AWS HPC Blog
Numerical weather prediction on AWS Graviton2
This post was contributed by Matt Koop, Principal Solutions Architect, HPC and Karthik Raman, Senior Solutions Architect, HPC
The Weather Research and Forecasting (WRF) model is a numerical weather prediction (NWP) system designed to serve both atmospheric research and operational forecasting needs. The WRF model serves a wide range of meteorological applications across scales ranging from meters to thousands of kilometers. WRF is one of the most widely used NWP models both in academia and industry with over 48,000 registered users spanning over 160 countries.
With the release of Arm-based AWS Graviton2 Amazon Elastic Compute Cloud (EC2) instances, a common question has been how these instances perform on large-scale NWP workloads. In this blog, we will present results from a standard WRF benchmark simulation and compare across three different instance types.
Amazon EC2 for NWP
AWS Graviton2 processors are custom built by AWS using the 64-bit Arm Neoverse cores to deliver great price performance for cloud workloads running in Amazon EC2. These instances are powered by 64 physical core AWS Graviton2 processors that use 64-bit Arm Neoverse N1 cores and custom silicon designed by AWS, built using advanced 7-nanometer manufacturing technology.
As NWP models often benefit from high-speed networking, we will evaluate the C6gn.16xlarge (64-core Graviton2-based instance) and the C5n.18xlarge (36-core Intel Skylake-based instance). Both of these instances have 100-Gbps networking bandwidth and have support for Elastic Fabric Adapter (EFA). To identify the performance achieved through the increased networking capabilities of C6gn, we also evaluate the C6g. The C6g instance has the same characteristics as the C6gn instance aside from the increased network capabilities.
WRF benchmarking case
The benchmark case used for this blog is the UCAR CONUS 2.5km dataset for WRFv4. We use the first 3 hours of this 6-hour simulation, 2.5 km resolution case covering the Continental U.S (CONUS) domain from November 2019 with a 15-second time step and total of around 90M grid points. Note that in the past, WRFv3 has commonly been benchmarked using a similar CONUS 2.5 km dataset, however, WRFv3 models are not compatible with WRFv4. Despite the similar name, this is a different model than that dataset.
Key performance elements
When benchmarking an application across different architectures, you must pay attention to several factors to minimize confounding factors in your analysis.
Balancing of MPI ranks to OpenMP threads: When running an application that includes parallelization with both MPI and OpenMP, such as WRF, it is important to determine the appropriate ratio of MPI tasks to OpenMP threads that should run on each instance. This ratio will often change depending on the application, the specific workload being run, and the scale. Due to differences in CPU architectures, including caches, these ratios often change based on the architecture used.
Compiler selection can impact performance: As has been noted in other studies (https://www2.cisl.ucar.edu/resources/optimizing-wrf-performance), WRF performance can vary significantly by compiler selection. To evaluate the impact of this, we will evaluate both the ARM compiler (20.3) and GCC 10.2 on the AWS Graviton2-based instances. On the C5n instance, powered by Intel Skylake, we will evaluate using both the Intel 19.1 compiler suite and GCC 10.2.
I/O performance: WRF provides several different options for the I/O layer such serial NetCDF, Parallel NetCDF, Asynchronous I/O, and others. Based on the case attributes and scale, WRF can be sensitive to I/O performance and therefore using other I/O layers can help. In this blog, we focus on the compute performance and as such have enabled the default serial NetCDF option. For improved I/O performance, we have used Amazon FSx for Lustre, a fully managed high-performance Lustre file-system service.
Single-instance performance
Before moving to address the impact of the network, we run the CONUS 2.5 km dataset across single instances. For each instance type we have evaluated multiple combinations with a different compiler version and ratio of MPI ranks and OpenMP threads. On Graviton2-based instances with 64 physical cores, the number of MPI tasks multiplied by the number of OpenMP threads is always equal to 64. Similarly, on the C5n.18xlarge, which has 36 physical cores (two sockets, each with 18 physical cores), it will always reach 36 cores. The performance metric used here is Simulation Speed, which is the duration of simulation completed per wall-clock time. Figure 1 shows the results of this evaluation.

Figure 1: Comparison of single instance performance
- C6gn: We see that performance is similar (within 3% in all cases) between GCC 10.2 and the ARM 20.3 compiler on a single instance. There’s a slight advantage on a single node to using 16 or 32 MPI ranks per node as well.
- C5n: The performance differential between the Intel compiler suite and GCC 10.2 is more substantial on this instance, with the Intel compiler performing 15–20% faster in these scenarios.
Comparing across the instances, the c5n.18xlarge has a performance advantage over the c6gn on a single instance, of approximately 5% in this test case.
The results we present should not be considered the best possible, but rather results using standard optimized defaults of compiler flags. Further, these results will change considerably based on a number of factors depending on application, scale, processor generation, and specific flags used.
