AWS for Industries
How Cloud-based Data Mesh Technology Can Enable Financial Regulatory Data Collection
Background
Central banks and financial regulators depend on access to high-quality, up-to-date data from regulated financial institutions such as banks and insurance companies. These regulated entities have widely varying and changing operational environments, each operating independently, but must coordinate with the regulator to exchange relevant data. Today, the costs incurred by banks in supporting regulators’ requests for data are very high. For example, the Bank of England refer to a study by McKinsey and Company in 2019 which estimated that UK banks spent between £2 billion–£4.5 billion per year on regulatory reporting.
Modern cloud technology already has a track record of enabling valuable insights in a cost-efficient manner, by pooling data and carrying out analytics using data warehouse and big data tools. For example using big data analytics tools such as Amazon EMR to consolidate data from securities trading to enable enhanced risk management. For regulators, the challenge is to be able to gain insights and valuable information from analyzing a variety of large datasets in a controlled, highly flexible, and cost-effective manner. As markets evolve and economic risks change, the demands from regulators and central banks will also change, hence the regulatory ecosystem must continue to be adaptive and cost-effective for all participants.
Introducing the Data Mesh
In an article published by martinFowler.com: ”How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh,” Zhamak Dehghani explains some of the reasons for the need to adopt a new approach to data-centric systems. Dehghani argues that each generation of “data platforms” has resulted in a centralized monolith that ignores the individual needs of producers – such as the departments within a large organization – in terms of how they can best structure their data for their business purposes. While this can work for organizations with straightforward business models, this becomes increasingly problematic for more complex enterprises as data lineage and governance issues become increasingly difficult to manage. The problem is even more severe for an ecosystem of independent parties such as the one involved in regulatory reporting and data gathering.
Cloud technology used in conjunction with the “data mesh” concept provides a promising approach to solving regulatory reporting problems. Data meshes naturally address the data ownership, governance, and lineage issues associated with a federated regulatory ecosystem. In a data mesh approach, each data producer (such as a commercial bank) independently maintains and updates its published data. Only when the bank chooses to “publish” a new version of the dataset are changes made visible to subscribed data consumers (such as an FSI regulator). Each producer controls the structure of each published dataset and this structure is described by a data schema. Meanwhile, the data consumers may gather published data from multiple data producers (such as from each bank under the regulator’s jurisdiction). The consumer may then use a diverse set of cloud technologies to populate data lakes or data warehouses as required. Hence, in a flexible and cost-efficient manner, a regulatory data mesh enables regulated entities to “bridge the gap” between their people, processes, and the systems that produce the data.
A key enabler of this data mesh approach is the use of self-describing data. We might envision a data ecosystem with multiple data producers and consumers, based on a centrally defined data schema. However, keeping all participants in strict data lockstep is not realistic given the wide variety of internal IT systems that data producers operate – the approach would be both costly to enforce and extremely brittle to ongoing change. Instead, the solution to this problem is for each producer to create an embedded data schema that describes the current structure of each published dataset. In a regulatory ecosystem, this metadata might describe the data by reference to standard nomenclature and set of data fields defined by the regulator such as those defined in the “Banks Integrated Reporting Dictionary” (BIRD) and the European System of Central Banks’ (ESCB) Integrated Reporting Framework (IReF). So long as they adhere to the mandated nomenclature and provide all of the required data fields, the data producer is free to adopt their own data schema. Then whenever a producer makes changes to the content or structure of a dataset, these changes are reflected in the embedded data schema.
Outline Implementation Approach
AWS Data Exchange provides the foundations needed for creating these secure multi-party data mesh environments. Using the AWS Data Exchange “Private” publishing option, only specific data consumers (such as the regulator) authorized by a producer, will be able to see the data product and subscribe to it. Each published view on AWS Data Exchange is versioned, so there is an auditable data change record available to the consumer. The consumer can access this self-describing data and use tools (such as AWS Glue) to transform it into the required format for down-stream processing via a data warehouse, database, or data lake.
The recent blog Analyzing COVID-19 Data demonstrates the power of using AWS Data Exchange in this way. In this example, AWS together with AWS Partners Salesforce, Tableau, and MuleSoft brought together trusted sources of COVID-19 data to enable it to be shared with interested third parties via AWS Data Exchange. This has enabled data consumers to extract relevant data into their analytics data lakes, pulling and transforming data as required. New versions of the data can be made available at any time by the relevant data producer within AWS Data Exchange, and the availability of these new versions are communicated to all data consumers. This resource is made available publicly to support organizations in their COVID relief efforts. In other use cases, access can alternatively be strictly limited by using AWS Identity and Access Management controls.
