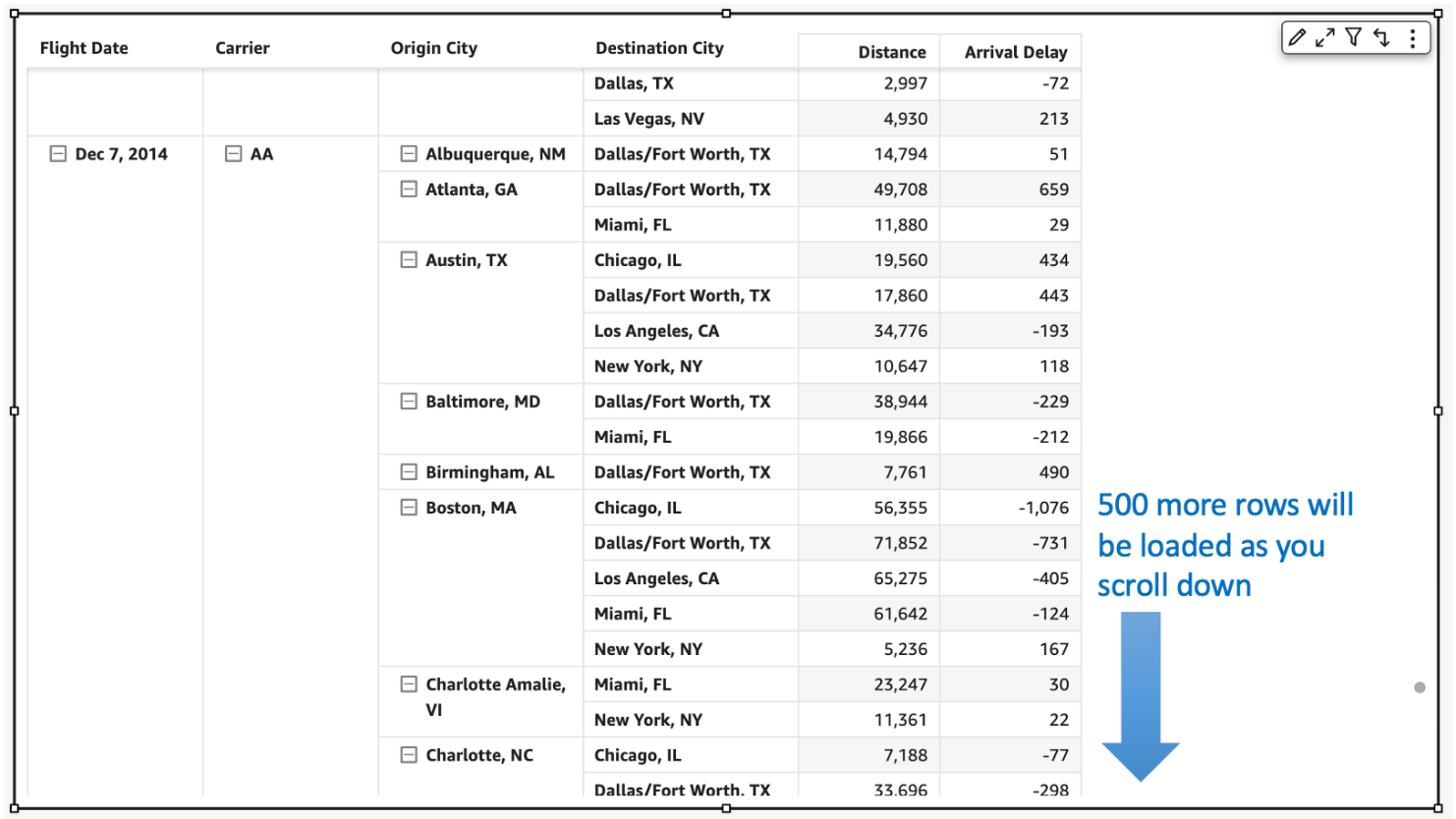
In the following example of a collapsed pivot table, since the reader doesn’t see anything beyond the flight dates, having all carrier/city rows doesn’t change what is actively displayed on the pivot table. Even though individual SQL queries can be fast, users can perceive this table to load slowly due to the sheer number of queries being fired to load the hidden (collapsed) data. Therefore, loading every single row up to the Destination City field isn’t very useful when the pivot table in the collapsed state.
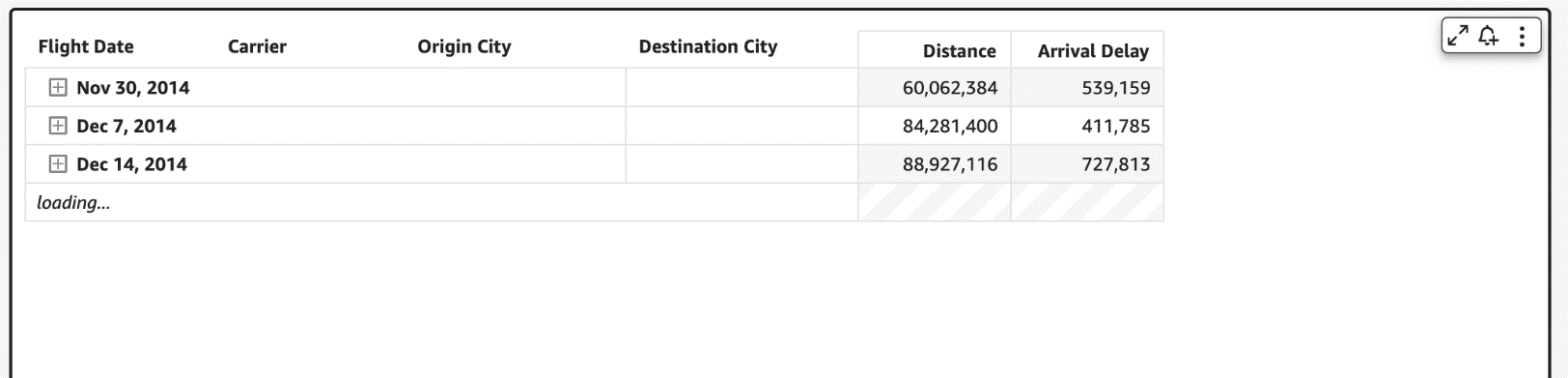
Therefore, to make our pivot tables load faster, we now only fetch the data for visible fields (expanded fields) along with a small subset of values under the collapsed field. This makes sure that data fetched in every new query is used to render new values that can be displayed immediately. We have seen customers improve their load time from 2–10 times faster depending on the complexity of their dataset.
