Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines enterprise search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization. With Amazon Kendra, you can stop searching through troves of unstructured data and discover the right answers to your questions, when you need them.
Although Amazon Kendra is a great search tool, it only performs as well as the quality of documents in its index. Like with all things AI/ML related, the better the quality of data that is input into Amazon Kendra, the more targeted and precise the search results. So how can we improve the documents in our Amazon Kendra index to maximize search result performance? To allow Amazon Kendra to return more targeted search results, we enrich the documents with metadata to use attributes such as main language, named entities, key phrases, and more.
In this post, we address the following use case: With large amounts of raw historical documents to search on, how do we connect metadata to the documents to take advantage of Amazon Kendra’s boosting and filtering features? We aim to demonstrate a way in which you can enrich your historical data by adding metadata to searchable documents with Amazon Textract and Amazon Comprehend, to get more targeted and flexible searches with Amazon Kendra.
Note that the following tutorial is written using Amazon SageMaker Notebooks as a code platform. However, these API calls can be done using any IDE of your choice. To save costs, and for the sake of your own familiarity, feel free to use your favorite IDE in place of SageMaker Notebooks to follow along.
Solution overview
For this post, we examine a hypothetical use case for a media entertainment company. We have many documents about movies and television shows and want to use Amazon Kendra to query the data. For demonstration purposes, we pull public data on Wikipedia to create PDF documents that act as our company’s data that we want to query on. We use an Amazon SageMaker notebook instance as our code platform. We use Python, along with the Boto3 Python library, to connect to and use the Amazon Textract, Amazon Comprehend, and Amazon Kendra APIs.
We walk you through the following high-level steps:
- Create our media PDF documents through Wikipedia.
- Create metadata using Amazon Textract and Amazon Comprehend.
- Configure the Amazon Kendra index and load the data.
- Run a sample query and experiment with boosting query performance.
Prerequisites
As a prerequisite, we first set up a SageMaker notebook instance and a Python notebook within it.
Create a SageMaker notebook instance
To create a SageMaker notebook instance, you can follow the instructions in the documentation Create a Notebook Instance, or follow the configuration that we use in this post.
- Create a notebook instance with the following configuration:
- Notebook instance name –
KendraAugmentation
- Notebook instance class – ml.t2.medium
- Elastic inference – None
Next, we create an AWS Identity and Access Management (IAM) role.
- Choose Create a new role.
- Choose Next to create a role.
The role name starts with AmazonSageMaker-ExecutionRole-xxxxxxxx. For this example, we create a role called AmazonSageMaker-ExecutionRole-Kendra-Blog.
- For Root access, select Enable.
- Leave the remaining options at their default.
- Choose Create notebook instance.
You’re redirected to a page that shows that your notebook instance is being created. The process takes a few minutes. When you see a green InService state, the notebook is ready.
Create a Python3 notebook in your SageMaker notebook instance
When your SageMaker instance is ready, choose the version of Jupyter you prefer to use. For this post, we use the original Jupyter notebook as opposed to JupyterLab.

When inside, create a new conda_python3 notebook.
With this, we’re ready to start writing and running Python code. To run the rest of the code that follows, run the following code in the first Jupyter notebook cell to import the necessary modules we need:
# Module Imports
import boto3
import os
As we go through each of the sections, we import other modules as necessary.
Create Media PDF documents through Wikipedia
Run the following code in one of the Jupyter notebook cells to create an Amazon Simple Storage Service (Amazon S3) bucket where we store all the media documents that we search on:
# Instantiate Amazon S3 client.
s3_client = boto3.client('s3')
# Create bucket.
bucket_name = "kendra-augmentation-documents-jp"
s3_client.create_bucket(Bucket=bucket_name)
# List buckets to make sure bucket was created.
response = s3_client.list_buckets()
print('Existing buckets:')
for bucket in response['Buckets']:
print(f' {bucket["Name"]}')
For this post, our bucket is kendra-augmentation-documents-jp. You can update the code with a different name.
As we mentioned earlier, we create mock PDF documents from public Wikipedia content that represent the media data that we augment and perform searches on. I’ve pre-selected movies and TV shows from the entertainment industry in the following code, but you can choose different topics in your notebook.
