Artificial Intelligence
Introducing PII identification and redaction in streaming transcriptions using Amazon Transcribe
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech to text capabilities to their applications. Since launching in 2017, Amazon Transcribe has added numerous features to enhance its capabilities around converting speech to text. Some of these features include automatic language detection, custom language models, vocabulary filtering, speaker identification, streaming transcriptions, and more.
One popular use case of Amazon Transcribe is transcribing customer support calls or any customer interaction that involves voice. You can use these transcripts to record customer conversations and extract insights such as sentiment, call drivers, or agent performance. Therefore, call transcripts are a valuable dataset that is crucial to effectively addressing customer needs and improving operational performance. However, it’s critical to ensure that the right safeguards are put in place to protect customer identity and privacy when using this data.
To enable privacy protection, Amazon Transcribe launched automatic redaction of personally identifiable information (PII) in transcription jobs. Companies can use this feature to redact sensitive personal information such as credit card or social security numbers in your call and voice recordings. However, we heard from customers that they also want to mask such information from real-time transcription results on agent desktops. With PII redaction, supervisors can view a dashboard that can highlight trends in ongoing conversations, while helping to make sure that the identity of each customer is protected.
Today, we’re excited to announce a new feature of Amazon Transcribe that can help achieve this: PII identification and redaction in streaming transcriptions. With this feature, you can redact sensitive data in your streaming transcriptions and display the output as per your requirements. Let’s look at how this service works.
Feature overview
This feature extends the existing StartStreamingTranscription operation of Amazon Transcribe. You just add few more parameters to customize the stream (see the following code):
You can select the behavior you want in the streaming transcription. You can choose from two options when starting a streaming session: identify PII or redact PII. The purpose of adding these is to help you highlight or mask the sensitive information identified.
In addition, you can now specify PII types by setting a value for the x-amzn-transcribe-pii-entity-types parameter. This parameter supports identifying the following PII types: BANK_ACCOUNT_NUMBER, BANK_ROUTING, CREDIT_DEBIT_NUMBER, CREDIT_DEBIT_CVV, CREDIT_DEBIT_EXPIRY, PIN, EMAIL, ADDRESS, NAME, PHONE, SSN, and ALL. This is an optional parameter with a default value of ALL. Also, it supports selecting multiple types in the form of a comma-separated list like NAME, ADDRESS.
We wanted to give you the flexibility to select the PII types you want to redact or identify. For example, you might want to protect your customers’ Social Security number and credit card details, but might need other PII fields like name, email, and phone to create or update customer profiles in CRM systems for marketing and analytics purposes.
When parsing responses generated by the service, you see a JSON response similar to the following. The most important field to note is the Entities field.
In the preceding example response, the behavior desired was redaction, therefore when PII data was detected (in this case, a name), it was replaced with the tag [NAME]. This is also highlighted by the Entities array in the response, which provides category of identification and confidence value (between 0–1, where a value of 1 indicates highest confidence) about the PII identification.
You can also request to just identify PII data by setting x-amzn-transcribe-content-identification-type to PII in the StartStreamingTranscription action. It returns a response similar to the following:
This feature is available to customers programmatically using HTTP/2 streaming and WebSocket streaming. For more information about this feature, see the Amazon Transcribe documentation.
How to use the feature
Let’s explore how we can use this feature. You can try it out three different ways:
- Using the AWS Management Console
- Using HTTP/2 streaming
- Using WebSocket streaming
However, in this blog we will be only discussing the AWS Management Console and HTTP/2 streaming options.
Using the AWS Management Console
To test out this feature from the AWS Management Console, we must navigate to the Amazon Transcribe Page. You can do this by typing “transcribe” in the search bar on the console.

Once there, hover over to “Real Time Transcription”.
Now let’s test this out, but first let’s set the content removal settings. For demonstration purposes, we’ll be just identifying all types of PII data in the stream.