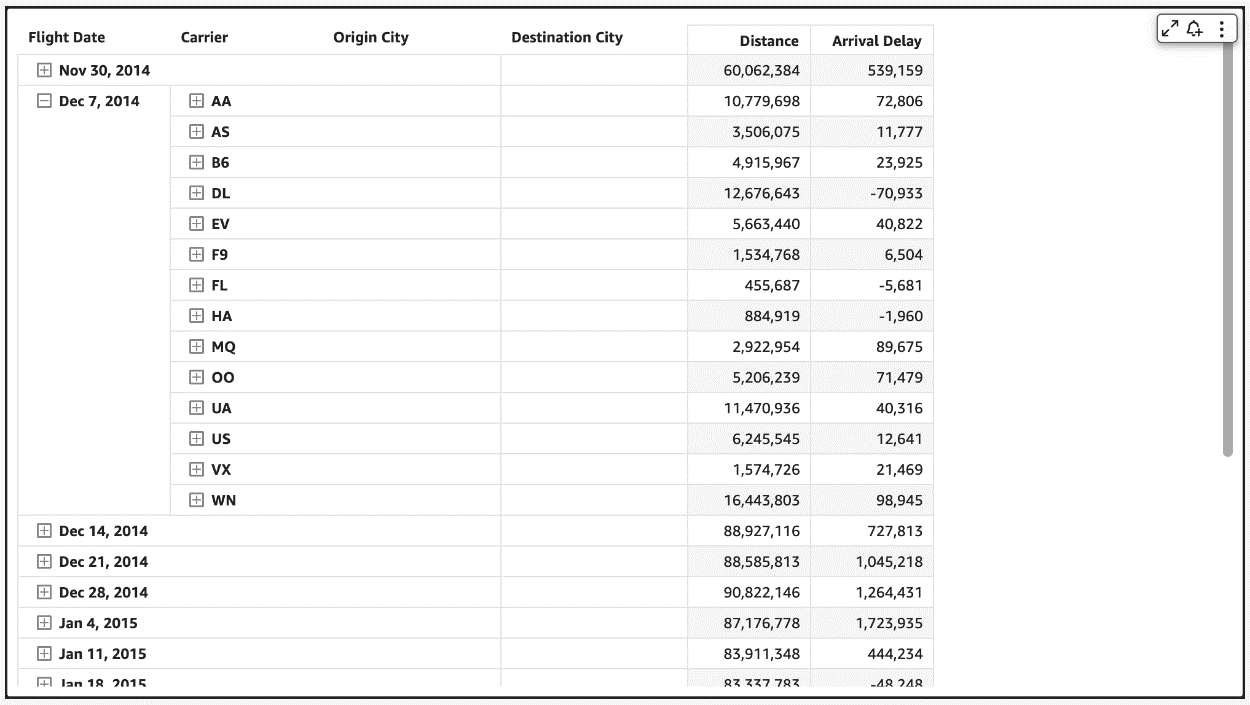
This new behavior is automatically enabled, without requiring users to do anything on their side. Please note that while we plan to support all kinds of pivot tables to use this optimization, our current rollout only includes pivot tables with only row or only column fields not sorted by any metric.
Increased field limits for pivot tables
With the ever-growing depth and granularity of data being collected, our customers asked us to increase the number of fields and data points they can display in their visuals. We have been actively listening to your needs, and just like supporting more data points in line charts, we now are increasing our field limits for pivot tables.
The value field well limits have been increased from 20 to 40, and rows and columns have been increased from 20 each to a combined limit of 40. For example, if the user has 34 fields in rows, then they can add up to 6 fields to the column field well.
This will help unblock use cases requiring increased limits such as:
- Metrics reporting – Monthly and weekly business reporting often requires having dozens of metrics presented in tabular formats. With the updated limits, you can display detailed, robust financial reports in a single pivot table rather than having to split it across multiple pivot tables.

- Migration from legacy BI and reporting tools – Existing reports in these legacy systems require displaying and slicing across a large number of row hierarchies, for example a cost center expense analysis.
- Custom use cases – These are specific industry and organization use cases where you can add dozens of values and row fields to display additional attributes. For example, a customer 360 report sliced by different regions.
As soon as you hit the limit, you receive an error message to indicate that the limit has been reached for that field well. For more details, refer to here.
 |
|
Get started and stay updated!
Learn more about our new features in our newly launched QuickSight community’s Announcement section and supercharge your dashboards with the latest features from QuickSight!
About the authors
 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
 Igal Mizrahi is a Senior Software Engineer for AWS QuickSight Charting team. He has been part of the team for the past 3 years, and previously worked on Amazon’s mobile shopping application for 4 years.
Igal Mizrahi is a Senior Software Engineer for AWS QuickSight Charting team. He has been part of the team for the past 3 years, and previously worked on Amazon’s mobile shopping application for 4 years.