AWS Compute Blog
Running GPU-Accelerated Kubernetes Workloads on P3 and P2 EC2 Instances with Amazon EKS
This post contributed by Scott Malkie, AWS Solutions Architect
Amazon EC2 P3 and P2 instances, featuring NVIDIA GPUs, power some of the most computationally advanced workloads today, including machine learning (ML), high performance computing (HPC), financial analytics, and video transcoding. Now Amazon Elastic Container Service for Kubernetes (Amazon EKS) supports P3 and P2 instances, making it easy to deploy, manage, and scale GPU-based containerized applications.
This blog post walks through how to start up GPU-powered worker nodes and connect them to an existing Amazon EKS cluster. Then it demonstrates an example application to show how containers can take advantage of all that GPU power!
Prerequisites
You need an existing Amazon EKS cluster, kubectl, and the aws-iam-authenticator set up according to Getting Started with Amazon EKS.
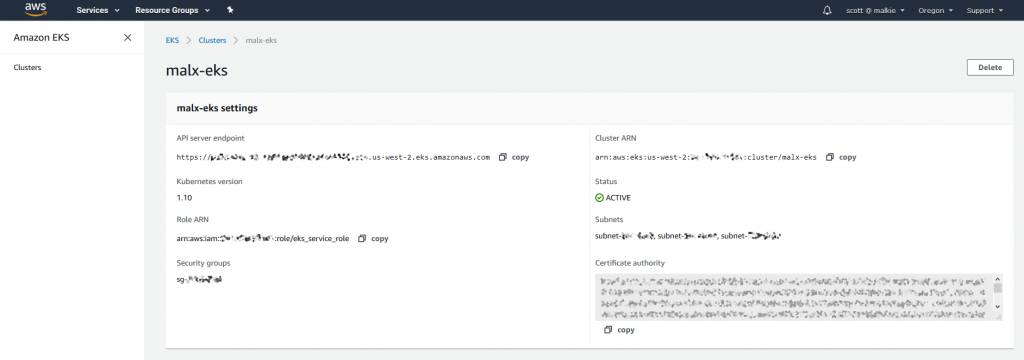
Two steps are required to enable GPU workloads. First, join Amazon EC2 P3 or P2 GPU compute instances as worker nodes to the Kubernetes cluster. Second, configure pods to enable container-level access to the node’s GPUs.
Spinning up Amazon EC2 GPU instances and joining them to an existing Amazon EKS Cluster
To start the worker nodes, use the standard AWS CloudFormation template for Amazon EKS worker nodes, specifying the AMI ID of the new Amazon EKS-optimized AMI for GPU workloads. This AMI is available on AWS Marketplace.
Subscribe to the AMI and then launch it using the AWS CloudFormation template. The template takes care of networking, configuring kubelets, and placing your worker nodes into an Auto Scaling group, as shown in the following image.
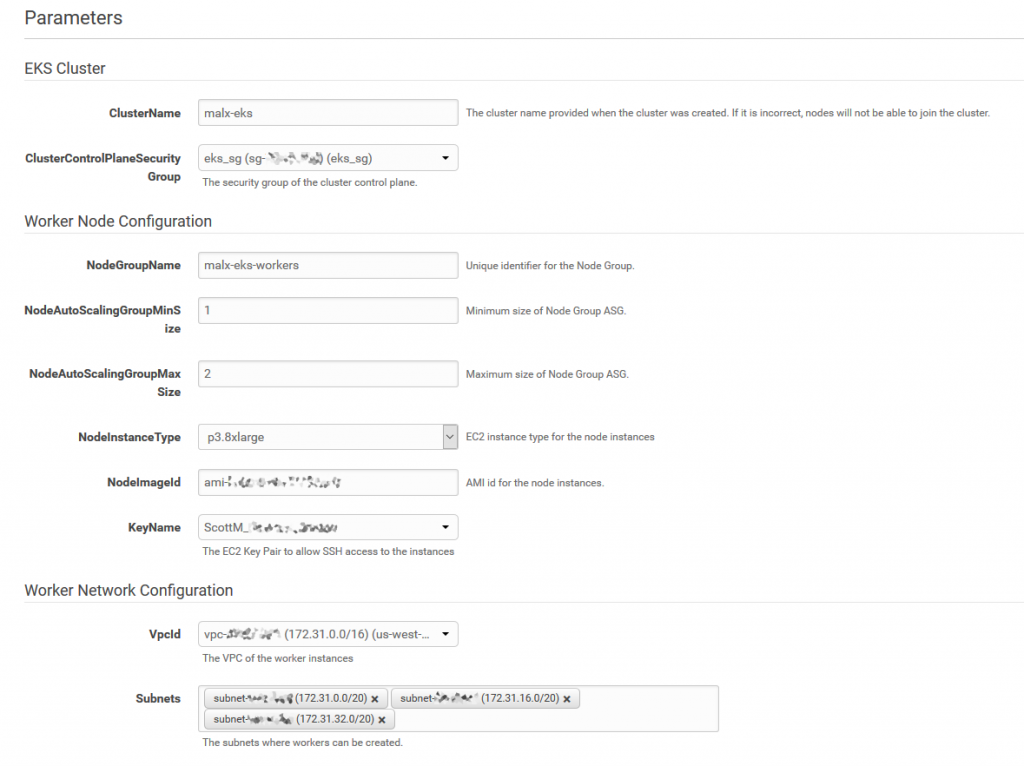
This template creates an Auto Scaling group with up to two p3.8xlarge Amazon EC2 GPU instances. Powered by up to eight NVIDIA Tesla V100 GPUs, these instances deliver up to 1 petaflop of mixed-precision performance per instance to significantly accelerate ML and HPC applications. Amazon EC2 P3 instances have been proven to reduce ML training times from days to hours and to reduce time-to-results for HPC.
After the AWS CloudFormation template completes, the Outputs view contains the NodeInstanceRole parameter, as shown in the following image.

