AWS for Industries
How natural language processing can uncover value from unreachable data in the modern medical ecosystem
The Dark Data Problem
Up to 80% of your organization’s medical patient data is untapped, undervalued, or unused
Imagine walking into a physician’s office for a checkup. As you describe some pain you’ve been having in your left knee, the doctor barely looks up from the screen as she clatters away on the keyboard, taking notes. After she resolves your concern and you leave, she will spend another 11 minutes, on average, documenting your visit in the electronic health record (EHR) system. While driving home, you wonder how (or even if) those notes are really used to take care of you.
Dark data is vastly underutilized
The truth is that those notes, along with other free-form or unstructured pieces of medical data, are not fully utilized. Though care providers spend hours each day forming notes, their use only approaches a small fraction of their potential. They belong to a collection of data that researchers and industry experts label “dark data.” A 2016 study estimated that 52% of all data stored and processed globally is dark data, meaning that the value of the data is unknown and unrealized. For the medical field specifically, an oft-cited statistic pegs the amount of dark data as high as 80%. As data volumes and types continue to increase, this number is expected to rise.
Forward-thinking medical executives look for effective ways to extract value from medical dark data. Unstructured data such as that from progress notes, referral notes, and operation notes are a goldmine of rich patient data. They can provide a clinician with more complete context for a patient’s care, aid in decreasing research time or cost, ensure accurate billing, or save time for busy clinicians.
Data typically not collected or under-collected in structured fields include patient-reported symptoms, provider-observed signs, tumor size, cancer staging, detailed information about a diagnosis or procedure, medical/family history, social determinants, details of current or past medical conditions.
Current solutions are insufficient
Those who have recognized the value of the data contained in unstructured notes have tried various methods of extraction, including manual extraction, pattern matching, and self-trained natural language processing (NLP) algorithms. While each has varying degrees of effectiveness, each method is ultimately insufficient for meeting the goals of today’s healthcare executives.
Manual extraction
The costliest approach to extract information from unstructured fields has traditionally been to ask medical professionals to read through the notes manually. This is often done in research scenarios where the team may not have the technical capabilities to build a more automated approach. Oftentimes, the type of information the research team is looking for is not easily extracted even with traditional technical aptitude, so they must rely on human expertise.
Pattern matching
Pattern matching is a rudimentary way to look for specific phrases or textual patterns in free-form unstructured text. This requires the technical aptitude to build the appropriate queries and data processing infrastructure but is rigid enough to only allow for looking at very specific pieces of data in the set. Frequently this relies on the unstructured notes having a common template and can’t handle fully free-flowing natural text.
Natural language processing with self-trained/self-hosted models
This advanced technology is used by some researchers, but it requires extensive machine learning expertise, as well as access to a large set of training data and large, computes expenditures to train the model. It is the most flexible approach, able to perform best over a wide array of the varied input text. Since patient data is highly regulated, it is very difficult for small institutions to find a set of training data large enough to self-build a general-purpose medical NLP model.
Amazon Comprehend Medical gives speed and flexibility
In late 2018, Amazon released a new managed service called Amazon Comprehend Medical, which improves on the current solutions for extracting unstructured data. Building on top of the existing NLP foundation that Amazon Comprehend provides, Comprehend Medical uses a pre-trained model to extract medical information with high accuracy. Comprehend Medical provides the broad flexibility, speed, and lower marginal cost of earlier NLP solutions but without the requirement of deep machine learning expertise. Additionally, Comprehend Medical provides a general-purpose platform that allows institutions to keep and reuse the structured results, unlike some vendors who focus in one NLP area or whose product does not return reusable information that can be used for further study and analysis.
Share the Vision
Verifying operational value through meaningful use cases can drive adoption
Modern advances in machine learning and natural language processing are inspiring institutions around the country to look for ways to improve patient care, make research efforts more effective and efficient, increase revenue, and reduce costs. These institutions are already seeing huge benefits from incorporating this technology:
- Fred Hutchinson Cancer Research Center used Amazon Comprehend Medical NLP technology to speed the time needed to match patients with clinical trials from hours to seconds.