# Import fpdf module.
from fpdf import FPDF
# Movie and TV show topics for media documents.
topics = ["Dumb & Dumber Movie", "Black Panther Movie",
"Star Wars The Last Jedi Movie", "Mary Poppins Movie",
"Kung Fu Panda Movie", "I Love Lucy", "The Office TV Show",
"Star Trek: The Original Series", "NCIS TV Show",
"Game of Thrones TV Show"]
# Create PDF documents out of each topic and store into Amazon S3 bucket.
for topic in topics:
# Define text and PDF document names.
text_filename = f"{topic}.txt".replace(" ","_")
pdf_filename = text_filename.replace("txt","pdf")
# Write to text first.
with open(text_filename, "w+") as f:
f.write(wikipedia.summary(topic))
# Convert text to pdf.
pdf = FPDF()
with open(text_filename, 'rb') as text_file:
txt = text_file.read().decode('latin-1')
pdf.set_font('Times', '', 12)
pdf.add_page()
pdf.multi_cell(0, 5, txt)
pdf.output(pdf_filename, 'F')
# Upload to Amazon S3 bucket.
s3_client = boto3.client('s3')
s3_client.upload_file(pdf_filename,
"kendra-augmentation-documents-jp",
pdf_filename)
os.remove(text_filename)
os.remove(pdf_filename)
When this code block finishes running, we have 10 media PDF documents that we can augment with metadata using Amazon Textract and Amazon Comprehend, then run queries on with Amazon Kendra.
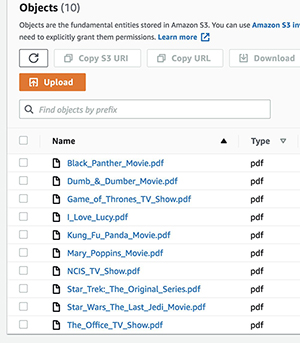
Create metadata using Amazon Textract and Amazon Comprehend
To create metadata for each of our PDF files, we must first extract the text portions of each PDF using Amazon Textract. We run the extracted text through Amazon Comprehend to attach attributes (metadata) to the PDFs, such as named entities, dominant language, and key phrases. Note that Amazon Comprehend will be able to read PDF files directly in a future feature release.
- Use the following helper function (
s3_get_filenames) to get all the file names in a specific bucket or prefix folder in Amazon S3:
def s3_get_filenames(bucket, prefix=None):
"""
Gets all the filenames in a specific bucket/prefix folder in Amazon S3.
Parameters:
----------
bucket : str
String representing bucket name you want to get filenames from.
prefix : str
String representing prefix within the bucket that you want to get
filenames from.
Returns:
-------
file_list : list[str]
List containing all filenames within the bucket/prefix location
"""
# Set Amazon S3 client and get file objects.
s3 = boto3.client('s3')
if prefix == None:
prefix = ''
result = s3.list_objects(Bucket=bucket, Prefix=prefix)
# Put all file names into one list.
file_list = []
for obj in result['Contents']:
# Only take objects that are not the folder.
if 'metadata/' not in obj['Key']:
file_list += [obj['Key']]
return file_list
We run Amazon Textract on each of our PDF files to extract the text of each file and transform the data into a format that we later ingest into Amazon Comprehend.
Next, we create the S3 bucket and service role settings needed to run Amazon Textract through SageMaker notebook instances.
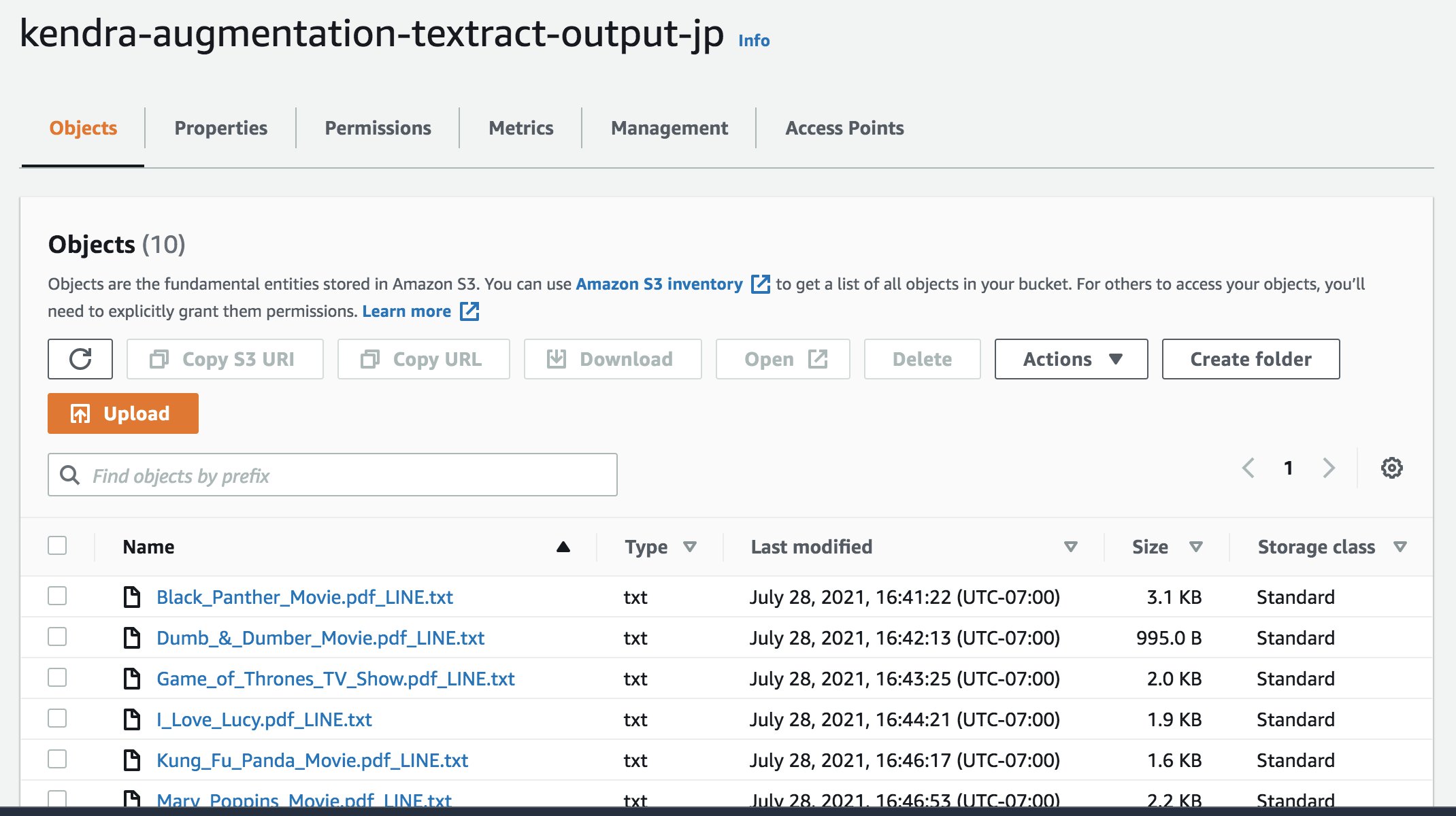
- Create a new S3 bucket to store our Amazon Textract output, called
kendra-augmentation-textract-output-jp:
# Create a new bucket for Amazon Textract text outputs:
bucket_name = "kendra-augmentation-textract-output-jp"
