Containers
Using SBOM to find vulnerable container images running on Amazon EKS clusters
Introduction
When you purchase a packaged food item in your local grocery store, you probably check the list of ingredients written to understand what’s inside and make sure you aren’t consuming ingredients inadvertently that you don’t want to or are known to have adverse health effects. Do you think in a similar way when you purchase or consume a software product? Do you have visibility into exactly what components make up the software and if any component might have known vulnerabilities? A typical software application today is built using many open-source software libraries and reusable third-party code. While this improves the productivity of developers and their ability to deliver new features faster, it introduces additional security risks in production environments because developers have less visibility and control over security flaws in third-party code.
Synopsys released its 2023 Open Source Security and Risk Analysis Report (OSSRA) which shows that 96% of scanned commercial codebases contained open source and 76% of code in codebases was open source. Another insight from OSSRA is that 48% of codebases contained high risk vulnerabilities. This indicates that modern software applications are heavily reliant on open source which could have vulnerabilities and hence it’s important to have visibility into the components that are used in the application. The application may declare its direct dependencies that depend on other packages, which results in transitive dependencies that make it extremely challenging to detect every library or package that the application uses. A single open-source or proprietary software component embedded in applications deployed in thousands of organizations has the potential to cause widespread security impact. The complexity and lack of transparency in modern software supply chain makes it attractive for hackers to launch supply chain attacks affecting a large number of organizations. The annual State of Software Supply Chain report for 2022 presented by Sonatype found that there has been 742% average annual increase in Software Supply Chain attacks over the past 3 years. The SolarWinds hack in 2020 is an example of supply chain attack that led to breach of IT systems of organizations around the world including the US Federal Government. In response to increasing number and sophistication of cyberattacks, President Biden signed Executive Order 14028 in May 2021. The order improves the Nation’s cybersecurity capabilities, including to the key focus areas of enhancing the software supply chain security.
Multiple mechanisms need to be implemented to improve trust and security of the software supply chain. A previously published AWS post focused primarily on helping customers understand the software supply chain security in the context of authenticity and provenance. The post describes how cryptographic signatures simplify the process of ensuring that container images from trusted parties are allowed to be used for image builds and deployments. AWS also announced the launch of AWS Signer Container Image Signing, which is a new capability that gives customers native AWS support for signing and verifying container images stored in container registries like Amazon Elastic Container Registry (Amazon ECR).
The focus of this post is on the transparency aspect of software supply chain and how Software Bill of Materials (SBOM) can provide visibility into the software packages that are embedded in your container images, which allow you to quickly and easily determine whether your containerized application is at any potential risk of a newly discovered vulnerability.
What is SBOM and why is it important?
An SBOM is a formal, machine-readable record of all the libraries, modules, and dependencies used in building a software product and the relationships between these components. These components can be open source or proprietary, free or paid, and available from public or private restricted access repositories. SBOM records are designed to be shared across organizations so that purchasers or consumers of software products can get transparency on the components provided by different parties in the supply chain. For example, the SBOM of a container image can provide an inventory of the all the components that were used to build the image. This includes operating system packages, any application specific dependencies or libraries and their versions, and supplier and license information.
The concept of SBOM has been around in the open-source community for over a decade, and even longer in commercial software; however, it is now gaining prominence because of the US Administration’s Executive Order 14028. According to a 2022 research report by the Linux foundation, 412 global organizations were surveyed and 78% of organizations expected to produce or consume SBOMs in 2022.
The key benefits for organizations to use SBOM’s are to:
- Understand all the dependencies for an application
- Identify and avoid the use of software components with known vulnerabilities
- Identify applications or software that use a specific component version with newly discovered vulnerability
- Manage license compliance requirements
In AWS, most customer workloads start with a packaged environment of some kind, like Amazon Machine Images (AMIs), container images, or AWS Lambda zips. SBOMs provide a simple and machine-readable way to quickly discover what software is running in a given environment. Because SBOMs are created in standard machine-readable formats, you can use a vulnerability scanner to read SBOM’s and detect components with known vulnerabilities. For example, Grype is an open-source vulnerability scanner for container images and filesystems and it can be provided SBOM file as an input for fast vulnerability scan. You can integrate vulnerability scanning tools in your Continuous Integration And Continuous Delivery (CI/CD) pipeline so that software components with known vulnerabilities don’t make their way into your software artifact. But what about the situation when a new zero-day vulnerability, such as Log4Shell, is disclosed and you are racing against time to figure out the risk of this vulnerability for your organization?
