Artificial Intelligence
Category: Compute

Deploy a serverless web application to edit images using Amazon Bedrock
In this post, we explore a sample solution that you can use to deploy an image editing application by using AWS serverless services and generative AI services. We use Amazon Bedrock and an Amazon Titan FM that allow you to edit images by using prompts.

Create a multimodal chatbot tailored to your unique dataset with Amazon Bedrock FMs
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents.

Improve employee productivity using generative AI with Amazon Bedrock
In this post, we show you the Employee Productivity GenAI Assistant Example, a solution built on AWS technologies like Amazon Bedrock, to automate writing tasks and enhance employee productivity.

Accelerate pre-training of Mistral’s Mathstral model with highly resilient clusters on Amazon SageMaker HyperPod
In this post, we present to you an in-depth guide to starting a continual pre-training job using PyTorch Fully Sharded Data Parallel (FSDP) for Mistral AI’s Mathstral model with SageMaker HyperPod.

Building an efficient MLOps platform with OSS tools on Amazon ECS with AWS Fargate
In this post, we show you how Zeta Global, a data-driven marketing technology company, has built an efficient MLOps platform to streamline the end-to-end ML workflow, from data ingestion to model deployment, while optimizing resource utilization and cost efficiency.

Introducing Amazon EKS support in Amazon SageMaker HyperPod
This post is designed for Kubernetes cluster administrators and ML scientists, providing an overview of the key features that SageMaker HyperPod introduces to facilitate large-scale model training on an EKS cluster.

Amazon EC2 P5e instances are generally available
In this post, we discuss the core capabilities of Amazon Elastic Compute Cloud (Amazon EC2) P5e instances and the use cases they’re well-suited for. We walk you through an example of how to get started with these instances and carry out inference deployment of Meta Llama 3.1 70B and 405B models on them.

Accelerate performance using a custom chunking mechanism with Amazon Bedrock
This post explores how Accenture used the customization capabilities of Knowledge Bases for Amazon Bedrock to incorporate their data processing workflow and custom logic to create a custom chunking mechanism that enhances the performance of Retrieval Augmented Generation (RAG) and unlock the potential of your PDF data.
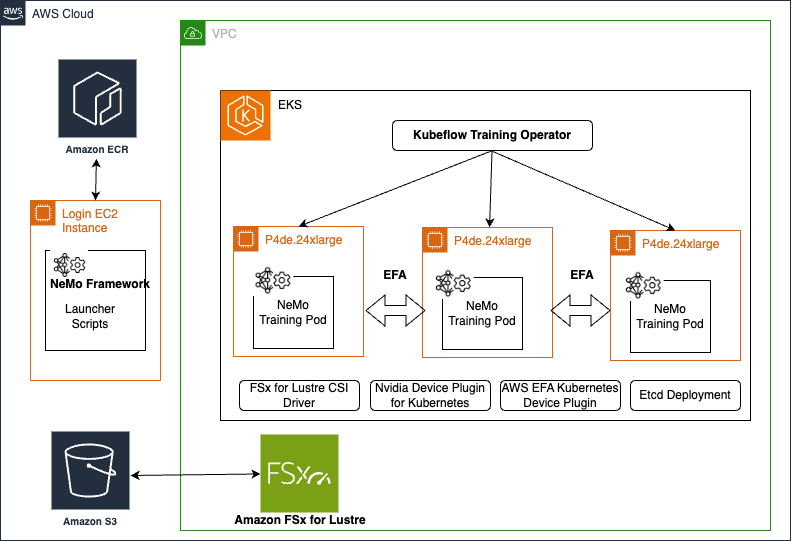
Accelerate your generative AI distributed training workloads with the NVIDIA NeMo Framework on Amazon EKS
In today’s rapidly evolving landscape of artificial intelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. Without a structured framework, the process can become prohibitively time-consuming, costly, and complex. Enterprises struggle with managing […]

Accelerated PyTorch inference with torch.compile on AWS Graviton processors
Originally PyTorch used an eager mode where each PyTorch operation that forms the model is run independently as soon as it’s reached. PyTorch 2.0 introduced torch.compile to speed up PyTorch code over the default eager mode. In contrast to eager mode, the torch.compile pre-compiles the entire model into a single graph in a manner that’s optimal for […]