AWS Database Blog
Tag: RDS PostgreSQL

Common administrator responsibilities on Amazon RDS and Amazon Aurora for PostgreSQL databases
Amazon Web Services (AWS) offers Amazon Relational Database Service (RDS) and Amazon Aurora as fully managed relational database services. With a few commands, you can have your production database instance up and running on AWS. An online database frees the database administrator (DBA) from many maintenance and management tasks. However, there are a few significant […]

Migrating legacy PostgreSQL databases to Amazon RDS or Aurora PostgreSQL using Bucardo
If you are using PostgreSQL earlier than 9.4, you are using an unsupported version of PostgreSQL, and may have limited options to migrate or replicate your databases in Amazon RDS or Amazon Aurora PostgreSQL. This is primarily because PostgreSQL versions older than 9.4 can’t perform logical replication. Bucardo is an open-source utility that can replicate […]
Best practices for upgrading Amazon RDS to major and minor versions of PostgreSQL
This post was last reviewed and update June, 2022 to update the upgrade steps for Amazon RDS. Open-source PostgreSQL occasionally releases new minor and major versions that include fixes for frequently encountered bugs, security issues, and data corruption problems. Generally, Amazon RDS aims to support new engine versions within five months of their availability. You […]

Securing Amazon RDS and Aurora PostgreSQL database access with IAM authentication
AWS provides two managed PostgreSQL options: Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. Both support IAM authentication for managing access to your database. You can associate database users with IAM users and roles to manage user access to all databases from a single location, which avoids issues caused by permissions being out of sync […]

Migrating databases using RDS PostgreSQL Transportable Databases
April 2023: This post was reviewed and updated with a new section on Limitations Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports the feature Transportable Databases, a high-speed data import and export method supported on versions 11.5 and later and 10.10 and later. If you need to import a PostgreSQL database from one […]

Dive into new functionality for PostgreSQL 11
In this post, I take a close look at three exciting features in PostgreSQL 11: partitioning, parallelism, and just-in-time (JIT) compilation. I explore the evolution of these features across multiple PostgreSQL versions. I also cover the benefits that PostgreSQL 11 offers, and show practical examples to point out how to adapt these features to your applications.
Working with RDS and Aurora PostgreSQL logs: Part 2
July 2023: This post was reviewed for accuracy. The first post in this series, Working with RDS and Aurora PostgreSQL Logs: Part 1, discussed the importance of PostgreSQL logs and how to tune various parameters to capture more database activity details. PostgreSQL logs provide useful information when troubleshooting database issues. This post focuses on different […]

Optimizing and tuning queries in Amazon RDS PostgreSQL based on native and external tools
January 2024: This post was reviewed and updated for accuracy. PostgreSQL is one of the most popular open-source relational database systems. The product of more than 30 years of development work, PostgreSQL has proven to be a highly reliable and robust database that can handle a large number of complicated data workloads. PostgreSQL is considered […]
Best practices for migrating an Oracle database to Amazon RDS PostgreSQL or Amazon Aurora PostgreSQL: Target database considerations for the PostgreSQL environment
An Oracle to PostgreSQL migration in the AWS Cloud can be a complex multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. This blog post is the third in a series that discusses high-level aspects about the components to consider for a database migration. The series doesn’t […]
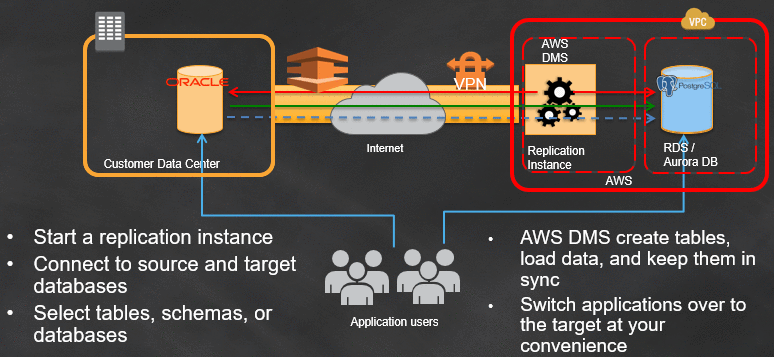
Best practices for migrating an Oracle database to Amazon RDS PostgreSQL or Amazon Aurora PostgreSQL: Source database considerations for the Oracle and AWS DMS CDC environment
An Oracle to PostgreSQL migration in AWS Cloud can be a complex multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. To better understand details of the complexities involved, see the AWS Database Blog post Database Migration—What Do You Need to Know Before You Start? This blog […]