AWS for M&E Blog
Using speech-to-text for media captioning and metadata generation
Guest post by Mark Stephens (Partner Solutions Architect, AWS Partner Program), James Varndell (Product Manager, IPV), and Rebecca Lindley (Product Marketing Associate, IPV).
In our last guest post, we discussed how IPV Curator works with AWS to transform workflows and boost productivity by solving common problems in the content production industry. This time we’ll be focussing on automating your captioning and metadata generation, providing considerable time and cost savings.
At the moment everyone’s talking about machine learning and its potential to transform the way we work with our media. AWS and IPV have worked together to make sure that you can get the best out of the machine learning that’s available to us right now. In this post we’ll show how a combination of IPV Curator and Amazon Transcribe speech-to-text technology means that any content creator can add automation to their captioning and metadata workflows.
CURATOR + AMAZON TRANSCRIBE
Amazon Transcribe provides an automatic speech recognition service that will return a text file of transcribed speech. When integrated with IPV Curator, the power of Amazon Transcribe is combined with a professional video player, remote editing functionality, and automated publishing options to to produce perfectly-timed, editable captions with a good level of accuracy, wherever you are.
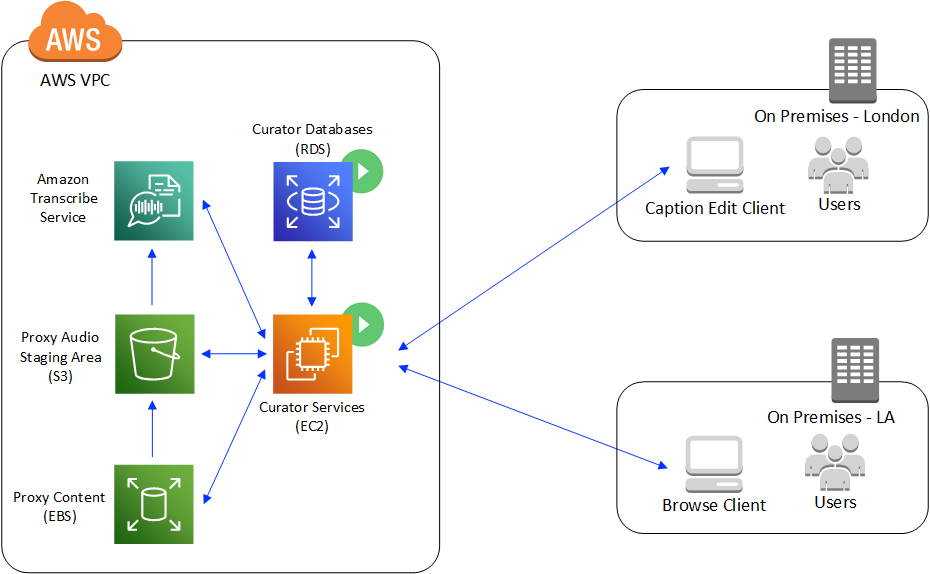
So, how does the integration work? IPV stores high-quality, frame accurate proxy versions of content in S3. When content needs captioning, the appropriate audio track is sent to Transcribe, along with metadata about the audio track language. Curator then takes the Transcribe output and forms sentences between punctuation marks to make it more readable, as well as wrapping the text so it doesn’t overrun the video. These are then written into a WebVTT caption file and virtual subclips are created in Curator – we’ll discuss these in greater detail later. Any captions below a confidence threshold (default 80%) are highlighted so operators can approve or correct the text. However, Transcribe is already able to provide a good level of accuracy, with around one in every 10 seconds of content requiring editing – depending on the type of content. While you may still need to do some editing, you’ll still save a lot of time, even compared to real time captioning. Additionally, the continuing development of machine learning means that accuracy levels are always improving.
CAPTION FROM ANYWHERE
A key advantage of the integration is that Curator’s architecture makes it possible to work with captions from anywhere in the world. Instead of bearing the costs of transferring high resolution content, editors can stream frame accurate, proxy versions of their content that are only 2% of the size of the high-resolution files. This means that data transferred for a 300GB/hour 4K file is reduced to only 6GB/hour, giving massive time and cost savings. Users can then use Transcribe to add captions to their content, and conform it, all without access to the hi-res. Again, through the IPV proxy, only the relevant audio track (128Kb/s audio) is sent and not the whole hi-res video & audio.