For the remainder of the test, we will use the highest performing compiler in each case. This means GCC 10.2 for all Graviton2 (C6g and C6gn) measurements and the Intel compiler for C5n instance measurements.
Multi-Instance performance
To better understand the difference that the enhanced networking of the c6gn instance, we evaluate the same benchmark scaling out to 112 instances. Both the C6gn.16xlarge and C5n.18xlarge include EFA capabilities and 100 Gbps per instance to allow for highly scalable internode communication. The C6g instance uses a 25-Gbps connection using Elastic Network Adapter (ENA) and TCP/IP. All instances used in a job were launched as part of a compute placement group, which maximizes network performance between the instances of the group. In all cases, we used Open MPI 4.1.0.
Figure 2 shows the results of the evaluation across each of the three instances. We show the same results in two formats, one based on the number of instances (left) and the other based on the number of cores (right).

Figure 2: Comparison of Multi- instance performance
When comparing at an instance level, the C6g.16xlarge instance performed similarly to the other two instances until 16 instances, scaling further saw a drop in scaling efficiency due to the increased network communication. At 112 instances, the performance of both C5n and C6gn is approximately 30% higher than C6g, showing the value of EFA and the increased network capacities.
The performance by number of cores graph (on the right) differs in appearance as the C5n.18xlarge has 36 physical cores and the Graviton2-based instances (C6g, C6gn) have 64 physical cores. At a given core count, it is running more C5n.18xlarge instances (36 cores per instance) compared to C6g.16xlarge/C6gn.16xlarge instances (64 cores per instance). From the charts, we observe that on a per-core basis the C5n.18xlarge has a nearly 70% advantage at 4,600 cores, however, on a number of instances basis the performance is near identical.
Multi-instance performance for C6gn and C5n closely match each other, showing results similar to what was seen on a single instance. They also show nearly linear scaling behavior out to the 112 instances that we evaluated.
Price-Performance
While performance is a key metric, the cost to run a simulation is also a major consideration. Using recent pricing from the US East (N. Virginia) Region, we have plotted the cost of the core simulation vs the simulation speed (speedup compared to real time) that is obtained for that cost. This only includes time spent doing the compute portion of the application and excludes I/O time, which can vary based on selections of desired output attributes, I/O libraries, and filesystems used.
As shown in Figure 3, C6g provides a significant savings at lower simulation speeds (a ~40% savings compared to C5n.18xlarge at a simulation speed near 16) and when a faster simulation speed is desired the C6gn.16xlarge provides the most performance at the least cost (a savings of 30% compared to C5n.18xlarge at a simulation speed of 100). At lower simulation speeds (and lower instance counts), the lower-cost C6g.16xlarge is most price/performance efficient as the simulation does not take advantage of the high-speed networking that the C6gn.16xlarge offers. At larger scales, as each instance has fewer grid points to process and networking is more critical to performance the C6gn instances have a higher price/performance efficiency.
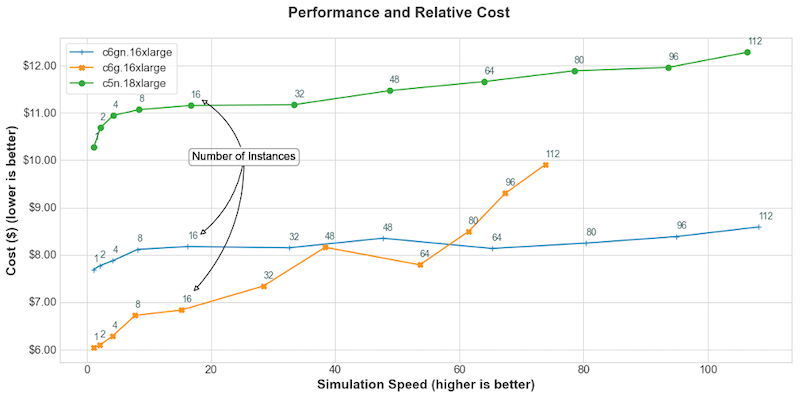
Figure 3: Performance and cost of simulation.
Summary
In this blog, we have demonstrated the performance of running single-node and large-scale multi-node NWP simulation using WRF on Amazon EC2 C6g/C6gn instances powered by Arm-based AWS Graviton2 processors. There is up to a 40% price-performance advantage running these NWP simulations on Arm-based AWS Graviton2 (C6g/C6gn) instances compared to Intel-based C5n instances. Even the turn-around time (as measured by simulation speed) on C6gn is nearly identical with the C5n instances, thanks to the high-speed network provided by EFA. We encourage you to test your HPC applications on the Arm-based AWS Graviton2 instances and contact us if you have any questions!