Zero-day vulnerabilities, by definition, don’t have an immediate patch or fix available (e.g., the Log4j exploit), so they tend to be serious vulnerabilities. Bad actors immediately try to exploit the vulnerability to gain access to your IT systems. In such situations, what you want to find out quickly and easily is where the software component with vulnerability being used in your organization is, and then assess the risk and prioritize action items to mitigate the risk independent of the efforts by the component supplier to provide a patch. You can identify what software is unaffected and focus on mitigation actions only on the affected software. This is where SBOM can be a very effective tool in quantifying the risk associated with a vulnerable component based on its usage in the organization.
In this post, we present an approach of using SBOM to find container images running in your Amazon EKS cluster that have vulnerable software component inside. The solution components address some of the key considerations in using SBOM, like automatic generation of SBOM for container images, centralized storage for SBOM inventory, and the ability to search through the inventory quickly when you need to.
Solution overview
The following diagram depicts the architecture of the solution. The two most popular open standards for SBOM format are SPDX and CycloneDX. Most tools available to generate SBOM support both these formats. Amazon Web Services (AWS) has recently introduced a feature for Amazon Inspector service that enables automated and centralized generation of SBOM for all Amazon Inspector monitored resources across an organization including container images in Amazon ECR. The Amazon Inspector’s SBOM feature supports both CycloneDX and SPDX formats. You can learn more about Exporting SBOMs with Amazon Inspector.
This post’s solution uses the open-source project, Syft, for generating the container image SBOM in SPDX JSON format. Many customers use third-party solutions for container security instead of Amazon Inspector. Syft provides an effective and open-source alternative to creating SBOMs. SPDX is an open standard for communicating SBOM information including components, licenses, and copyrights associated with a particular version of a software package. Among these SBOM formats, SPDX has been around the longest with v1.0 being released back in August 2011. Similar to Amazon Inspector, our solution also stores the generated SBOM’s in a Amazon Simple Storage Service (Amazon S3) bucket for analysis.
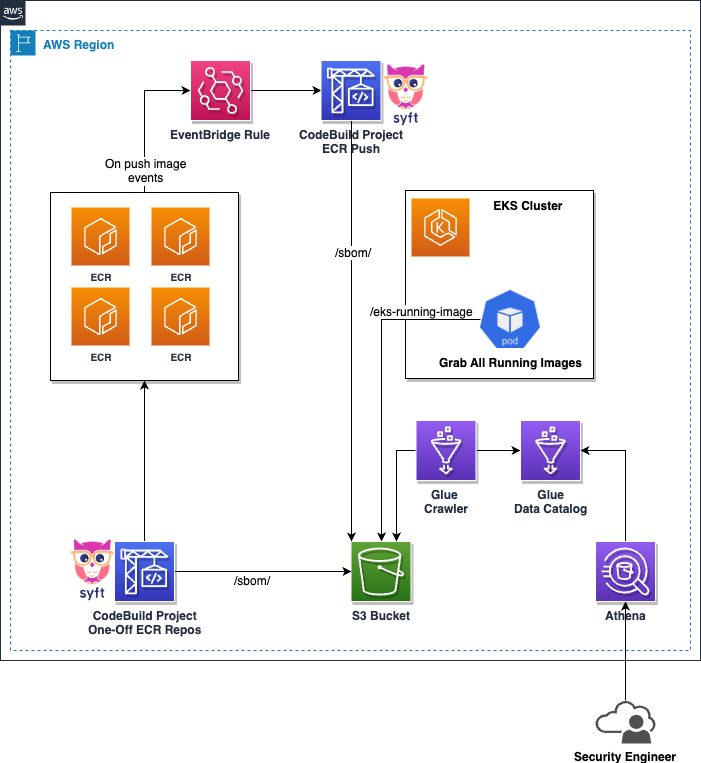
- Pipeline to generate SBOM – The pipeline is implemented using AWS CodeBuild and is triggered whenever a new image is pushed to any Amazon ECR repository in your AWS account. Amazon ECR is a fully managed container registry that makes it easy for developers to share and deploy container images and artifacts. Amazon ECR emits event when image is successfully pushed to repository. Please be aware that Amazon ECR events on Amazon EventBridge are delivered on a best-effort basis, and this should be factored into production environment considerations. Further details on AWS service event delivery via Amazon EventBridge can be found here. The event is delivered to Amazon EventBridge, which is a serverless service that builds event-driven applications. You can define the rules in Amazon EventBridge that match incoming events and sends them to targets for processing. In this solution, the Amazon EventBridge rule is defined with a pattern to match the successful push of image to repository and this event is then delivered to AWS CodeBuild as the target.