Adding captions isn’t the only important part of the captioning process – machine learning is still a developing technology, and sometimes you’ll want to make edits to captions. The Curator-Transcribe integration makes it simple and intuitive to do this: users can simply view each caption in Curator Logger and click to edit them.

Here are just a few of the applications we’ve seen for this so far
CUTTING CAPTION COSTS
Captioning is expensive and time consuming, but you need to do it to reach a wider, increasingly mobile audience. Curator + Transcribe enables you to reach a base level of captioning with less expense and effort. We’ve calculated that once you reach a point where you’re captioning more than 3.5 hours of content per week you can save money by using a Curator system with Amazon Transcribe integration. For example, if you’re outsourcing the captioning of 5 hours of content every week at the cost of $4.00/ minute, you’ll end up spending $62,400 a year. Buying a Curator system and doing the same captioning with AWS Transcribe will cost only $43,016, saving you almost $20,000 dollars a year. As you increase the amounts you’re captioning, the savings get even bigger, reaching as much as $200,000 a year if you’re doing 20 hours of captioning each week.
In this case, m5.xlarge EC2 instances run Curator’s workflow and job management services for ingesting media files, creating browse proxies, initiating Transcribe jobs and consuming the results. Additionally, Curator’s proxy streaming services and search indexes run on EC2 instances to deliver Curator’s user experience. RDS databases are used for persistent data storage.
If you’re a broadcaster who needs to meet stricter regulations for captioning offline content you can still use Curator + Transcribe to introduce speech-to-text into your first round of captioning, then take your auto-generated captions into a full caption editor to add more detail. Users can edit the captions in Curator and they’ll be written back into the WebVTT file which can be exported for editing in advanced tools. However, you choose to work, the integration will save you time and money. Not to mention the other benefits Curator offers: access all of your content from one place, search and find it easily, edit remotely and more.
MEET LEGISLATIVE REQUIREMENTS FOR ACCESSIBILITY
Section 508 of the Rehabilitation Act has resulted in a legal need for captioning much of the content produced by federal agencies, as well as some universities and colleges. It’s important to make content as accessible as possible, but content creators need to find a way to do this without spending too much time and money. Again, combining Curator and Amazon Transcribe can help educators to solve their content accessibility problem by adding automation to their captioning workflow. Once captions have been added, content creators can push their content to the online platforms they want to share it on, all from one centralized location.
CAPTION YOUR ONLINE MARKETING CONTENT
Today’s consumers watch on the go, on their mobile devices, surrounded by strangers. Up to 85% of online video is watched without sound. Captioning is a simple way to ensure that your messages are delivered effectively without the sound turned on, but doing it manually is immensely time-consuming when you’re producing lots of videos for social media every day. Speech-to-text captions can help to solve this problem: a basic level of captioning for live content is all you need to ensure that your videos are easily consumable without the sound. Some social media sites have a free captioning service, but relying on these can mean losing ownership of your content quality. Using a professional video management tool like Curator with speech-to-text services ensures that you have control over quality and can guarantee consistency across all of your content. Plus, Curator will help you to manage your content once it becomes too big for you to manage manually.
AUTOMATE YOUR METADATA GENERATION
Metadata is key for most content creators – without it, they’re never going to find what they’re looking for again. From this stem one of the less obvious – but widely relevant and transformative – uses of Transcribe + Curator. By captioning your content, you’re creating metadata every time anyone speaks. And because this process is automated, the creation of this metadata is effortless. The captions are stored in two ways: in a WebVTT file which means they can be played back in the Curator HLS video player; and as virtual subclips in Curator. These are indexed in Curator’s Solr search index.
