Artificial Intelligence
Category: Amazon Textract

Improve data extraction and document processing with Amazon Textract
Intelligent document processing (IDP) has seen widespread adoption across enterprise and government organizations. Gartner estimates the IDP market will grow more than 100% year over year, and is projected to reach $4.8 billion in 2022. IDP helps transform structured, semi-structured, and unstructured data from a variety of document formats into actionable information. Processing unstructured data […]

Real estate brokerage firm John L. Scott uses Amazon Textract and Amazon Comprehend to strike racially restrictive language from property deeds for homeowners
Founded more than 91 years ago in Seattle, John L. Scott Real Estate’s core value is Living Life as a Contribution®. The firm helps homebuyers find and buy the home of their dreams, while also helping sellers move into the next chapter of their home ownership journey. John L. Scott currently operates over 100 offices […]

Customize business rules for intelligent document processing with human review and BI visualization
A massive amount of business documents are processed daily across industries. Many of these documents are paper-based, scanned into your system as images, or in an unstructured format like PDF. Each company may apply unique rules associated with its business background while processing these documents. How to extract information accurately and process them flexibly is […]

InformedIQ automates verifications for Origence’s auto lending using machine learning
This post was co-written with Robert Berger and Adine Deford from InformedIQ. InformedIQ is the leader in AI-based software used by the nation’s largest financial institutions to automate loan processing verifications and consumer credit applications in real time per the lenders’ policies. They improve regulatory compliance, reduce cost, and increase accuracy by decreasing human error […]

Introducing self-service quota management and higher default service quotas for Amazon Textract
Today, we’re excited to announce self-service quota management support for Amazon Textract via the AWS Service Quotas console, and higher default service quotas in select AWS Regions. Customers tell us they need quick turnaround times to process their requests for quota increases and visibility into their service quotas so they may continue to scale their […]
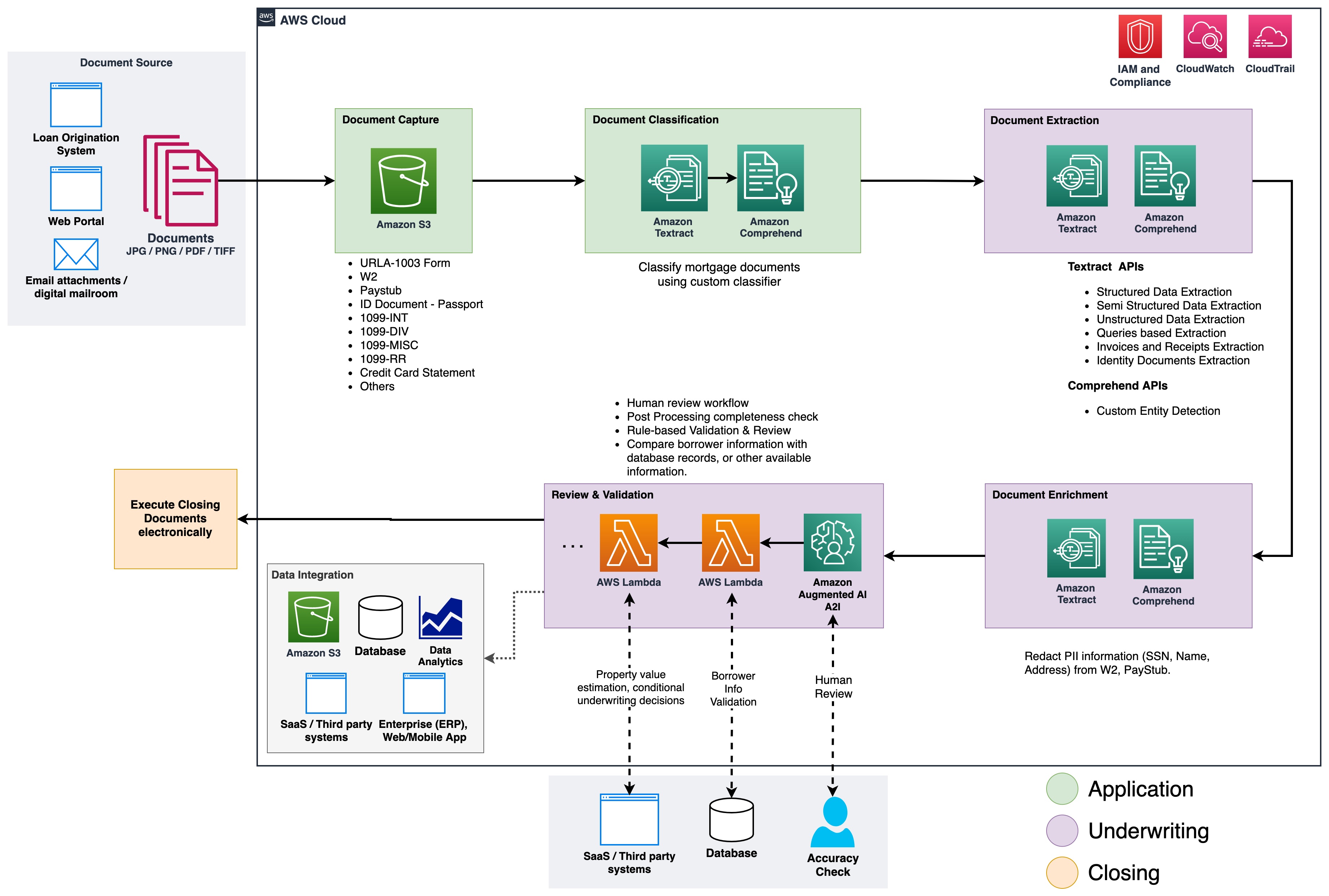
Process mortgage documents with intelligent document processing using Amazon Textract and Amazon Comprehend
Organizations in the lending and mortgage industry process thousands of documents on a daily basis. From a new mortgage application to mortgage refinance, these business processes involve hundreds of documents per application. There is limited automation available today to process and extract information from all the documents, especially due to varying formats and layouts. Due […]

Intelligent document processing with AWS AI services: Part 2
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. For customers who process millions of documents, this is a critical aspect for the end-user experience and a top digital transformation […]

Intelligent document processing with AWS AI services: Part 1
Organizations across industries such as healthcare, finance and lending, legal, retail, and manufacturing often have to deal with a lot of documents in their day-to-day business processes. These documents contain critical information that are key to making decisions on time in order to maintain the highest levels of customer satisfaction, faster customer onboarding, and lower […]

Analyze and tag assets stored in Veeva Vault PromoMats using Amazon AppFlow and Amazon AI Services
In a previous post, we talked about analyzing and tagging assets stored in Veeva Vault PromoMats using Amazon AI services and the Veeva Vault Platform’s APIs. In this post, we explore how to use Amazon AppFlow, a fully managed integration service that enables you to securely transfer data from software as a service (SaaS) applications […]

Use AWS AI and ML services to foster accessibility and inclusion of people with a visual or communication disability
AWS offers a broad set of artificial intelligence (AI) and machine learning (ML) services, including a suite of pre-trained, ready-to-use services for developers with no prior ML experience. In this post, we demonstrate how to use such services to build an application that fosters the inclusion of people, who speak a different language or those […]