Containers
Onfido’s Journey to a Multi-Cluster Amazon EKS Architecture
This blog was coauthored by Eugene Malihins, Senior DevOps Engineer at Onfido, and Olly Pomeroy, Containers Specialist SA at Amazon Web Services
Who is Onfido?
Onfido is setting the new standard for digital access. The company digitally proves a user’s real identity using artificial intelligence (AI) by verifying a photo ID and comparing it to the person’s facial biometrics. This means businesses can verify their users without compromising on experience, conversion, privacy, or security.
Onfido’s current architecture
As Onfido’s business has grown, the volume of traffic and the number of processed identity checks have increased to the point where Onfido now serve clients around the world. Any interruption to our service directly impacts a partner’s ability to onboard new customers. The 24-7 availability of our APIs is essential, requiring an increasingly more stable and scalable infrastructure. For this reason, many years ago, we turned to Kubernetes to provide a scalable platform to handle the increased volume of requests and provide us with a higher level of reliability. At the same time, containers allowed us to reduce the time taken to develop new features and deploy them to production.
Two years ago, we made the decision to migrate our existing self-managed Kubernetes clusters to Amazon Elastic Kubernetes Service (Amazon EKS). Abstracting away the complexity of operating and upgrading Kubernetes clusters allowed the team to focus on what matters most: helping engineers build and ship code, optimize and prepare infrastructure for future growth, and ensure good engineering practices throughout the engineering team.
Onfido’s previous Kubernetes upgrade process
Adopting Amazon EKS made us think slightly differently about the Kubernetes upgrade process. Amazon EKS manages the process of upgrading the Kubernetes Control Plane, removing an operational burden from the team. However, there were still plenty of unknowns during a platform upgrade. These unknowns include predicting how core platforms components (such as CoreDNS and CNI Networking) would respond to a new Kubernetes version as well as how these components would behave in moments when the Kubernetes API server was unavailable.
Onfido previously operated one production cluster in each AWS Region and numerous preproduction clusters. We ensure we test each Amazon EKS version upgrade heavily in our preproduction environments to give us assurances and to try and answer some of the unknowns before we roll out the change to the production environments. However, systems tend to behave differently under real-world conditions, and even with extensive testing, there are still scenarios that can be hard to emulate in a preproduction environment. During a previous upgrade of a production Amazon EKS cluster, we experienced a short degradation of service in our applications. There was a short period of time where traffic was not flowing correctly to the Kubernetes pods.
During the post mortem of this outage, we started to recognize the value of changing our architecture from a single production Amazon EKS cluster per AWS Region to 2x production Amazon EKS clusters per AWS Region.
Multi-cluster Amazon EKS architectures
When considering a multi-cluster Kubernetes architecture, a decision has to be made if the Kubernetes clusters will operate independently from one another or if federation technologies would be used to create some form of distributed or stretched environment.
With high availability in mind, our initial requirements for the multi-cluster architecture were:
- To ensure it was easy to deploy a service across multiple clusters.
- To serve production traffic from multiple clusters at the same time.
- To have the ability to take a cluster out of the flow of traffic, regardless of whether the traffic shift was planned (for example, for maintenance) or unplanned (that is, degradation of a service).
During our investigation, we first looked at the federated technologies. To meet our requirements, we found that we could leverage Kubernetes federation to ensure deployments and scaling would be distributed across clusters, and we could leverage service mesh technologies to create a shared networking namespace and service dictionary.
At the time of our investigation, the KubeFed project appeared to be the cutting edge of Kubernetes Federation. KubeFed is a control plane that sits in front of multiple Kubernetes clusters providing a single place to deploy workloads to. However, at the time of writing, we felt the KubeFed project lacked the maturity we were looking for to give us the confidence to support it in production. Additionally, KubeFed introduced a maintenance overhead with “another” Kubernetes Control Plane that we are currently not willing to support. However, the project has an exciting future, and we will continue to monitor its progress.
After discounting federated Kubernetes clusters as well as stretched networking, we investigated operating multiple independent production Kubernetes clusters in the same AWS Region. On the surface, this would be a simpler solution to implement, with no overhead in managing additional Federation or Service Mesh control planes and no additional technologies to learn.
From a Kubernetes perspective, this architecture was straightforward and easy to understand. Each cluster could operate its scaling independently, and one issue in one cluster would not bleed over to the second. Our existing pipeline could be extended to deploy the same resources into each cluster, with both clusters actively serving ingress traffic and processing data from queues.