- A large children’s hospital uses machine learning to identify infectious disease up to three days in advance of normal detection with 70% accuracy.
- Drexel University uses NLP technology to screen for missed billing opportunities for comorbidities treated adjunctly.
- Mercy Health System uses NLP technology to show the life cycle of a heart failure patient and evaluate associated risk factors.
And this list will continue to grow as more and more institutions start reaping the benefit from increasingly accessible NLP technology.
Pariveda conducted a pilot at an academic research hospital
Hearing about the benefits of this technology prompted a large academic research institution to partner with Pariveda Solutions and AWS to pilot a data pipeline in just five weeks based on the cutting-edge Amazon Comprehend Medical service. We took a sample of 1,200 patient encounter notes with the goal of processing them with Comprehend Medical and then evaluating the results with the providers to determine valuable areas in which this technology could make a meaningful impact.
Early adopters explore vision with pilot project
The pilot had three main goals:
- Prove that the technology could be put in place and start producing results quickly by a small, nimble team
- Garner excitement across the organization by showcasing the preliminary results and gaining broad stakeholder buy-in
- Explore additional use cases with potential project stakeholders to determine the highest value areas to focus on first
After building the initial data pipeline, we identified early adopters across the organization to help them understand how extracting unstructured data could aid their organization’s goals. We initially focused on three groups of people:
- Researchers and data owners: Researchers are continually looking for more efficient and effective ways to identify potential study participants. Natural language processing of unstructured progress notes uncovers information such as the reason for a patient’s visit, past medical history, previously reported symptoms, and family history information. Accessing this data allows researchers to more quickly determine prospective participants.
- Physicians: Improving quality of care is top of mind for physicians. We created visuals to emphasize both population-level and individual-patient-level data extracted from medical notes. This dual-prong illustration was instrumental in sparking creative ideas for how to utilize the results for quality measures and patient safety indicators.
- Billing staff: Medical coding continues to grow in complexity every year. The documentation required for each code is often sprinkled through structured and unstructured data. During the pilot, we showed the various diagnoses, signs, and symptoms pulled from the medical note to share how this data might be used to automate or simplify the time-consuming coding process, which reduces the likelihood of inaccurate codes and provides additional revenue opportunities.
Build the Tech
New machine learning tools allow innovative organizations to extract value from previously untapped dark data
The pilot project was built in five weeks and took advantage of a hybrid on-prem and cloud-based architecture. Amazon Comprehend Medical provided the NLP engine, and insights were evaluated using an analytics and reporting tool.
Effectively structure data with hybrid architecture
The straightforward data pipeline architecture that was proven with the pilot consists of the following pieces:
- Data is de-identified first on-prem. A new identifier is assigned to the record to provide continuity and traceability, and all PHI data is maintained within the institution’s secure boundary.
- The records are sent to the cloud where they are queued, processed by Comprehend Medical, and stored. The service is accessible through a simple API call, no machine learning expertise is required, no complicated rules need to be written, and no models need to be trained. The flexible and scalable nature allowed us to design for the multiple use cases we wanted to address.
- An automated process brings structured data back on the premise. It can be linked back to the original data set with the unique identifier.