The event contains details such as repository name, image digest, and image tag, which the AWS CodeBuild pipeline can use to pull the new image from the Amazon ECR repository in the build phase. Syft is then used to generate SBOM in SPDX JSON format for the downloaded image. Final step of the build phase is to upload the SBOM JSON to an Amazon S3 bucket.
This component demonstrates how you can use Amazon ECR, Amazon EventBridge, and AWS CodeBuild to create serverless CI/CD pipelines. For a list of Amazon ECR events delivered to Amazon EventBridge, refer to the documentation.
- SBOM for existing container images – Once you incorporate SBOM generation in your container build pipeline, every new container image built has a corresponding SBOM file stored in the Amazon S3 bucket. What about images that have already been built? In this solution, we have provided a AWS CodeBuild project that you can trigger as a one-off build from AWS Console or AWS Command Line Interface (AWS CLI). This component discovers all Amazon ECR repositories in your account and generates SBOM for all the images that already exist in that account and specified Region.
- CronJob to discover images running in Amazon EKS cluster – This component can be deployed as a scheduled CronJob on any Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The job discovers all of the pods running in all namespaces and creates a JSON file with all container images in the pods. The job uses official Kubernetes python client to call Application Programming Interface (API) server. The JSON file is uploaded to an Amazon S3 bucket. The file on Amazon S3 is always overwritten, which means there is only one image list file for a given Amazon EKS cluster.
- SBOM analysis – The analysis component can be used to query SBOM and image list files stored on Amazon S3. This component consists of:
- AWS Glue Crawler and Data Catalog – The AWS Glue Data Catalog is an index to the location, schema, and runtime metrics of your data. AWS Glue crawler is configured to use Amazon S3 buckets containing SBOM and image list files as data sources. The crawler discovers the schema from JSON files to use to populate the AWS Glue Data Catalog with tables.
- Amazon Athena – Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon S3 using standard SQL. We use Amazon Athena to query SBOM and image list JSON files stored in Amazon S3 and identify images containing vulnerable packages.
Prerequisites
The following are the prerequisites for deploying the solution:
- An AWS account
- Command line terminal
- AWS CLI and configure it with your AWS Credentials
- Amazon Elastic Kubernetes Service (Amazon EKS) Cluster
- Terraform version 1.3.9 or later installed and configured on your local machine.
- Git installed
- eksctl installed
- kubectl installed
Walkthrough
This section describes how to deploy the solution architecture described above.
In this post, we’ll perform the following tasks:
- Clone the GitHub repository and deploy the solution architecture using Terraform
- Deploy a CronJob on Amazon EKS cluster to discover images for running containers
- Populate AWS Glue catalog with tables for SBOM and running images data
- Run Amazon Athena queries to identify images the use vulnerable libraries and packages
Deploy the solution architecture using Terraform
- First clone the sample GitHub Repository:
In the root directory of the GitHub repository
Navigate to the terraform directory.
- Edit the tfvars file inside the Terraform directory with a text editor. Make sure you provide the correct value for the aws_region variable to specify the AWS Region where you want to deploy. You can accept the defaults for other variables or change them if you wish.
- Make sure the principal being used to run Terraform has the necessary privileges to deploy all resources. Refer to the Terraform documentation for providing AWS authentication credentials.
- Run the following command to confirm you have configured the default region on your AWS CLI.
- The recommended way to provide the AWS credentials and default region is to use environment variables. For example, you can use the AWS_PROFILE environment variable to provide the AWS CLI profile to use for running terraform. Refer to AWS CLI documentation for configuration details.
- Initialize your working directory.
- Preview the resources that terraform will deploy in your AWS account.
- Deploy the resources. By running the following and selecting yes when prompted to approve the creation of resources.
Terraform outputs two values that you need to copy for the next step of deploying CronJob on Amazon EKS. You can run the command terraform output anytime to get the output values.
