AWS Database Blog
Category: Best Practices

Build resilient applications with Amazon DynamoDB global tables: Part 4
In the first three posts of this four-part series, you learned how the choice of zonal or Regional services impacts availability, and some important characteristics of Amazon DynamoDB when used in a multi-Region context with global tables. Part 1 also covered the motivation for using multiple Regions. Part 2 discussed some important characteristics of DynamoDB. […]

Build resilient applications with Amazon DynamoDB global tables: Part 3
In the first two posts of this four-part series, you learned how the choice of zonal or Regional services impacts availability and some important characteristics of Amazon DynamoDB when used in a multi-Region context with global tables. Part 1 also covered the motivation for using multiple AWS Regions. Part 2 discussed some important characteristics of […]

Build resilient applications with Amazon DynamoDB global tables: Part 2
In the first post of this series, you learned about the differences between zonal, Regional, and global services, and how they affect theoretical application availability. In this post, you’ll learn more about some important Amazon DynamoDB characteristics and how they impact multi-Region design. Properties of DynamoDB tables in a single Region DynamoDB is a NoSQL […]

Build resilient applications with Amazon DynamoDB global tables: Part 1
Customers that need to build resilient applications with the lowest possible recovery time objective (RTO) and recovery point objective (RPO) want to make the best use of AWS global infrastructure to support their resilience goals. Building an application using multiple Availability Zones in a single AWS Region can provide high levels of availability, but you […]

Best practices to deploy Amazon Aurora databases with AWS CloudFormation
Many organizations prefer infrastructure as code (IaC) for provisioning and maintaining IT infrastructure. With IaC, you can replicate DevOps practices for application code such as storing the infrastructure code in a source control system, automated testing, and automated deployment through a continuous integration and continuous delivery (CI/CD) pipeline. AWS CloudFormation is an IaC service that […]

IPv6 addressing with Amazon RDS
We all have our own individual identity in this world. It may be a home address or unique ID card number. But have you ever considered how you are perceived online? Generalizing, have you ever considered how complex or large a system should be to accommodate all unique identifiers around the world, considering devices also […]

Amazon Aurora PostgreSQL backups and long-term data retention methods
When operating relational databases, the need for backups and options for retaining data long term is omnipresent. This is especially true for many users of Amazon Aurora PostgreSQL-Compatible Edition. Although AWS-native, PostgreSQL-native, and hybrid solutions are available, the main challenge lies in choosing the correct backup and retention strategy for a given use case. In […]
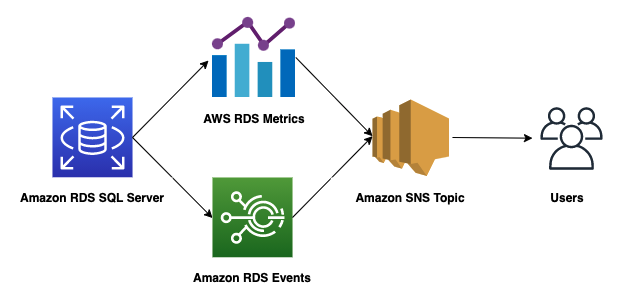
Best Practices on how to configure Monitoring and Alerts for Amazon RDS for SQL Server: Part 2
AWS provides multiple tools, techniques and metrics to monitor and alarm on, giving you a view over what is going on in the Amazon Relational Database Service (Amazon RDS) for SQL Server and how to optimize the operation and performance of RDS for SQL Server Instance. In our previous post, we presented an overview of […]
Best Practices on how to configure Monitoring and Alerts for Amazon RDS for SQL Server: Part1
Database monitoring is the process of measuring and tracking database performance. The performance is measured by analyzing certain key metrics at the Database level and Operating System level. Effective database monitoring and timely alerting also gives you an opportunity to enhance or optimize your database, to augment overall performance and minimize downtime. AWS provides multiple tools, […]
Avoid PostgreSQL LWLock:buffer_content locks in Amazon Aurora: Tips and best practices
We have seen customers overcoming rapid data growth challenges during 2020–2021.For customers working with PostgreSQL, a common bottleneck has been due to buffer_content locks caused by contention of data in high concurrency or large datasets. If you have experienced data contentions that resulted in buffer_content locks, you may have also faced a business-impacting reduction of […]