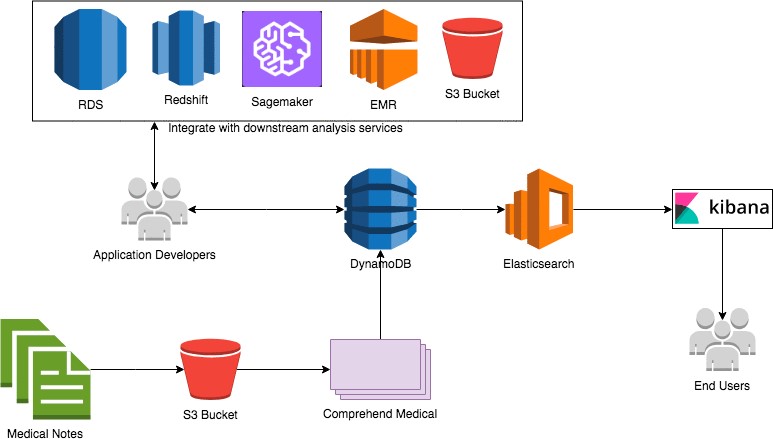
Figure 1 – Sample cloud architecture for cloud structuring
Amazon Comprehend Medical extracts diverse data
The managed service extracts all of the following types of data from an unstructured note:
- Anatomy
- Medical Condition
- Medication
- Protected Health Information
- Test Treatment Procedure

Figure 2 – Sample input/output illustrating Comprehend Medical tagging
New data means new insights
After running unstructured data through this pipeline, the output will be used differently for each use case. For the pilot, we highlighted this new domain of data with an analytics and reporting tool. This allowed us to showcase the capabilities of this technology and allow providers and stakeholders to discover new insights from previously inaccessible data.
Learn the Lessons
The unique healthcare environment adds additional considerations to any successful healthcare-data project
Healthcare has a unique environment that adds additional considerations to any successful healthcare-data project. Below are some of the dimensions that we considered as part of the pilot project and which will need to be considered for any similar effort.
Ensure patient privacy is top priority
The Health Insurance Portability and Accountability Act (HIPAA) was passed in 1996 to safeguard patient privacy. Organizations are rightly concerned with the benefits of HIPAA to patients as well as the reputational and financial risk of a potential privacy violation. For this reason, the organization we worked with required complete de-identification of all personal health information (PHI) before allowing the data outside the on-premise environment and into the cloud.
HIPAA provides for two methods to de-identify PHI in order to render it safe for use outside of a highly restricted environment: expert determination and safe harbor. The method most suitable for use in an automated fashion is the safe harbor method.
The safe harbor method of de-identification enumerates 18 pieces of sensitive information that must be removed before the data is marked as not containing PHI. An obstacle that often derails the use of unstructured data in non-secure environments is the challenge of providing automated removal of these 18 pieces of sensitive information. Redaction is simple in structured data but complex in unstructured fields.
Since our focus was on unstructured data, we made sure to pick a de-identification solution that would work with it. This involved a combination of open-source and proprietary tools to de-identify records as part of the data pipeline on-prem before leaving the protected environment. This solution involved pattern-matching, natural-language processing, and a backup layer of cloud-based de-identification based on Amazon Comprehend Medical.
Ensuring appropriate data privacy and controls is an essential first step to any medical data project.
Start small, build excitement
Management journals are littered with case studies of projects that began too ambitiously and whose value wasn’t proven before scaling. Our strategy began with a pilot project, then took advantage of periodic small successes to spark excitement across the organization. Through a five-week pilot project, we showcased the potential value to stakeholders across the administration and business, clinic, research, and surgical departments.
As excitement grew, stakeholders shared with other potentially interested parties, and soon additional department heads reached out to discuss potential use cases. Starting small allows value-driven, organic expansion while limiting the complexity, expectations, and overhead of large efforts.
Imagine and move fast with initial data load
The center of patient data will always rightly be the electronic health record (EHR) system. While the EHR does have integration points, we found that using a data warehouse attached to the EHR provided just as much if not more benefit than a direct EHR integration, even though the data was not as fresh. Because our strategy was to start small and build excitement, we primarily focused on historical data and smaller data sets. This information is readily accessible from the data warehousing team and allows the project to move quickly without slowing for focus on integration concerns. Once the value has been shown, integration with the EHR can be accomplished.
Consider suitability of NLP model
As previously mentioned, earlier efforts in using NLP to extract information have been riddled with challenges. It is important to select the appropriate NLP model for the benefits it provides. We selected Amazon’s Comprehend Medical model for this use case because it overcomes these challenges in the following ways:
- Comprehend Medical is built on a proven general-purpose model that has been tuned for years across Amazon’s wide customer base.