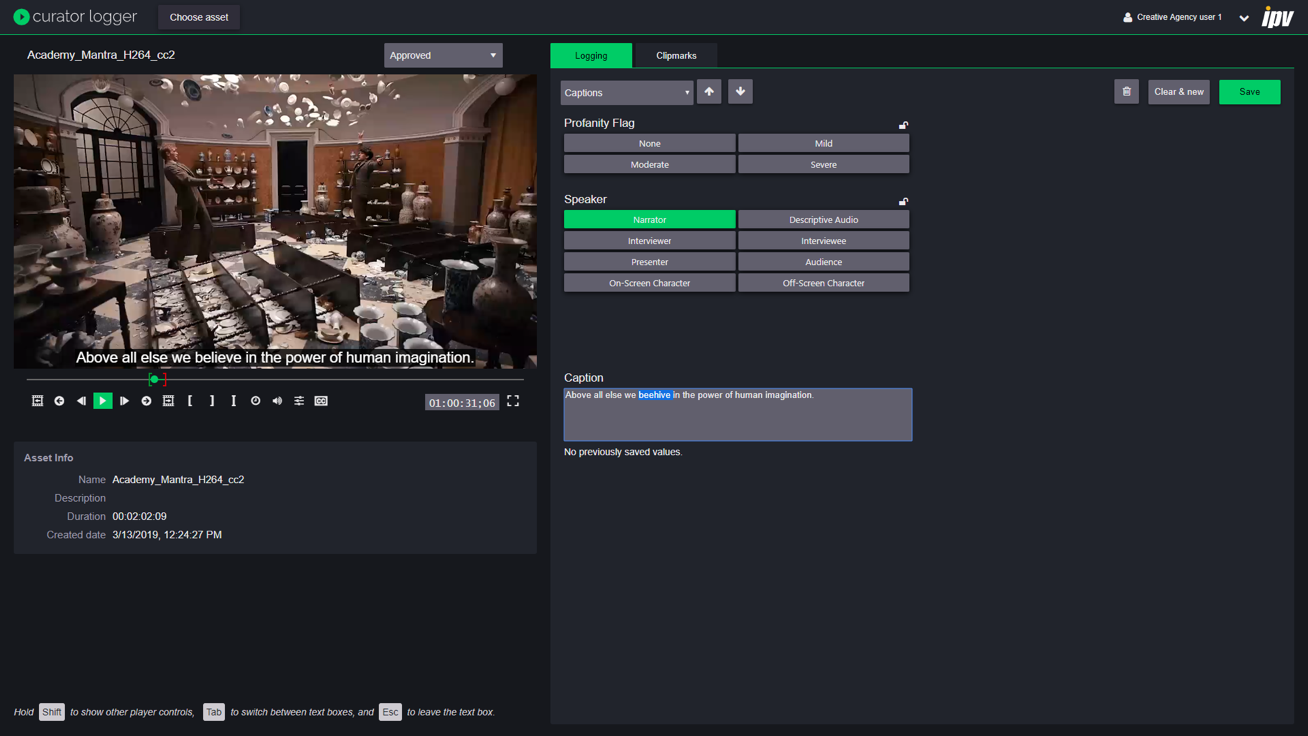
Curator also adds value to this metadata by making it searchable. For example, if you’re looking at an hour-long episode from a series, but want to see just the clips where a certain character is mentioned, you’re able to just type in the name of the character and see everything where he or she is mentioned. Not only does this save time, it also allows you to add more detailed metadata than would ever have been possible to create manually. Even more intelligence is brought here because Curator can join searches across header/media level metadata (e.g. show name) and subclips (ie. captions). This means that even basic users can do searches like “show me every time the word ‘coffee’ is said in the Friends episode ‘The One With Ross’s Wedding ’”.
One of the issues that often arises from this kind of ML-generated metadata is that users end up feeling deluged by it and can’t make the most of it. However, Curator works to avoid this issue by providing users with information about ranking and provenance to help them understand where their metadata has come from. Once they have this information, they can make a judgement about how useful it is to them, and sort and filter content based on the type of metadata available. For example, users may have access to metadata that has come from three different sources, such as speech-to-text, object recognition and manual logging. If all three of these agree that a clip contains a soda can from a certain brand, you’ll know that it’s likely to be correct. However, if the different sources don’t agree, you might want to double check by watching the clip. Giving the user all of the information means that it’s easy to be certain that your metadata is accurate and useful.
CONCLUSION
By combining AWS speech-to-text services with the Curator media management platform you can more easily take advantage of new technologies. The integration allows you enhance your captioning and metadata workflows in one go, whilst reducing costs and increasing accuracy.