s3_client.create_bucket(Bucket=bucket_name)
- Attach the
AmazonTextractFullAccess policy to the same AmazonSageMaker-ExecutionRole-Kendra-Blog role.
This policy allows SageMaker to access Amazon Textract.
- Run the following code to run Amazon Textract on our PDF files, create new .txt files for Amazon Comprehend to use, and send these files to the S3 bucket we created:
# Amazon Textract specific imports.
!pip install amazon-textract-caller amazon-textract-prettyprinter
from textractcaller.t_call import call_textract, Textract_Features
from textractprettyprinter.t_pretty_print import Textract_Pretty_Print, get_lines_string
import textractprettyprinter.t_pretty_print as prettyprint
# Transform and output documents from s3.
input_bucket = 'kendra-augmentation-documents-jp'
output_bucket = 'kendra-augmentation-textract-output-jp'
s3 = boto3.client('s3')
# Get all the names of the media documents we want to run Textract on.
input_documents = s3_get_filenames(input_bucket)
# Loop through input documents, transform textract outputs into LINE
# transformations, and output to S3 for ingestion into Comprehend.
for document_name in input_documents:
# Define input document to read.
input_document = f's3://{input_bucket}/{document_name}'
# Get text using Textract call_textract function.
textract_json = call_textract(input_document=input_document)
# Convert response from Textract using get_lines_string function.
line_transformation_text = get_lines_string(textract_json=textract_json)
# Put text into text file to send back to S3.
filename = f'{document_name}_LINE.txt'
with open(filename,'w+') as f:
f.write(line_transformation_text)
# Send text file to S3 to be ingested into Comprehend.
with open(filename, 'rb') as data:
s3.upload_fileobj(data, output_bucket, filename)
We now have a .txt Amazon Textract output file for each of our PDFs in the kendra-augmentation-textract-output-jp bucket.
Now that we have our .txt files with the text representation of our PDF files, we can create metadata out of them using Amazon Comprehend.
- Attach the
ComprehendFullAccess policy to the AmazonSageMaker-ExecutionRole-Kendra-Blog role.
We extract and attach the following Amazon Comprehend metadata attributes to each document for Amazon Kendra to index on:
- Dominant language – The language that’s being used the most in the document
- Named entities – A textual reference to the unique name of a real-world object, such as people, places, and commercial items, and precise references to measures such as dates and quantities
- Key phrases – A string containing a noun phrase that describes a particular thing
- Sentiment – The positive, negative, neutral, and mixed sentiment score of the entire document
- Use the following
ComprehendAnalyzer Python class to simplify and unify the Amazon Comprehend API calls. Either copy and paste the code into one of the notebook cells and run it, or create a separate .py file and import it in the notebook.
import boto3
import json
class ComprehendAnalyzer:
"""
Class that takes a document in Amazon S3 and uses Amazon Comprehend to define
metadata to it as attributes for the purpose of being used by Amazon Kendra
downstream.