Routing traffic to multiple Amazon EKS clusters
The big architectural decision when operating independent Kubernetes clusters is how to route traffic between the clusters. Here we considered three options:
- Deploy an Application Load Balancer for each Amazon EKS cluster configured to direct traffic to an ingress controller. Use weighted Amazon Route 53 records to shift the traffic between the Application Load Balancers.
- Deploy an Application Load Balancer for each Amazon EKS cluster configured to direct traffic to an ingress controller. Configure a proxy layer using software reverse proxies (such as Nginx or HA Proxy) running on Amazon Elastic Compute Cloud (Amazon EC2), and through the proxy’s configuration, shift traffic between the Application Load Balancers.
- Deploy a single Application Load Balancer with multiple target groups. A target group would be configured for each EKS cluster. When creating the Application Load Balancer listener rules, the traffic would be forwarded to multiple target groups with a variable weighted element.
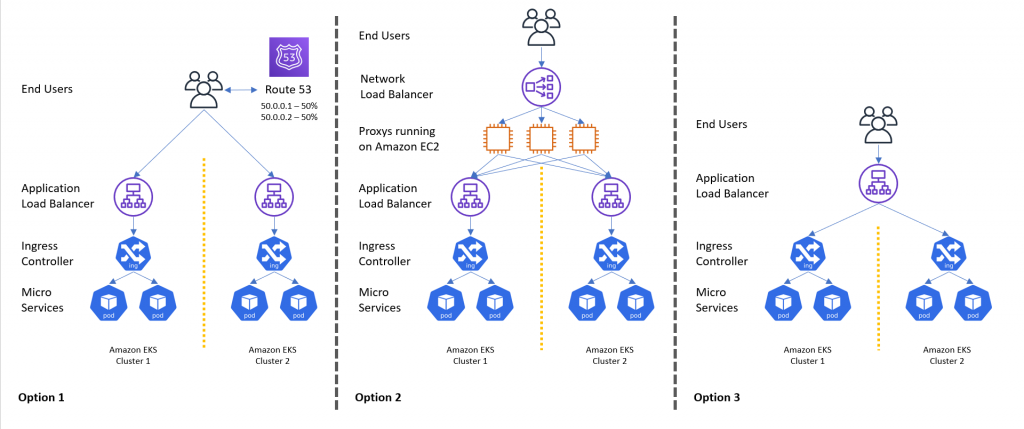
After further investigation, we soon understood that using weighted Route 53 records would not be suitable for our use case. Some of our upstream services and partners would try to cache IPs returned by DNS lookups, preventing us from being able to instantly flip traffic between the Amazon EKS clusters.
Introducing a proxying layer with software load balancers would meet our requirements. However, it would also provide an additional unmanaged component to our architecture. We would have to build a runbook to maintain and scale these load balancers and did not want to take on that responsibility.
Deploying a single Application Load Balancer with target groups for each Amazon EKS cluster appeared to meet our requirements and be the most efficient of the three solutions to implement and manage. The ALB would have weighted listener rules configured to send traffic to different target groups. This gave us the ability to shift traffic between the Amazon EKS clusters instantly, and at the same time, allowed us to monitor how much traffic each target group (therefore each Amazon EKS cluster) received.
Utilizing a single ALB with weighted listener rules met all three of our multi-cluster requirements:
- Our existing pipeline tooling could be extended to deploy services to multiple Amazon EKS clusters.
- A single ALB could serve traffic from multiple Amazon EKS clusters at the same time.
- For planned or unplanned downtime, we were able to adjust the volume of traffic going to each Kubernetes cluster through the ALB listener rules.
When performing Kubernetes upgrades, our new workflow would be to gradually adjust a target groups weighting via the forward listener rules. We would be able to monitor how much traffic was being distributed between the Amazon EKS clusters before, during, and after upgrade with the Application Load Balancer’s RequestCountPerTarget metric.
