Front-End Web & Mobile
7 ways to reduce latency in your AWS AppSync API
Overview
AWS AppSync is a serverless GraphQL service that makes it easy to create single endpoint GraphQL and realtime APIs. AppSync lets you combine disparate data sources and deliver the results to applications in an expected format, as specified by your API’s schema definition. As with any GraphQL service, there are mechanisms in place to optimize your API as your application and requirements increase over time.
Listed are 7 ways that you can optimize your AppSync API to reduce latency.
1. Look Aheads
One of the core benefits of using GraphQL, is its ability to mix and match how data is resolved at the field level.
Review the following schema:
While contrived, it is quite possible for the id and name of the product to come from a Product database, whereas the ProductDetails field would come from Inventory service that could be owned by a completely separate team.
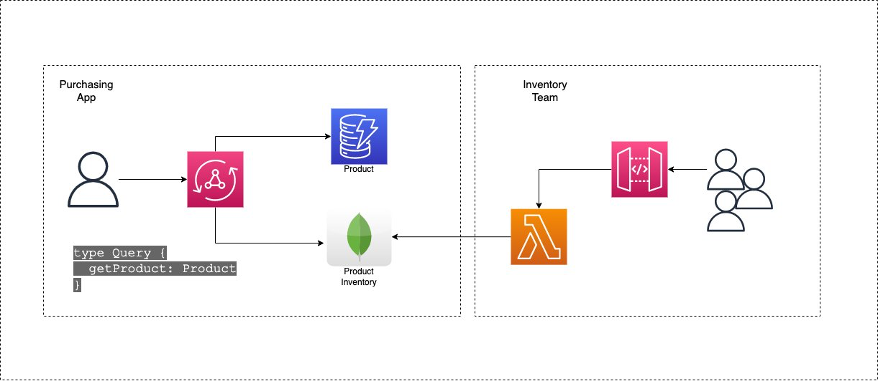
Because not every application may need to make this request, latency is reduced by allowing applications to choose what information is important to them. For example, an application that needs to display a list of Products may only need to list names. However, an eCommerce application would likely need to tell customers how many items are left in stock.
2. DynamoDB Batching
AppSync offers direct integration with Amazon DynamoDB however read and write operations aren’t confined to one table at a time. With DynamoDB batching, latency can be reduced by targeting several DynamoDB tables at once. From the docs this yields the following benefits:
- Pass a list of keys in a single query and return the results from a table
- Read records from one or more tables in a single query
- Write records in bulk to one or more tables
- Conditionally write or delete records in multiple tables that might have a relation
3. Lambda Batching
Let’s examine the following AppSync schema
Above, we’re using Amplify’s automatic code generation to create a Global Secondary Index (GSI) on our Ticket model so we can query tickets by their product name and status.
However, each USER that is resolved on the requester and assignee fields actually come from a Lambda function that queries data from a MySQL database.
To avoid an N + 1 problem, where N number of products queries would trigger N number of requests for a requester and assignee , we can configure the Lambda with a batch size, so that it runs once, and returns an array of results. Note that the array of results returned, must match the order in which the Product data was resolved.
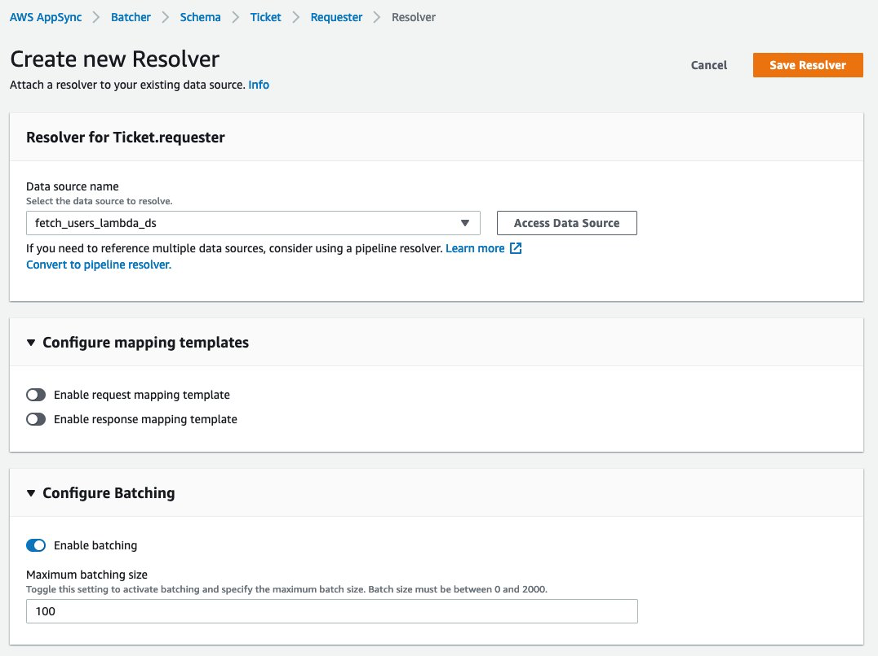
Learn more about Configurable Batching for Lambda resolvers in its release blog.