"""
def __init__(self, s3_bucket, document=None, lang=None):
"""
Instantiates Amazon S3 and Amazon Comprehend clients plus class attributes.
"""
# Instantiate Amazon S3 and Amazon Comprehend.
self.s3 = boto3.client('s3')
self.comprehend = boto3.client('comprehend')
# Instantiate class attributes.
self.s3_bucket = s3_bucket
if s3_bucket != None:
self.document = document
if lang == None:
self.lang = 'en'
# Attribute list that will be used by Amazon Kendra downstream.
self.attribute_list = []
def set_document(self, document):
"""
Sets self.document whenever you want to analyze a new document without having
to instantiate another comprehend_analyzer object.
Parameters:
----------
document : str
String representing document filepath to process.
Returns:
-------
Void
"""
# Set self.document to new document and reset self.attribute_list
self.document = document
self.attribute_list = []
def get_dominant_languages(self, confidence_threshold=.75):
"""
Gets the dominant langauages in self.document in self.s3_bucket in string format. Only
add languages with a confidence score that is greater than or equal to the confidence_threshold input
parameter.
Parameters:
----------
confidence_threshold : float
Float representing confidence threshold for adding languages to metadata. Defaults
to .75.
s3 : boto3.resources.factory.s3.ServiceResource
Amazon S3 client to do the processing. Defaults to None.
comprehend : botocore.client.Comprehend
Amazon Comprehend client to do the processing. Defaults to None.
Returns:
-------
languages_text : str
String representing all the dominant languages found in the document that are
greater than, or equal to, the confidence_threshold input parameter.
"""
# Grab text from document.
test_text = self.s3.get_object(Bucket=self.s3_bucket,
Key=self.document)['Body'].read()
# Detect language using Amazon Comprehend.
comprehend_response = self.comprehend.detect_dominant_language(Text = test_text.decode('utf-8'))
# Take languages over confidence_threshold from comprehend_response.
languages = []
for l in comprehend_response['Languages']:
if l['Score'] >= confidence_threshold:
languages.append(l['LanguageCode'])
languages_text = ', '.join(languages)
# Attribute dictionary input.
attribute_format = {'Key' : 'Languages',
'Value' : {'StringValue' : languages_text}}
# Add languages to self.attribute_list.
self.attribute_list.append(attribute_format)
return languages_text
def get_named_entities(self, confidence_threshold=.75):
"""
Gets the named entities in self.document in Amazon S3 in string format. Only
add named entities with a confidence score that is greater than or equal to
the confidence_threshold input parameter.
Parameters:
----------
confidence_threshold : float
Float representing confidence threshold for adding named entities to metadata. Defaults
to .75.
Returns:
-------
named_entities : list
List representing all the named entities found in the document that are
greater than, or equal to, the confidence_threshold input parameter.
"""
# Grab text from document.
test_text = self.s3.get_object(Bucket=self.s3_bucket,
Key=self.document)['Body'].read()
# Detect named entities using Amazon Comprehend.
comprehend_response = self.comprehend.detect_entities(Text = test_text.decode('utf-8'),
LanguageCode=self.lang)
# Take named entities over confidence_threshold from comprehend_response.
named_entities = []
for entity in comprehend_response['Entities']:
if entity['Score'] >= confidence_threshold:
named_entities.append(entity['Text'])
attribute_format = {'Key' : 'Named_Entities',
'Value' : {'StringListValue' : named_entities[0:10]}}
# Add named entities to self.attribute_list.
self.attribute_list.append(attribute_format)
return named_entities
def get_key_phrases(self, confidence_threshold=.75):
"""
Gets key phrases in self.document in Amazon S3 in string format. Only add key phrases
with a confidence score that is greater than or equal to the confidence_threshold input
parameter.
Parameters:
----------
confidence_threshold : float
Float representing confidence threshold for adding key phrases to metadata. Defaults
to .75.
Returns:
-------
key_phrases : list
List representing all the key phrases found in the document that are
greater than, or equal to, the confidence_threshold input parameter.
"""
# Grab text from document.
test_text = self.s3.get_object(Bucket=self.s3_bucket,
Key=self.document)['Body'].read()
# Detect key phrases using Amazon Comprehend.
comprehend_response = self.comprehend.detect_key_phrases(Text = test_text.decode('utf-8'),
LanguageCode=self.lang)
# Take named entities over confidence_threshold from comprehend_response.
key_phrases = []
for phrase in comprehend_response['KeyPhrases']:
if phrase['Score'] >= confidence_threshold:
key_phrases.append(phrase['Text'])
# Attribute dictionary input.
attribute_format = {'Key' : 'Key_Phrases',
'Value' : {'StringListValue' : key_phrases[0:10]}}
# Add key phrases to self.attribute_list.
self.attribute_list.append(attribute_format)
return key_phrases
def get_sentiment(self):
"""
Gets sentiment in self.document in Amazon S3 in string format. Only add sentiment
with a confidence score that is greater than or equal to the confidence_threshold input
parameter.