Deploy the Amazon EKS CronJob
We assume that you have an existing Amazon EKS cluster and Kubernetes CLI installed on your machine to interact with the cluster. The following steps describe how to deploy the CronJob component on Amazon EKS cluster.
In the root directory of the Git repository
Navigate to the eks-image-discovery directory. Then follow the steps below to deploy the CronJob on Amazon EKS cluster.
- Create IAM OpenID Connect (OIDC) provider for the EKS cluster following AWS documentation
- Create an AWS Identify and Access Management (AWS IAM) role for service account using eksctl. This AWS IAM role will be used by the Amazon EKS CronJob to write the list of running container images to Amazon S3 bucket. Replace cluster name and policy Amazon Resource Name (ARN) copied from the Terraform output. The policy is one of the resources created by Terraform modules. Following the principle of least privileged access, the policy only gives PutObject permission for SBOM S3 bucket resource.
{
"Statement": [{
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::sbom-bucket-20230606154820770300000004*"
}],
"Version": "2012-10-17"
}- Terraform would have created an Amazon ECR repository eks-image-discovery in your account to store image of Amazon EKS CronJob. Go to Amazon ECR repository in AWS Console and select the button for view push commands. Follow those commands to build and push the docker image of the Amazon EKS CronJob to the Amazon ECR repository. Copy the image Unified Resource Identifier (URI) of the newly pushed image from AWS Console.
- Navigate to config directory inside eks-image-discovery. This contains a Kubernetes manifest file that you need to edit for deploying the CronJob. Open eks-image-discovery.yaml file in any text editor.
- Edit the image field to change it to image URI that you copied in the previous step.
- Update the name of Amazon S3 bucket environment variable configuration. Use the bucket name copied from Terraform output.
- Update the name of the Amazon EKS cluster environment variable with your cluster name.
- Optionally, update the CronJob By default, the job runs every 5 minutes.
- Apply the manifest file using kubectl.
Populate the AWS Glue catalog
To populate the AWS Glue catalog, we need to generate the SBOM files. Push a new image to any Amazon ECR repository (i.e., for the Region you deployed the solution) in your account. That should trigger the AWS CodeBuild job to automatically generate an SBOM file for new image being pushed. Verify that AWS CodeBuild job finished successfully.

Perform this step if you want to generate SBOM files for existing images stored in Amazon ECR repositories of your account. Navigate to AWS CodeBuild service in AWS Console. Go to the project sbom-codebuild-project-one-off and start a new build. By default, the build job scans all Amazon ECR repositories in your account for the specified Region and creates SBOM files for all images stored in the repositories. If you want to generate SBOM files for existing images stored in specific repos, then you can change the Terraform variable one_off_scan_repo_settings, as per the instructions provided in the code repository.

Navigate to the Amazon S3 service in AWS Console. Verify that the AWS CodeBuild job created SBOM files, and the Amazon EKS CronJob created list of running images file in the Amazon S3 bucket created for the solution. The name of Amazon S3 bucket is one of the outputs of Terraform automation.


Now that SBOM files and list of running images on the Amazon EKS cluster have been created on Amazon S3, the next step is to run the AWS Glue crawler to access the Amazon S3 data source, extract metadata, and create table definitions in the AWS Glue Data Catalog Navigate to Glue service in AWS Console. Go to Crawlers and run crawler sbom_crawler. If there are large number of SBOM files in the Amazon S3 bucket, then the crawler will take a few minutes to process the files.

Wait for crawler to finish successfully. Once finished, navigate to Databases in the AWS Glue service console and select sbom_db. You should see two tables created in the database called sbom and eks_running_images.

Now you are ready to run Amazon Athena queries.
Run sample Amazon Athena queries
We’ll use Amazon Athena, which is a serverless query service that allows customers to analyze data stored in Amazon S3 using standard SQL. In this section, we’ll discuss some scenarios where customers may want to find out vulnerable software packages, and provide Amazon Athena queries that can be used to scan through the SBOM files.
To start querying your tables within the sbom_db database using Amazon Athena, follow these steps:
- Open the Amazon Athena console in your AWS Management Console.
- Confirm your data source is set to AwsDataCatalog – this should be the default selection.
- Next, locate and select the sbom_db database from the Database dropdown list, typically located on the left side of the Query Editor.