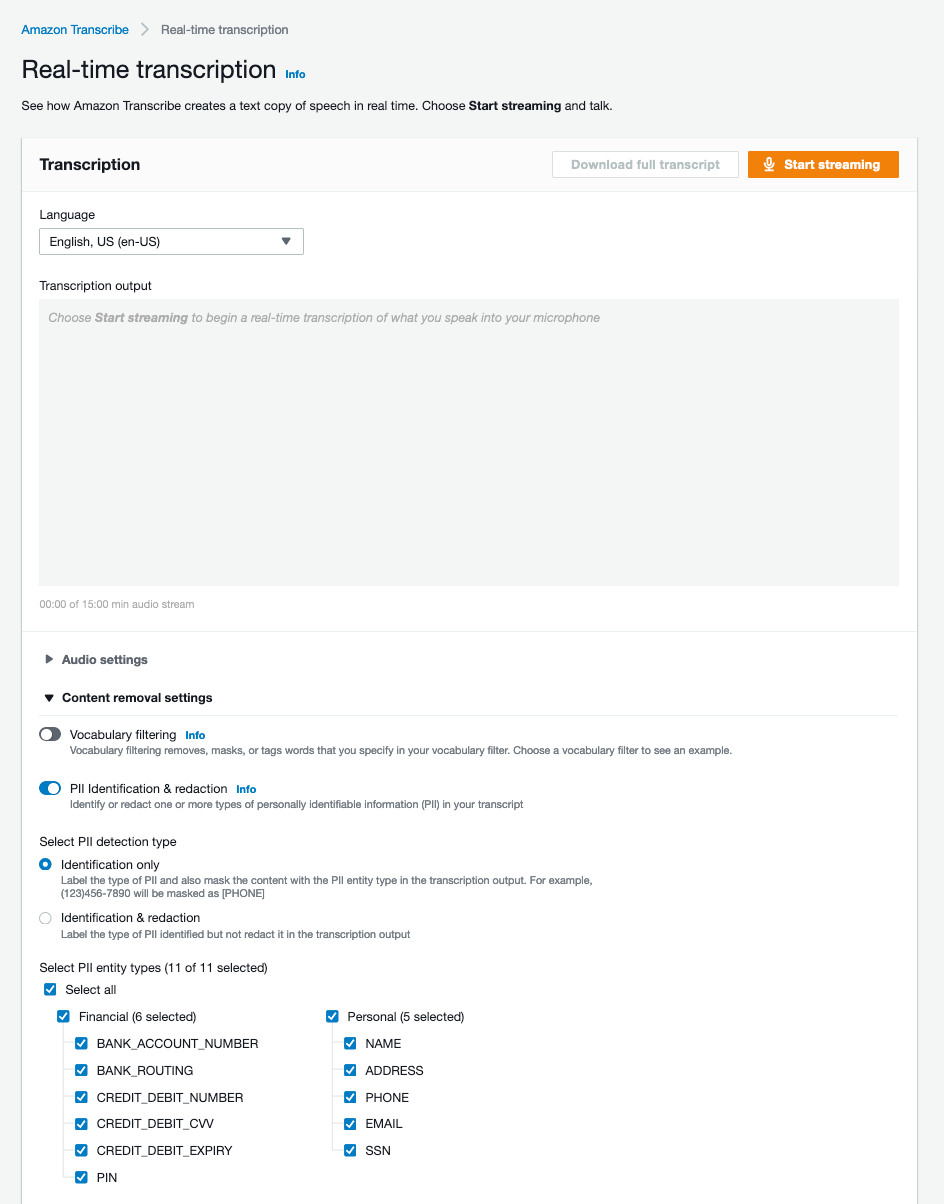
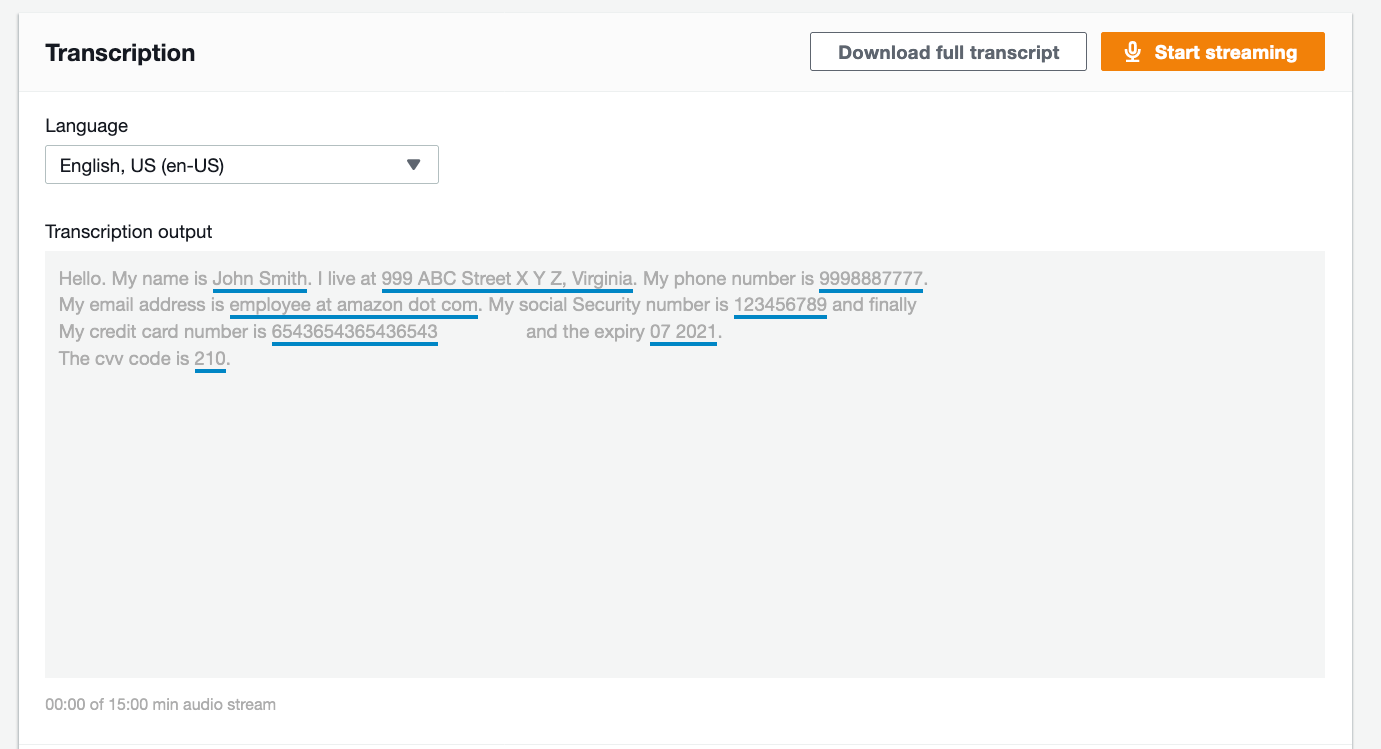
Now, click “Start streaming”. For the input voice, I said the following lines, which contains PII data, into my computer’s mic (Please note we will be using the same lines later in this blog when we test this feature programmatically):
Hello. My name is John Smith. I live at 999 ABC Street X Y Z, Virginia. My phone number is 999-888-7777. My email address is employee@amazon.com. My social security number is 123-45-6789. And finally, my credit card number is 6543 6543 6543 6543 and the expiry is 07/2021. The CVV code is 210.
We see the following output where the identified PII data is highlighted by an underline. You can also download the full transcript to further analyze the results.
Using HTTP/2 streaming
In this section, we focus specifically on how to enable this feature using HTTP/2 streaming, and we use the AWS SDK for Java v2. For an example, see the following GitHub repo. In this project, the example application TranscribeStreamingDemoApp.java uses the StartStreamingTranscription action of Amazon Transcribe (implemented in Java).
To test out this feature, we need to make sure that the AWS SDK for Java is up to date with the latest version so that we can use this release. For more information, see Set up the AWS SDK for Java.
Next, we need to make sure that we have the right permissions associated. The following JSON snippet is a permissions policy that illustrates the minimum permissions required to use this feature:
Now let’s explore the code we use to test this feature out (TranscribeStreamingDemoApp.java). All the classes under this directory work in tandem to provide the birectional streaming functionality that we test for generating the live transcriptions. If we explore this file, we can see that (at line 79) we instantiate the request to the StartStreamTranscriptions API.