Parameters:
----------
None
Returns:
-------
sentiment_dict : dict
Dictionary representing all the sentiment found in the document broken down
into overall sentiment and inidividual scores for positive, negative, neutral,
and mixed sentiments.
"""
# Grab text from document.
test_text = self.s3.get_object(Bucket=self.s3_bucket,
Key=self.document)['Body'].read()
# Detect sentiment using Amazon Comprehend.
comprehend_response = self.comprehend.detect_sentiment(Text = test_text.decode('utf-8'),
LanguageCode=self.lang)
# Add sentiment scores to self.attribute_dict.
attribute_format = [{'Key' : 'Sentiment',
'Value' : {'StringValue' : comprehend_response['Sentiment']}},
{'Key' : 'Positive_Score',
'Value' : {'LongValue' : int(comprehend_response['SentimentScore']['Positive']*100)}},
{'Key' : 'Negative_Score',
'Value' : {'LongValue' : int(comprehend_response['SentimentScore']['Negative']*100)}},
{'Key' : 'Neutral_Score',
'Value' : {'LongValue' : int(comprehend_response['SentimentScore']['Neutral']*100)}},
{'Key' : 'Mixed_Score',
'Value' : {'LongValue' : int(comprehend_response['SentimentScore']['Mixed']*100)}}]
self.attribute_list += attribute_format
# Add same information to sentiment_dict.
sentiment_dict = {}
sentiment_dict['Sentiment'] = comprehend_response['Sentiment']
sentiment_dict['Positive_Score'] = int(comprehend_response['SentimentScore']['Positive']*100)
sentiment_dict['Negative_Score'] = int(comprehend_response['SentimentScore']['Negative']*100)
sentiment_dict['Neutral_Score'] = int(comprehend_response['SentimentScore']['Neutral']*100)
sentiment_dict['Mixed_Score'] = int(comprehend_response['SentimentScore']['Mixed']*100)
return sentiment_dict
We now have everything we need to create an Amazon Kendra index, create and add metadata to the index, and start boosting and filtering our Amazon Kendra searches!
Configure our Amazon Kendra index
Now that we’ve got our Amazon Textract outputs and our Amazon Comprehend class in ComprehendAnalyzer, we can put everything together with Amazon Kendra.
Configure Amazon Kendra IAM access
Like in the previous steps, we need to give SageMaker access to use Amazon Kendra by attaching the AmazonKendraFullAccess policy to the AmazonSageMaker-ExecutionRole-Kendra-Blog role. Then we create an IAM policy and service role.
- Attach the
AmazonKendraFullAccess policy to the AmazonSageMaker-ExecutionRole-Kendra-Blog role.
To create an index with Amazon Kendra, we first create an IAM policy that lets Amazon Kendra access our CloudWatch Logs, and then create an Amazon Kendra service role. For full instructions, see the Amazon Kendra Developer Guide. I outline the exact steps in this section for your convenience.
- On the IAM console, choose Policies in the navigation pane.
- Choose Create policy.
- Choose JSON and replace the default policy with the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "AWS/Kendra"
}
}
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:logs:region:account ID:log-group:/aws/kendra/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:region:account ID:log-group:/aws/kendra/*:log-stream:*"
]
}
]
}
- Choose Review policy.
- Name the policy
KendraPolicyForGettingStartedIndex and choose Create policy.
- Choose Another AWS account and enter your account ID.
- Choose Next: Permissions.
- In the navigation pane, choose Roles.
- Choose Create role.
- Choose the policy that you just created and choose Next: Tags.
- Don’t add any tags and choose Next: Review.
- Name the role
KendraRoleForGettingStartedIndex and choose Create role.
- Find the role that you just created and open the role summary.
- Choose Trust relationships and then choose Edit trust relationship.
- Replace the existing trust relationship with the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kendra.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- Choose Update trust policy.
Create your Amazon Kendra Index
Now that we’ve got all the policies and roles that we need, let’s create our Amazon Kendra index using the following code. You have to update the role ARN with your AWS account number.