- Comprehend Medical was further trained on the highly domain-specific language of the medical field through a wide training set.
- Comprehend Medical is a hosted solution dedicated to continuous improvements by a dedicated team of experts in this area.
- Comprehend Medical has a wider domain of suitability than a model built for one particular use case or discipline. Once the data pipeline is in place it can be used without any adjustments to process data from multiple domains, which encourages quick experimentation and drives down cost.
- Comprehend Medical does not simply provide the output of the use case (e.g., the patients to be contacted as a result of a cohort identification project), but rather the structured underlying data that drives this decision. This means that the same data can be processed once and used for multiple use cases, including new use cases not determined before processing, and the data is fully controlled by the organization.
Discover the Use Cases
Utilize dark data in revenue cycle management, research, clinic, and quality assurance
While we encountered dozens of potential uses while workshopping with stakeholders across the organization, we noticed four themes of value that fit into two primary categories: operational excellence and patient care.
Operational excellence
Increase revenue and reduce risk in revenue cycle management
When uncovered, the information contained in unstructured dark data fields can help refine revenue cycle management by exposing over- or under-coding in billing claims. This leads to a greater first-pass acceptance rate and a lowered risk of fraudulent billing. Eventually, this analysis could be applied to claims in near-real-time.
Currently, medical coding is done using costly manual review and aided, in some institutions, by computer-assisted-coding (CAC) software. A dark data pipeline, like the one we implemented, helps to expand computerized coding assistance to more institutions for a lower cost. It also improves quality. Current toolsets find it challenging to extract diagnoses that can be represented in different ways. For example, “atrial fibrillation” is sometimes written as “AF.” Amazon Comprehend Medical can accurately identify abbreviations, misspellings, and typos in medical text. This reduces the time a medical coder must spend analyzing unstructured notes, decreases the time burden on clinical staff, and improves efficiency.
Improve clinical operations
Clinical operations can also take advantage of dark data. Current clinical decision-making systems use only structured data. With dark data, clinical decision-making systems can be augmented and enhanced with a richer data set, including symptoms, signs, and diagnoses found only in unstructured notes. Provider time can be streamlined by highlighting the most important information before a patient visit or in a hospitalization summary. Unstructured data can provide a needed boost in the continual search for quality and operational improvements.
Patient care
Speed and enhance research efforts
Researchers stand to benefit quickly from a dark data pipeline. One of the most salient uses is to dramatically reduce the cost of using symptoms, signs, medication, and medical history in cohort identification for clinical trials or studies. One of Comprehend’ s pilot organizations reduced the amount of time it took to find suitable participants from hours to seconds — and that’s recognizing that “hours” is already on the quick side for how long most cohort identification phases currently take. Because some study requirements, such as family history or social indicators, do not have a dedicated field or are recorded in a form that is not easily accessible, natural language processing is a perfect fit. This leads to finding more eligible participants in days rather than months, accelerating study timelines, freeing time and funds available for analysis, and ultimately leading to higher-quality studies. These benefits translate into improved healthcare for patients.
Enrich quality assurance measures
Unlocked unstructured data increases the quality of patient care by facilitating iterative reduction and avoidance of side effects through data-driven quality efforts. In addition, data warehouse owners can augment existing data stores and cross-reference existing data with additional depth from unstructured fields. This allows analytics teams to have the most up to date and highest quality data for running reports and driving operational decision-making.
Conclusion
As machine learning and natural language processing continue to mature and new use cases are refined and introduced, forward-thinking healthcare executives need to understand and look for ways to utilize these tools to drive better outcomes for their organization and for their patients. Our experience building and validating a dark data extraction pipeline shows that with a small amount of investment, large gains can be realized in improved patient care, speedier research efforts, increased revenue, and lower cost.