AWS HPC Blog
Category: AWS ParallelCluster

Introducing AWS ParallelCluster multiuser support via Active Directory
Today we’re announcing the release of AWS ParallelCluster 3.1 which now supports multiuser authentication based on Active Directory (AD). Starting with v3.1.1 clusters can be configured to use an AD domain managed via one of the AWS Directory Service options like Simple AD or AWS Managed Microsoft AD (MSAD). This blog post describes the new feature, and gives an example of a configuration block for ParallelCluster 3 configuration files.

Using the ParallelCluster 3 Configuration Converter
ParallelCluster 3 was a major release with several changes and a lot of new features. To help get you started migrating your clusters, we describe the config file converter tool which is part of the ParallelCluster (>= v3.0.1) command line interface (CLI).

Using Spot Instances with AWS ParallelCluster and Amazon FSx for Lustre
Processing large amounts of complex data often requires leveraging a mix of different Amazon EC2 instance types. These types of computations also benefit from shared, high performance, scalable storage like Amazon FSx for Lustre. A way to save costs on your analysis is to use Amazon EC2 Spot Instances, which can help to reduce EC2 costs up to 90% compared to On-Demand Instance pricing. This post will guide you in the creation of a fault-tolerant cluster using AWS ParallelCluster. We will explain how to configure ParallelCluster to automatically unmount the Amazon FSx for Lustre filesystem and resubmit the interrupted jobs back into the queue in the case of Spot interruption events.

Custom AMIs with ParallelCluster 3
This blog post shows how you can create and manage custom AMI images for AWS ParallelCluster 3 using the new AMI creation and management process, which is built using EC2 Image Builder.
How to manage HPC jobs using a serverless API
HPC systems are traditionally access through a Command Line Interface (CLI) where the users submit and manage their computational jobs. Depending on their experience and sophistication, the CLI can be a daunting experience for users not accustomed in using it. Fortunately, the cloud offers many other options for users to submit and manage their computational jobs. In this blog post we will cover how to create a serverless API to interact with an HPC system in the the cloud built with AWS ParallelCluster.

Using the Slurm REST API to integrate with distributed architectures on AWS
The Slurm Workload Manager by SchedMD is a popular HPC scheduler and is supported by AWS ParallelCluster, an elastic HPC cluster management service offered by AWS. Traditional HPC workflows involve logging into a head node and running shell commands to submit jobs to a scheduler and check job status. Modern distributed systems often use representational […]
Deep dive into the AWS ParallelCluster 3 configuration file
In September, we announced the release of AWS ParallelCluster 3, a major release with lots of changes and new features. To help get you started migrating your clusters, we provided the Moving from AWS ParallelCluster 2.x to 3.x guide. We know moving versions can be a quite an undertaking, so we’re augmenting that official documentation with additional color and context on a few key areas. With this blog post, we’ll focus on the configuration file format changes for ParallelCluster 3, and how they map back to the same configuration sections for ParallelCluster 2.
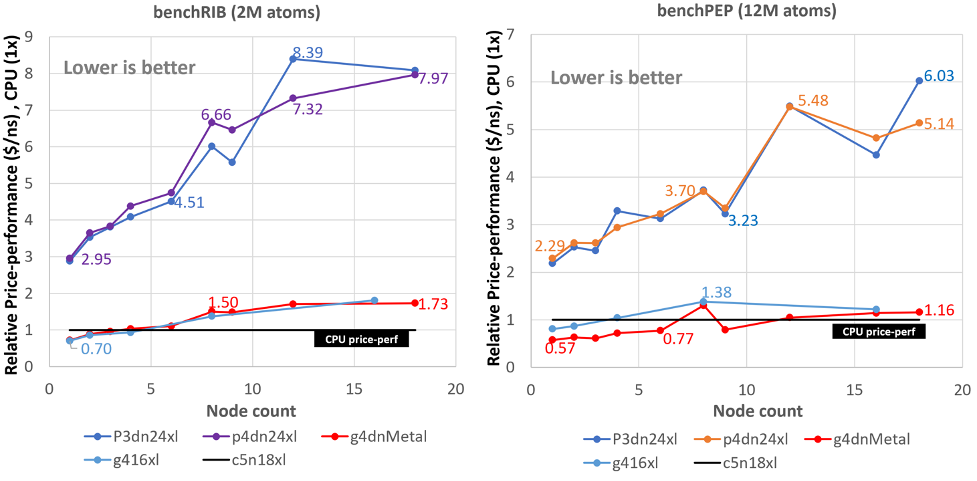
Running GROMACS on GPU instances: multi-node price-performance
This three-part series of posts cover the price performance characteristics of running GROMACS on Amazon Elastic Compute Cloud (Amazon EC2) GPU instances. Part 1 covered some background no GROMACS and how it utilizes GPUs for acceleration. Part 2 covered the price performance of GROMACS on a particular GPU instance family running on a single instance. […]

Running the Harmonie numerical weather prediction model on AWS
The Danish Meteorological Institute (DMI) is responsible for running atmospheric, climate and ocean models covering the kingdom of Denmark. We worked together with the DMI to port and run a full numerical weather prediction (NWP) cycling dataflow with the Harmonie Numerical Weather Prediction (NWP) model to AWS. You can find a report of the porting and operational experience in the ACCORD community newsletter. In this blog post, we expand on that report to present the initial timing results from running the forecast component of Harmonie model on AWS. We also present these as-is timing results together with as-is timings attained on the supercomputing systems based on Cray XC40 and Intel Xeon based Cray XC50.

Cost-optimization on Spot Instances using checkpoint for Ansys LS-DYNA
A major portion of the costs incurred for running Finite Element Analyses (FEA) workloads on AWS comes from the usage of Amazon EC2 instances. Amazon EC2 Spot Instances offer a cost-effective architectural choice, allowing you to take advantage of unused EC2 capacity for up to a 90% discount compared to On-Demand Instance prices. In this post, we describe how you 0can run fault-tolerant FEA workloads on Spot Instances using Ansys LS-DYNA’s checkpointing and auto-restart utility.