A conceptual overview of a federated regulatory reporting data mesh environment is shown in Figure 1; where each regulated bank is an AWS Data Exchange data producer and each regulator an AWS Data Exchange data consumer.
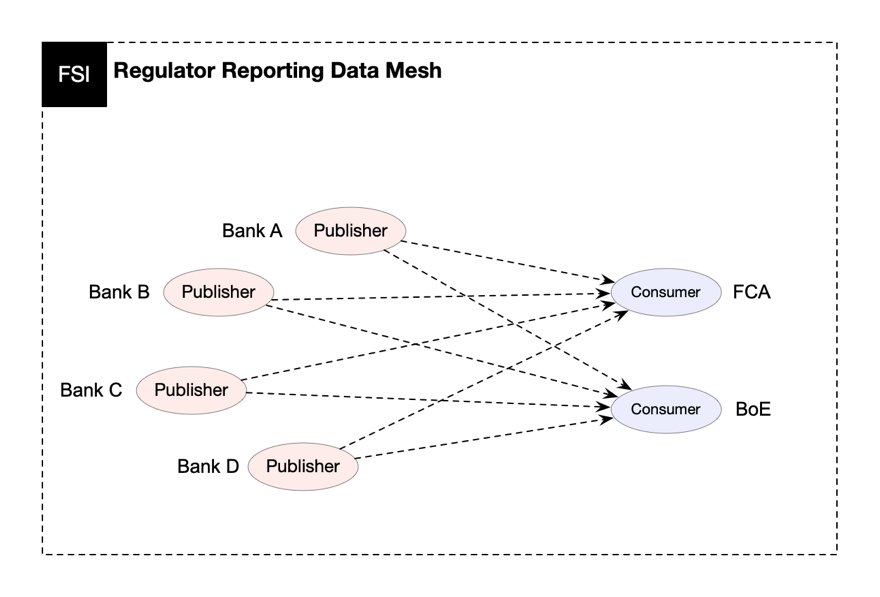
Figure 1: Regulator reporting data mesh
The implementation of such an environment illustrated in Figure 2 is comprised of the following stages:
- Regulated banks (AWS Data Exchange data producers) curate and upload required data artifacts creating their AWS Data Exchange regulatory reporting data product. See AWS Data Exchange best practices.
- When appropriate or required, each data producer publishes a new revision of their reporting data product (such as regulatory data). This newly published revision may include only data that has changed, all data, or all data and full change history. A revision may be created and published by each data producer at any time.
- The regulator (the data consumer) receives notice of updates which they can act upon at their discretion, pulling the revision into their reporting analytics infrastructure when needed. As revisions from each data producer are self-describing, it is a simple process to map these diverse sources into the consumer’s normalized data structure.
- The normalized data may be analyzed using a range of tools and techniques to search for specific information or extract insights. Options include graph relationship analysis (Amazon Neptune), AI/ML pattern recognition (Amazon SageMaker), traditional data warehouse search/queries (Amazon Redshift or Amazon Athena), and report generation.
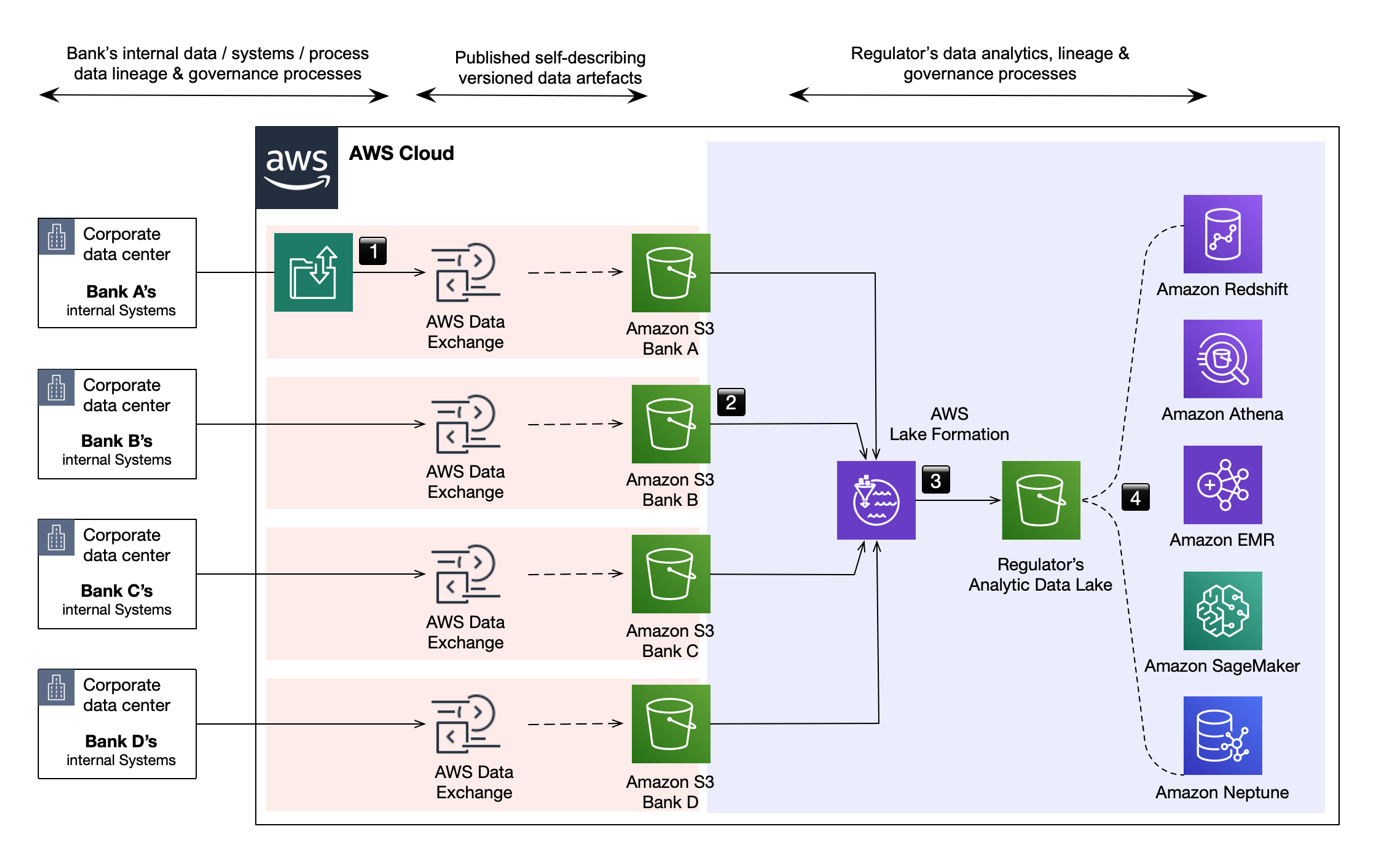
Figure 2: Sample implementation of a federated regulatory reporting data mesh environment
Opportunities and Benefits
The AWS Data Exchange approach could be used as the basis for a highly adaptive and scalable “common input layer” which is seen as a desirable attribute by regulators (see for example the Bank of England’s consultation on “Transforming Data Collection,”released on January 2020). One of the considerations discussed in the paper is whether the common input layer should adopt a “push” or “pull” approach (for example regulated entities either “pushing” data to the regulator on request) or, when required, the regulator “pulls” the data from each regulated