AWS Compute Blog

Author: James Beswick
James Beswick leads the Serverless Developer Advocacy team at AWS. He works with AWS's developer customers to understand how serverless technologies can drastically change the way they think about building and running applications at massive scale with minimal administration overhead. Visit https://serverlessland.com for more serverless content.

Introducing new AWS Serverless digital learning badges
The AWS Serverless Learning Plan and digital badge are available now. All courses are available on-demand. Both the learning plan courses and the assessment are free for everyone.

Using the AWS Parameter and Secrets Lambda extension to cache parameters and secrets
Caching data retrieved from external services is an effective way to improve the performance of your Lambda function and reduce costs. Implementing a caching layer has been made simpler with this AWS-managed Lambda extension.

Introducing cross-account access capabilities for AWS Step Functions
This post demonstrates how to create a Step Functions Express Workflow in one account and call it from a Step Functions Standard Workflow in another account using a new credentials capability of AWS Step Functions.

Node.js 18.x runtime now available in AWS Lambda
Node.js 18 is now supported by Lambda. When building your Lambda functions using the zip archive packaging style, use a runtime parameter value of nodejs18.x to get started building with Node.js 18.

Introducing attribute-based access controls (ABAC) for Amazon SQS
This post is written by Vikas Panghal (Principal Product Manager), and Hardik Vasa (Senior Solutions Architect). Amazon Simple Queue Service (SQS) is a fully managed message queuing service that makes it easier to decouple and scale microservices, distributed systems, and serverless applications. SQS queues enable asynchronous communication between different application components and ensure that each of these […]

Building serverless .NET applications on AWS Lambda using .NET 7
AWS now supports .NET 7 native AOT on Lambda. Read the Lambda Developer Guide for more getting started information. For more details on the performance improvements from using .NET 7 native AOT on Lambda, see the serverless-dotnet-demo repository on GitHub.

Enriching operational events with AWS Serverless
This post shows how you can create rules in EventBridge to react to operational events from AWS services. These events are routed to Step Functions, which runs a workflow consisting of steps to enrich the event, handle errors, and emit the enriched event. The example shows how to consume the enriched events, resulting in an operator receiving an email.

Server-side rendering micro-frontends – the architecture
This first post starts the journey into micro-frontends, a distributed architecture for frontend applications. The next post will explore the UI composer and micro-frontends discovery implementations.

Serverless and Application Integration sessions at AWS re:Invent 2022
AWS re:Invent 2022 is only a few weeks away, featuring an exciting slate of sessions on Serverless and Application Integration. This post highlights many of the sessions we are hosting on Serverless and Application Integration. It groups sessions by theme to help you quickly find the sessions most interesting to you.
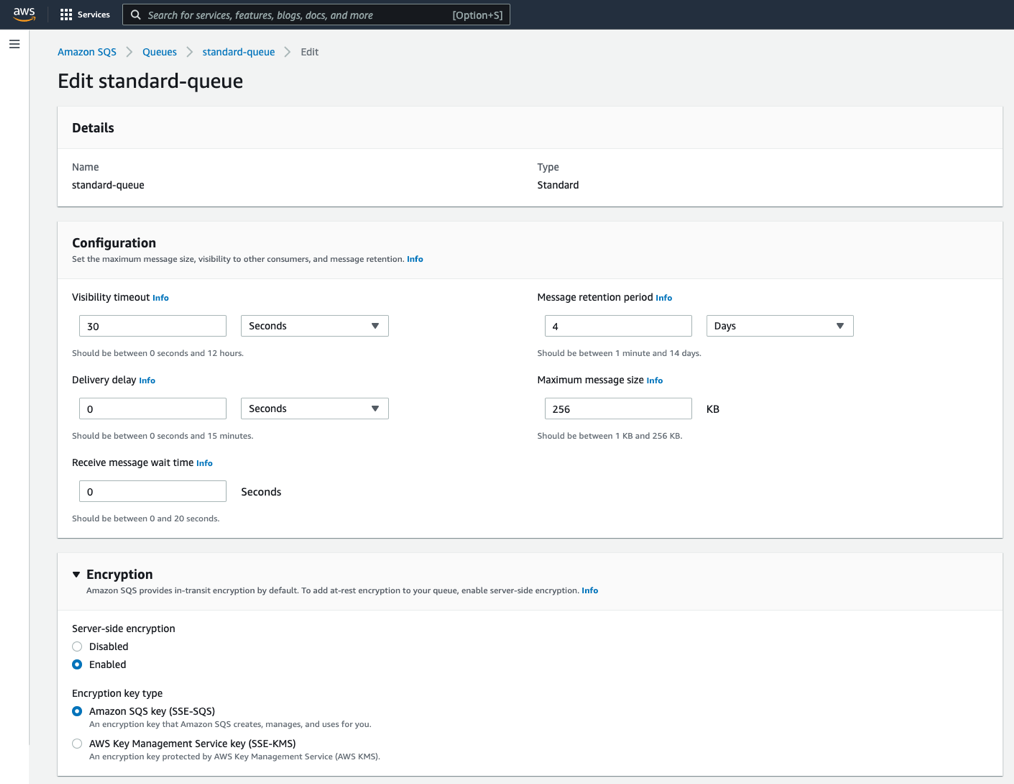
Announcing server-side encryption with Amazon Simple Queue Service -managed encryption keys (SSE-SQS) by default
SQS now provides server-side encryption (SSE) using SQS-owned encryption (SSE-SQS) by default. This enhancement makes it easier to create SQS queues, while greatly reducing the operational burden and complexity involved in protecting data.