# Instantiate Amazon Kendra client.
kendra = boto3.client('kendra')
# Set index name and input service role.
index_name = "blog-media-company-index"
index_role_arn ="arn:aws:iam::{your_account_no}:role/service-role/KendraPolicyForGettingStartedIndex"
# Create Amazon Kendra index
index_response = kendra.create_index(
Name = index_name,
RoleArn = index_role_arn
)
# Get index ID for reference.
index_id = index_response["Id"]
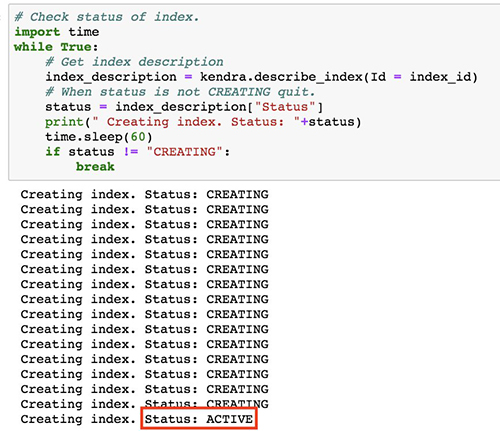
# Check status of index.
import time
while True:
# Get index description
index_description = kendra.describe_index(Id = index_id)
# When status is not CREATING quit.
status = index_description["Status"]
print(" Creating index. Status: "+status)
time.sleep(60)
if status != "CREATING":
break
When this code block is done running, you should see the status as Active when your Amazon Kendra index has been created.
Define the Amazon Kendra index metadata configuration
We now define the metadata configuration for the index blog-media-company-index we just made. It follows the Amazon Comprehend attributes we defined in our Python class ComprehendAnalyzer. See the following code:
# Since comprehend_analyzer has the ability to create 8 new attributes with Amazon
# Textract and Amazon Comprehend, we'll update the metadata configuration of Amazon
# Kendra to reflect those attributes.
meta_config_dict = {'Id':index_id,
'DocumentMetadataConfigurationUpdates':[
{'Name': 'Languages',
'Type': 'STRING_VALUE',
'Search': {
'Facetable': True,
'Searchable' : True,
'Displayable': True},
'Relevance': {
'Importance': 1},
},
{'Name': 'Key_Phrases',
'Type': 'STRING_LIST_VALUE',
'Search': {
'Facetable': True,
'Searchable' : True,
'Displayable': True},
},
{'Name': 'Named_Entities',
'Type': 'STRING_LIST_VALUE',
'Search': {
'Facetable': True,
'Searchable' : True,
'Displayable': True},
},
{'Name': 'Sentiment',
'Type': 'STRING_VALUE',
'Search': {
'Facetable': True,
'Searchable' : True,
'Displayable': True},
'Relevance': {
'Importance': 1},
},
{'Name': 'Positive_Score',
'Type': 'LONG_VALUE',
'Search': {
'Facetable': True,
'Searchable' : False,
'Displayable': True},
'Relevance': {
'Importance': 1,
'RankOrder': 'DESCENDING'},
},
{'Name': 'Negative_Score',
'Type': 'LONG_VALUE',
'Search': {
'Facetable': True,
'Searchable' : False,
'Displayable': True},
'Relevance': {
'Importance': 1,
'RankOrder': 'DESCENDING'},
},
{'Name': 'Neutral_Score',
'Type': 'LONG_VALUE',
'Search': {
'Facetable': True,
'Searchable' : False,
'Displayable': True},
'Relevance': {
'Importance': 1,
'RankOrder': 'DESCENDING'},
},
{'Name': 'Mixed_Score',
'Type': 'LONG_VALUE',
'Search': {
'Facetable': True,
'Searchable' : False,
'Displayable': True},
'Relevance': {
'Importance': 1,
'RankOrder': 'DESCENDING'},
},
]
}
response = kendra.update_index(**meta_config_dict)
print(response)
Create metadata using ComprehendAnalyzer
Now that we’ve created our index blog-media-company-index and defined and set our metadata configuration, we use ComprehendAnalyzer to extract metadata from our media files in Amazon S3:
# Define input parameters.
textract_output_bucket = 'kendra-augmentation-textract-output-jp'
textract_documents = s3_get_filenames(textract_output_bucket)
analyzer = ComprehendAnalyzer(s3_bucket=textract_output_bucket)
# Instantiate Amazon S3 client.
s3 = boto3.client('s3')
# Instantiate document list to be ingested into Amazon Kendra index.
documents = []
# Loop through each document in Amazon S3:
# 1. Create document by using the Amazon Textract output in addition to
# the metadata defined with comprehend_analyzer.
# 2. Append document to document list to be ingested into Amazon Kendra.
for d in textract_documents:
# Set document.
analyzer.set_document(d)
# Get metadata.
analyzer.get_dominant_languages()
analyzer.get_key_phrases()
analyzer.get_named_entities()
analyzer.get_sentiment()
# Remove either "_LINE.txt" or "_WORD.txt" from the document filename.
document_id = d[0:-9]
# Grab text from the Amazon Textract output.
text = s3.get_object(Bucket=textract_output_bucket,
Key=d)['Body'].read()
# Define document with Amazon Textract text and Amazon Comprehend attributes.
document = {
'Id': document_id,
'Title': document_id,
'Blob': text,
'Attributes':analyzer.attribute_list,
'ContentType':'PLAIN_TEXT'
}
documents.append(document)
If you want to see what the metadata looks like, look at the first item in the documents Python list by running the following code:
# Take a look at the first of the metadata documents you've prepared.
documents[0]['Attributes']
Load metadata into the Amazon Kendra index
The last step is to load the metadata we extracted using ComprehendAnalyzer into the blog-media-company-index index by running the following code:
kendra.batch_put_document(
IndexId = index_id,
Documents = documents)
Now we’re ready to start querying and boosting some of the metadata attributes!