NodeInstanceRole needs to be passed in to the AWS Authenticator ConfigMap, as documented in the AWS EKS Getting Started Guide. To do so, edit the ConfigMap template and run the command kubectl apply -f aws-auth-cm.yaml in your terminal to apply the ConfigMap. You can then run kubectl get nodes —watch to watch the two Amazon EC2 GPU instances join the cluster, as shown in the following image.

Configuring Kubernetes pods to access GPU resources
First, use the following command to apply the NVIDIA Kubernetes device plugin as a daemon set on the cluster.
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.10/nvidia-device-plugin.yml
This command produces the following output:
![]()
Once the daemon set is running on the GPU-powered worker nodes, use the following command to verify that each node has allocatable GPUs.
kubectl get nodes \
"-o=custom-columns=NAME:.metadata.name,GPU:.status.allocatable.nvidia\.com/gpu"
The following output shows that each node has four GPUs available:

Next, modify any Kubernetes pod manifests, such as the following one, to take advantage of these GPUs. In general, adding the resources configuration (resources: limits:) to pod manifests gives containers access to one GPU. A pod can have access to all of the GPUs available to the node that it’s running on.
apiVersion: v1
kind: Pod
metadata:
name: pod-name
spec:
containers:
- name: container-name
...
resources:
limits:
nvidia.com/gpu: 4As a more specific example, the following sample manifest displays the results of the nvidia-smi binary, which shows diagnostic information about all GPUs visible to the container.
apiVersion: v1
kind: Pod
metadata:
name: nvidia-smi
spec:
restartPolicy: OnFailure
containers:
- name: nvidia-smi
image: nvidia/cuda:latest
args:
- "nvidia-smi"
resources:
limits:
nvidia.com/gpu: 4Download this manifest as nvidia-smi-pod.yaml and launch it with kubectl apply -f nvidia-smi-pod.yaml.
To confirm successful nvidia-smi execution, use the following command to examine the log.
kubectl logs nvidia-smi
The above commands produce the following output:
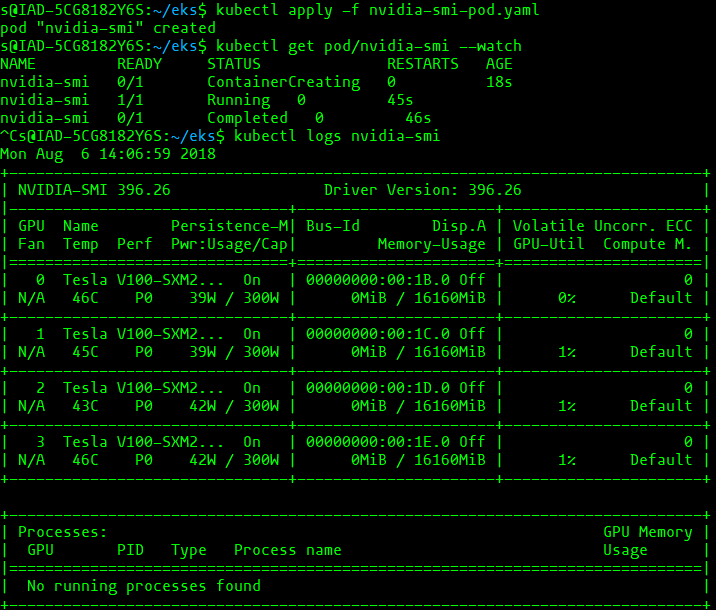
Existing limitations
- GPUs cannot be overprovisioned – containers and pods cannot share GPUs
- The maximum number of GPUs that you can schedule to a pod is capped by the number of GPUs available to that pod’s node
- Depending on your account, you might have Amazon EC2 service limits on how many and which type of Amazon EC2 GPU compute instances you can launch simultaneously
For more information about GPU support in Kubernetes, see the Kubernetes documentation. For more information about using Amazon EKS, see the Amazon EKS documentation. Guidance setting up and running Amazon EKS can be found in the AWS Workshop for Kubernetes on GitHub.
Please leave any comments about this post and share what you’re working on. I can’t wait to see what you build with GPU-powered workloads on Amazon EKS!