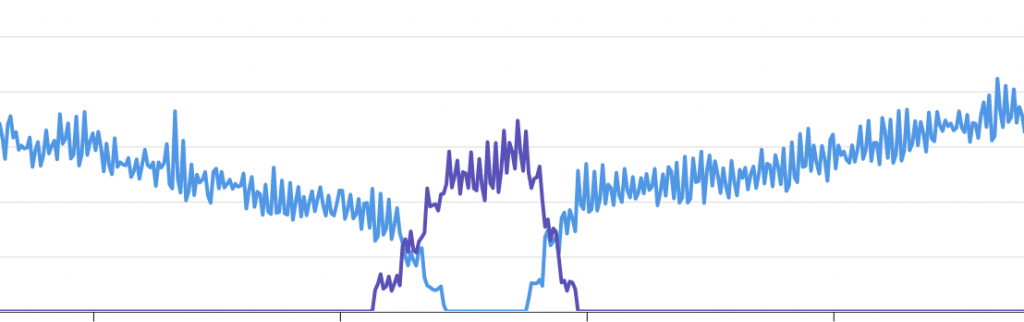
This chart above shows requests for a particular workload being migrated between 2x Amazon EKS clusters. This particular service was being served solely from 1x Amazon EKS cluster. We then gradually adjusted the weighting of the listener rules until all requests were being served by the second cluster. We were then in a position to confidently perform maintenance and acceptance testing on the first cluster. Finally, for this particular test, once the Kubernetes control plane and infrastructure upgrades were complete, we then migrated all of the traffic back to the first cluster.
Things to consider
Throughout our multi-cluster design and implementation, we faced a number of challenges and made a few observations that we think would help others going on a similar journey.
Stateful workloads – All of the workloads deployed to our Kubernetes clusters are stateless. Therefore, when migrating or distributing services between clusters, we did not have to worry about the migration of shared state or persistent storage. If a workload had required state, data replication outside of Kubernetes would need to have been considered.
Queue consumers – During the migration from a single production cluster to multiple production clusters, we needed to ensure that we implemented robust message processing. Workloads or clusters could be scaled down and disrupted while processing a job, and we needed to ensure messages were not deleted from queues until we received confirmation from a backend system that they had been processed.
CI/CD pipeline – Our existing pipeline needed to be extended to support rolling out services to multiple production clusters, as both clusters could be serving production traffic at the same time that we needed to ensure the deployment versions across the clusters stayed in sync. There was also scope to explore blue/green or canary deployments through the weighting of the ALB listener rules.
Monitoring and observability – On-call teams needed to be aware of the new architecture and be comfortable with assessing which cluster is reporting errors and alerts. This also meant implementing changes to our existing monitoring tags and labels, not only displaying which deployment, namespace, Region, or environment a pod was deployed into but also adding cluster metadata to the streams as well.
Being cluster agnostic – One of the biggest hurdles we could envisage when moving from one to multiple production EKS clusters was around resource ownership. At Onfido, we use Terraform to define our AWS infrastructure. For our production systems, we provision the Application Load Balancers, target groups, listener rules, and the DNS records through Terraform.
Alternatively, we are aware it is possible to create some of these resources from inside the Kubernetes cluster. Kubernetes ingress objects could provision the Application Load Balancers, ExternalDNS could be used to create the Route53 records. However, in doing so, we may have faced conflicts when exposing two services from two clusters at the same time. There could be scenarios where both clusters would want to create identical route 53 records or own independent Application Load Balancers.
Fortunately, we did not face these challenges as the decision had already been made to own these resources outside of Kubernetes. We felt the demarcation point for a new service to go live would live in our Infrastructure as Code tooling rather than in Kubernetes. That being said, our on-call teams have provided feedback that it is desirable to have a more accessible interface to update the traffic weightings. This is something we will investigate in a future sprint.
Conclusion
Before moving to a multi-cluster EKS setup, we were nervous during Amazon EKS cluster upgrades. The number of moving parts in our production Kubernetes cluster made it very hard to test all of the possible scenarios in the preproduction environments, and in a 24-7 business, we could not suffer an outage.
Moving to an active/active cluster architecture has allowed us to shift traffic away from an Amazon EKS cluster when performing infrastructure maintenance. This provides an opportunity for us to perform Kubernetes control plane upgrades as well as an opportunity to upgrade core infrastructure components like ingress controllers and CNI networking. We are constantly looking to evolve this architecture with further cost optimization and enhancements to our monitoring and CI/CD tooling planned for the future.
About Onfido
Onfido is the new identity standard for the internet. Their AI-based technology assesses whether a user’s government-issued ID is genuine or fraudulent, and then compares it against their facial biometrics. That’s how they provide the assurance needed to onboard customers remotely and securely.
About the author
Eugene Malihins is a Senior DevOps Engineer at Onfido supporting Onfido’s AWS and Amazon EKS infrastructure.