Query the index and boost metadata attributes
We now have everything set up to start querying our data. We’re able to weigh attributes differently in terms of significance, make metadata attributes searchable, influence the order of results coming back from the query by improving the sentiment metadata, and much more.
Run a sample query
Before we get into a few examples that demonstrate the power and flexibility this metadata attachment gives us, let’s run the following code to query the blog-media-company-index index:
# Print function to more easily visualize Amazon Kendra query results.
def print_results(response, result_number):
print ('\nSearch results for query: ' + query + '\n')
count = 0
for query_result in response['ResultItems']:
print('-------------------')
print('Type: ' + str(query_result['Type']))
if query_result['Type']=='ANSWER':
count += 1
answer_text = query_result['DocumentExcerpt']['Text']
print(answer_text)
if query_result['Type']=='DOCUMENT':
if 'DocumentTitle' in query_result:
document_title = query_result['DocumentTitle']['Text']
print('Title: ' + document_title)
document_text = query_result['DocumentExcerpt']['Text']
print(document_text)
count += 1
print ('------------------\n\n')
if count >= result_number:
break;
def print_list(dict_list):
for attribute in dict_list:
text = attribute['Key'] + ": "
for k,v in attribute['Value'].items():
text += str(v) + "\n"
print(text)
We can test the following query to get a sense of how to query our new index:
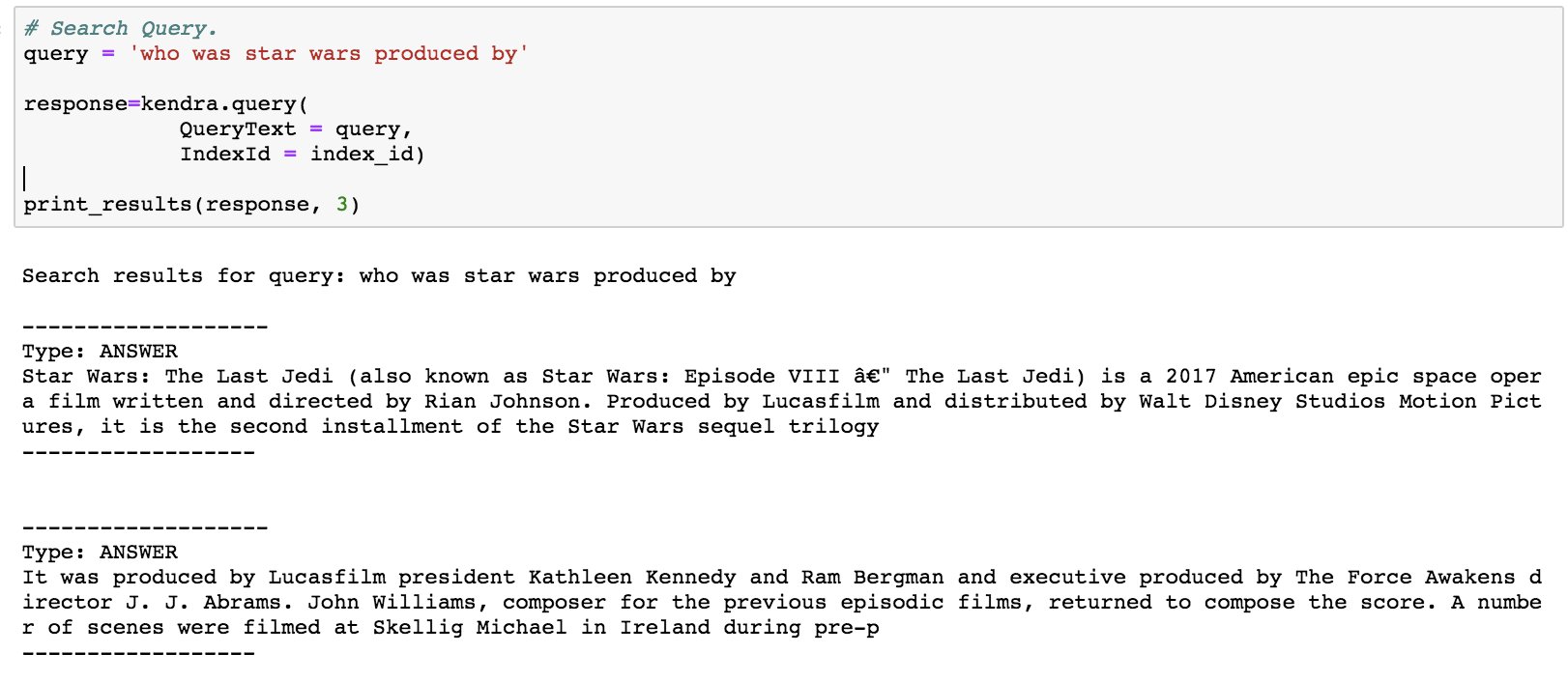
# Search Query.
query = 'who was star wars produced by'
response=kendra.query(
QueryText = query,
IndexId = index_id)
print_results(response, 3)
You should get a response like the following screenshot.