- Before running your first query, configure your query result location by navigating to the Settings tab located at the top right corner of the console. Under Query result location, input or choose the desired Amazon S3 location where your query results will be stored. Remember to select Save after setting the location. You can find more information on the Amazon Athena documentation about “Query results location.
- You can now return to the Query Editor and start writing and executing your queries on the sbom_db
Your Amazon Athena console should look something similar to the following diagram:

Remember that Amazon Athena queries data directly from Amazon S3, so ensure your Amazon Athena service has the necessary permissions to access the designated Amazon S3 buckets.
Into the next sections, let’s delve into the powerful querying capabilities of Amazon Athena applied to SBOMs. To facilitate a better understanding, we’ll walk you through three practical examples:
- Find a container image(s) with a specific package: This helps you identify container images within your Amazon EKS cluster containing a particular package, regardless of its version.
- Identify container image(s) with a certain package and version: This extends the previous example, which enables you to pinpoint container images not just by a package, but also its specific version running in your Amazon EKS cluster.
- You can find few more Athena queries (SQL) examples at our GitHub repository.
Remember, these examples merely scratch the surface of Amazon Athena’s functionality. With Amazon Athena’s robust SQL capabilities, you’re encouraged to craft queries that fit your needs with available SBOM data. This isn’t a limiting framework, but a jumping-off point to spark creativity and customization within your software supply chain management.
Vulnerability in a specific package – Search for specific package (without version)
This sample query allows users to input a package name with a wildcard character (%) and retrieve a list of all container images on their Amazon EKS cluster that contain a package with the specified name. Copy the query from the example below, and replace the <PACKAGE_NAME> with a package name that you’d like to find out if any container image running on your Amazon EKS cluster exists (or not) in containers that you have generated the SBOM.
In our example, consider the deployed container eks-image-discovery in your Amazon EKS cluster, containing a package named boto3. To locate this package, you would append WHERE package.name LIKE ‘%boto3%’ to the end of your Amazon Athena query. This approach enhances the discoverability of any package within your Amazon ECR container images. The beauty of this solution is its utilization of SQL language, which gives you the flexibility to tailor your queries to your needs, based on the available SBOM and running Amazon EKS images. This makes it a powerful tool for understanding your software supply chain.
Sample query:
Sample output:
Sample screenshot:

Vulnerability in specific package and version – Search for specific package and version
This sample query allows users to search for specific packages and versions that are currently running in their environment. For example, a vulnerability is announced for a specific package and version. You can use this query to look for images containing that specific package and version.
Sample query:
Incorporating SQL wildcards in your search for package versions can increase the flexibility of your query. For instance, if you need to find all versions that adhere to the format or version (1.26.X), where X can be any value, you may utilize the following AND statement (as depicted in the last line above):
Sample output:
Sample screenshot:

Cleaning up
To avoid incurring future charges, delete the resources created for this solution by running the following commands
- Navigate to the
eks-image-discoveryfolder from the root of the repository.
- Delete the Amazon EKS CronJob and associated resources
- Delete the AWS IAM service account
- Empty the Amazon S3 bucket created by Terraform for storing SBOM and running images files. If the bucket is not empty, then Terraform fails to delete the Amazon S3 bucket. Replace bucket name with the value from Terraform output. If you haven’t copied the bucket name, run terraform output command to view the outputs again.
- Navigate to the
terraformfolder from the root of the repository.
- Destroy all resources created by Terraform
Conclusion
In this post, we showed you how to integrate the use of SBOMs to enhance the transparency of your software supply chain and mitigate risk of vulnerable software in your operational environment. AWS Well-Architected Framework specifies a security best practice to automate testing and validation of security controls in pipelines. Incorporating SBOM generation should be another security feature in your container build pipeline to enable detection of vulnerable packages in your secure environments, prevent deployment of software containing specific packages, and verify licenses for various third-party software dependencies. Hence, SBOM adoption is an important step toward improving your overall security posture.
This solution opens doors to many possibilities. For instance, it can be adapted to serve varying organizational needs, scaled for larger deployments, or even utilized to enhance existing security measures.
We welcome your thoughts, insights, and experiences on this topic. Feel free to leave a comment below. Your feedback will not only enrich our collective knowledge but might also serve as an inspiration for future posts.