Artificial Intelligence
Category: Amazon Textract

Increase your content reach with automated document-to-speech conversion using Amazon AI services
Reading the printed word opens up a world of information, imagination, and creativity. However, scanned books and documents may be difficult for people with vision impairment and learning disabilities to consume. In addition, some people prefer to listen to text-based content versus reading it. A document-to-speech solution extends the reach of digital content by giving […]

Specify and extract information from documents using the new Queries feature in Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract now offers the flexibility to specify the data you need to extract from documents using the new Queries feature within the Analyze Document API. You don’t need to know the structure of the […]
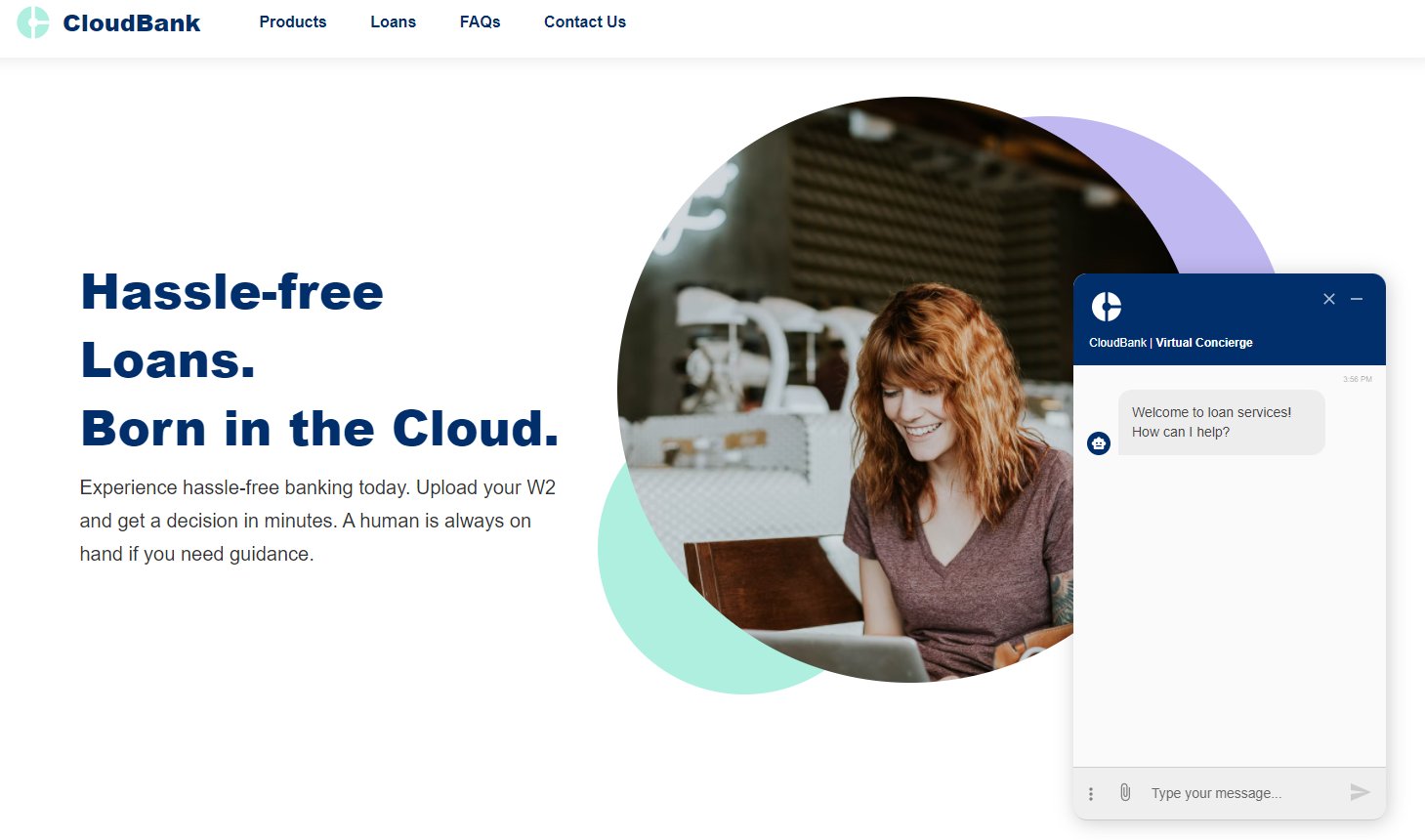
Build a virtual credit approval agent with Amazon Lex, Amazon Textract, and Amazon Connect
Banking and financial institutions review thousands of credit applications per week. The credit approval process requires financial organizations to invest time and resources in reviewing documents like W2s, bank statements, and utility bills. The overall experience can be costly for the organization. At the same time, organizations have to consider borrowers, who are waiting for […]

Enable Amazon Kendra search for a scanned or image-based text document
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization. Amazon Kendra supports a variety of document formats, […]

Build a traceable, custom, multi-format document parsing pipeline with Amazon Textract
Organizational forms serve as a primary business tool across industries—from financial services, to healthcare, and more. Consider, for example, tax filing forms in the tax management industry, where new forms come out each year with largely the same information. AWS customers across sectors need to process and store information in forms as part of their […]

Automate digitization of transactional documents with human oversight using Amazon Textract and Amazon A2I
In this post, we present a solution for digitizing transactional documents using Amazon Textract and incorporate a human review using Amazon Augmented AI (A2I). You can find the solution source at our GitHub repository. Organizations must frequently process scanned transactional documents with structured text so they can perform operations such as fraud detection or financial […]

Enable the visually impaired to hear documents using Amazon Textract and Amazon Polly
At the 2021 AWS re:Invent conference in Las Vegas, we demoed Read For Me at the AWS Builders Fair—a website that helps the visually impaired hear documents. For better quality, view the video here. Adaptive technology and accessibility features are often expensive, if they’re available at all. Audio books help the visually impaired read. Audio […]

Extract entities from insurance documents using Amazon Comprehend named entity recognition
Intelligent document processing (IDP) is a common use case for customers on AWS. You can utilize Amazon Comprehend and Amazon Textract for a variety of use cases ranging from document extraction, data classification, and entity extraction. One specific industry that uses IDP is insurance. They use IDP to automate data extraction for common use cases such as claims intake, […]

Announcing support for extracting data from identity documents using Amazon Textract
Creating efficiencies in your business is at the top of your list. You want your employees to be more productive, have them focus on high impact tasks, or find ways to implement better processes to improve the outcomes to your customers. There are various ways to solve this problem, and more companies are turning to […]

Postprocessing with Amazon Textract: Multi-page table handling
Amazon Textract is a machine learning (ML) service that automatically extracts printed text, handwriting, and other data from scanned documents that goes beyond simple optical character recognition (OCR) to identify and extract data from forms and tables. Currently, thousands of customers are using Amazon Textract to process different types of documents. Many include tables across […]