Now that you know how to query, let’s get into some examples of how we can use our metadata to influence our searches.
Improve metadata
This section contains some examples of how we can influence and control our search for more targeted results. For each of the examples, we update our blog-media-company-index index by modifying our meta_config_dict and rerunning the following code:
kendra.update_index(**meta_config_dict)
Example 1: Weighing attributes
To weigh attributes by significance, update the Importance value of the attributes. The range for importance goes from 1–10, 1 being lowest, and 10 being the highest.
For example, let’s say we have a use case where we have different country entities and we have documents in many different languages. We can increase the significance of the Languages metadata attribute to account for this by updating its Importance to 10, and making sure Searchable is set to True. This makes it so that the text in the field Languages is searchable. See the following code:
{'Name': 'Languages',
'Type': 'STRING_VALUE',
'Search': {
'Facetable': True,
'Searchable' : True,
'Displayable': True},
'Relevance': {
'Importance': 10},
}
Now let’s say that we’re looking for more positive context results. We increase the Importance value of the metadata attribute Sentiment to 10:
{'Name': 'Sentiment',
'Type': 'STRING_VALUE',
'Search': {
'Facetable': True,
'Searchable' : True,
'Displayable': True},
'Relevance': {
'Importance': 10},
}
Example 2: Ranking search results
Let’s say we want to influence the rank of the search results by a particular sentiment metadata attribute. We can simply configure the Importance and RankOrder of the sentiment we want. For example, if we want to increase the significance of the positive results and rank those results higher than the negative, we update the Positive_score attribute to have an Importance of 10 and a RankOrder of DESCENDING to put the most positive results at the top. We leave the Importance of Negative_Score at 1 and update its RankOrder to ASCENDING to make sure the least negative sentiment results show up higher. See the following code:
{'Name': 'Positive_Score',
'Type': 'LONG_VALUE',
'Search': {
'Facetable': True,
'Searchable' : False,
'Displayable': True},
'Relevance': {
'Importance': 1,
'RankOrder': 'DESCENDING'},
},
{'Name': 'Negative_Score',
'Type': 'LONG_VALUE',
'Search': {
'Facetable': True,
'Searchable' : False,
'Displayable': True},
'Relevance': {
'Importance': 1,
'RankOrder': 'ASCENDING'},
}
Get creative!
At this point, you’ve got your Amazon Kendra index and metadata attributes set up. Go ahead and play around with querying, weighing metadata, and ranking results by creating your own creative combinations!
Clean up
To avoid extra charges, shut down the SageMaker and Amazon Kendra resources when you’re done.
- On the SageMaker console, choose Notebook and Notebook instances.
- Select the notebook that you created.
- On the Actions menu, choose Stop.
- Choose Delete.
Alternatively, you can keep the instance stopped indefinitely and not be charged.
- On the Amazon Kendra console, choose Indexes.
- Select the index you created.
- On the Actions menu, choose Delete.
Because we used Amazon Textract and Amazon Comprehend via API, there are no shutdown steps necessary for those resources.
Conclusion
In this post, we showed how to do the following:
- Use Amazon Textract on PDF files to extract text from documents
- Use Amazon Comprehend to extract metadata attributes from Amazon Textract output
- Perform targeted searches with Amazon Kendra using the metadata attributes extracted by Amazon Comprehend
Although this may have been a mock media company example using public sample data, I hope you were able to have some fun following along and realize the potential—and power—of chaining Amazon Textract, Amazon Comprehend, and Amazon Kendra together. Use this new knowledge and start augmenting your historical data! To learn more about how Amazon Kendra’s fully managed intelligent search service can help your business, visit our webpage or dive into our documentation and tutorials!
About the Author
 James Poquiz is a Data Scientist with AWS Professional Services based in Orange County, California. He has a BS in Computer Science from the University of California, Irvine and has several years of experience working in the data domain having played many different roles. Today he works on implementing and deploying scalable ML solutions to achieve business outcomes for AWS clients.
James Poquiz is a Data Scientist with AWS Professional Services based in Orange County, California. He has a BS in Computer Science from the University of California, Irvine and has several years of experience working in the data domain having played many different roles. Today he works on implementing and deploying scalable ML solutions to achieve business outcomes for AWS clients.