entity. The regulatory data mesh architecture provides the advantages of both approaches. It provides the benefit of a “push” system for the data producer, abstracting the complexities of their own underlying IT systems and the timing of their updates without the need to coordinate with the regulator directly. It also allows the regulator to “pull” the data that they need when they need it, thereby freeing each bank from the burden of having to continually produce new reports or data extracts in response to regulator requests.
It also provides further advantages for both parties. The data producer has a local data repository which has potential value for the data producer as a reference data store and doesn’t carry the burden of having to continually produce new reports or data extracts in response to regulator requests. And the regulator has the advantage of being able to create new combined datasets and analyze them on demand without having to build a permanent centralized data lake.
Conclusion
The volume, timeliness, and accuracy of data which regulators need to collect to meet their regulatory objectives places challenges on regulators and regulated firms. There are, however, practical solutions to many of the business issues faced that can be developed securely, cost effectively, and scalably using cloud technology. In particular we believe that all parties can benefit from the application of data mesh technologies such that the burden of data collection can be reduced for large and small organizations alike in a way which is sufficiently flexible to adapt to changing requirements.
Cloud-based data mesh technology can also be successfully applied to a wide range of other data management requirements, from ingesting third party and public data to help inform internal decision making, to ensuring consistency between internal datasets. This is just one of the ways that the cloud is changing the way businesses look at some of the hardest data challenges they face and helping them to create more agile and sustainable solutions as a result.
To learn more about how cloud can help to enable improvements in regulatory reporting and data collection contact:
Richard Caven
Financial Services Specialist
rcaven@amazon.com
David MacKeith
Technical Business Development Manager
dmmackei@amazon.com