4. Condition check failures
Wrapping up the discussion on how AppSync interacts with DynamoDB, we have condition check failures.
When a mutation operation occurs for a particular item in a table, that will map to either a PutItem, UpdateItem, or DeleteItem operation in DynamoDB.
This operation can be further refined by specifying a Condition that must be met, in order for the operation to succeed. When those conditions aren’t met, we have the ability to invoke a Lambda function to have control how best to proceed.
The JSON snippet represents a DynamoDB resolver that will only succeed in putting a new record in the table if the id of that item doesn’t already exist.
However, a conditionalCheckFailedHandler key can be applied such that a custom strategy is used. In this case, by specifying the ARN of a Lambda function, one can determine if the call should fail or succeed.
To learn about the data the Lambda function receives, review the docs here.
5. Local Resolver
Often times, frontend applications don’t need to modify data, they simply need to pass the data through so that another service can take be notified and take action. Some applications mimic this behavior by updating a counter, or insignificant attribute on the item being acted up. However, this small change takes time that is dependent on network requests. Local Resolvers solve that.
Local resolvers simply pass data from the request mapping template to the response mapping template. The benefit is that subscribed clients still get notified of the incoming data.
This simple, but powerful mechanism is what powers AppSync’s Pub/Sub APIs by offering subscriptions as a standalone feature. By leveraging local resolvers, not only is latency improved by not having to store data, but that means storage and write capacity costs are lowered as well.
6. Caching and compression
Many modern applications have the ability to take advantage of predictable queries and workflows. With caching, we now have the ability to pass on those benefits to customers. Once enabled, an incoming request is first evaluated against a cache and if the request has already been made before the cache expiration, then the data is served from there instead.
This feature works hand-in-hand with compression. When compression is enabled, any payload size ranging from 1,000 to 10,000,000 bytes can then take advantage of being formatted as gzip or br so long as the client puts that value in the respective Accept-Encoding header.
To learn more about caching and compression, visit the docs page for more details.
7. X-Ray
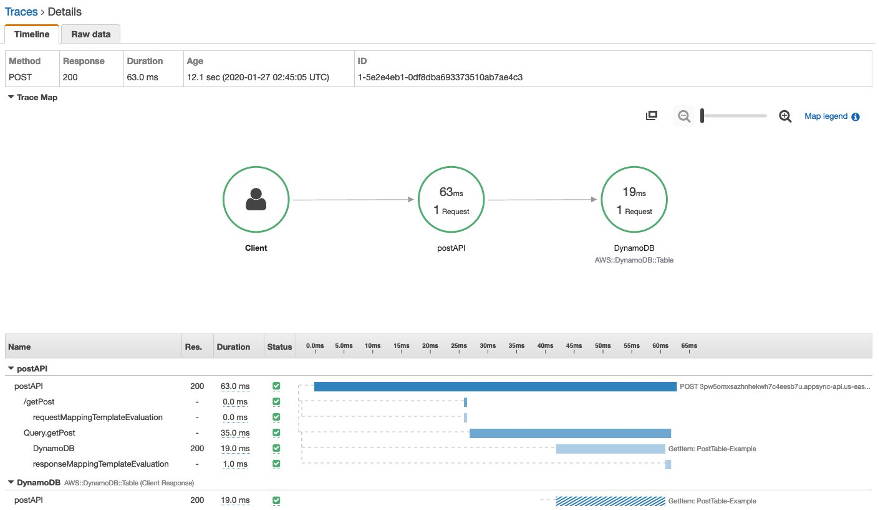
With all of the above-mentioned ways to reduce latency, it may be difficult to choose which options are a priority and would best suite your needs. That’s why the last suggestion is to enable AWS X-Ray tracing for your AppSync API.
When enabled, you’ll then be granted visibility into the requests as they are executed in your API.
Similar to the network tab in browsers, X-Ray tracing will details the “hops” a request made before a response was available
Conclusion
In this post we look at ways you can optimize your AppSync API to reduce latency. When resolving your data with a Lambda function configured with batching enabled, this has the downstream effect of reducing costs as well. While there are always more optimizations that can be achieved, specifically reducing latency will have a direct impact on your customer retention and their overall experience.
To learn more, visit the AWS GraphQL page for more information on adopt AppSync in your own applications.