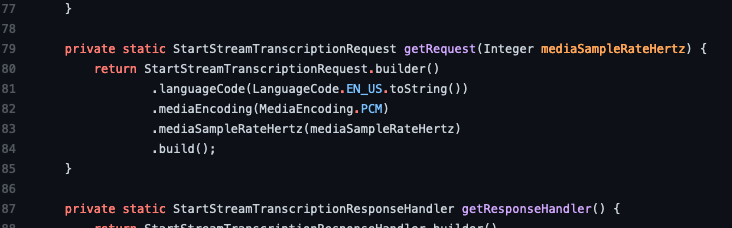
As we discussed earlier, PII identification and redaction in streaming adds a few more parameters to set streaming behavior. For this example, we try out content redaction for all PII entity types. Therefore, the modified code would look like the following screenshot.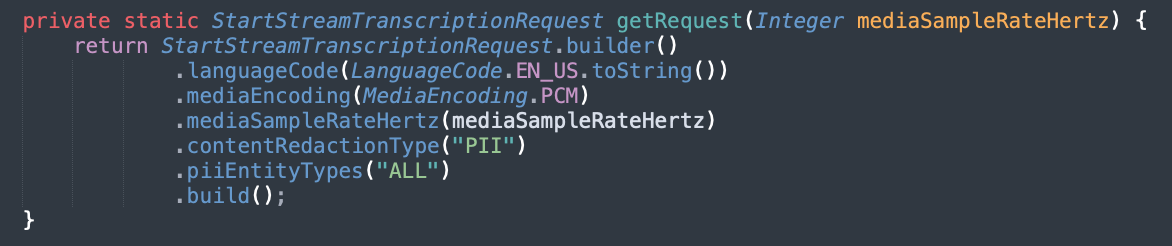
The original response handler code displays partial results of the streaming transcriptions.

However, in the use case of masking sensitive data, it’s best to display and use output that is the final output of the transcription. Therefore, we modify the code to only display the final output using the isPartial field in the streaming responses. The following screenshot shows the implementation.

Now let’s test this out. You can build and run this code using your IDE or the command line. For the input voice, we will use the same lines used earlier.
The following screenshot shows our output:

Each line was streamed to the console as soon as Amazon Transcribe inferred it was the final result.
Now, let’s take the use case where we don’t want to redact the name, email address, and phone number. We only want to redact the Social Security number, credit card number, its expiration date, and the CVV code. To do so, we modify the request by listing the PII types we want to redact in the PII_Entity_types parameter.

The following screenshot shows our output:

Conclusion
As demonstrated in this post, Amazon Transcribe can be used to help identify and redact PII in streaming transcriptions. This feature can streamline and simplify customer data management across industries such as financial services, government, retail, and much more.
As of today, PII identification and redaction for streaming transcription is supported in the following AWS Regions: US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Seoul), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), EU (Frankfurt), EU (Ireland), and EU (London). For pricing information, see Amazon Transcribe Pricing.
For additional resources, see the following:
- Amazon Transcribe Documentation for PII redaction
- Amazon Transcribe Management Console
- Tutorial: Add privacy to your transcriptions with Amazon Transcribe
About the Author
 Vishesh Jha is a Solutions Architect at AWS working with Public Sector Partners. He specializes in AI/ML and has helped customers & partners get started with NLP and CV using AWS services such as Amazon Lex, Transcribe, Amazon Translate, Amazon Comprehend, Amazon Kendra, Amazon Rekognition, and Amazon SageMaker. He is an avid soccer fan, and in his free time enjoys watching and playing the sport. He also loves cooking, gaming, and traveling with his family.
Vishesh Jha is a Solutions Architect at AWS working with Public Sector Partners. He specializes in AI/ML and has helped customers & partners get started with NLP and CV using AWS services such as Amazon Lex, Transcribe, Amazon Translate, Amazon Comprehend, Amazon Kendra, Amazon Rekognition, and Amazon SageMaker. He is an avid soccer fan, and in his free time enjoys watching and playing the sport. He also loves cooking, gaming, and traveling with his family.