AWS Startups Blog
Datavant Uses Batch to De-Identify Health Data

Guest post by David Gold, Data Engineer, Datavant
Datavant enables health companies to share sensitive health data securely. An important part of this process is de-identifying records so that they can be used in research or analytics contexts where identifying information is unneeded or required by law to be removed. Datavant supports both on-premise and cloud workflows to de-identify data.
On-premises (on-prem) and cloud software have complementary benefits and drawbacks. Cloud services allow our engineers to iterate quickly, pushing out improvements continuously without having to “ship” software, and allow developers more insight into how the service is being used. However, they also require additional precautions to ensure data is secure during transit between the cloud and the client’s environment. Some of our clients see a cloud-hosted solution as an easier-to-use alternative to on-prem because it doesn’t require installing software or configuring their own environment to handle personally-identifiable information (PII) and de-identified data.
In this post, we share a simple approach to turn our native on-premise application into an AWS-hosted cloud service over the course of a single sprint cycle.
Adapting the On-prem to the Cloud
Datavant’s on-prem application is a command line executable that operates on files and directories in a file system. It connects to Datavant’s server to authenticate the user and retrieve client-specific configuration information. Once authorized, the software operates on the PII in memory, de-identifying it to meet our clients’ requirements.
When setting out to build a cloud version of our de-identification software, we aimed to meet two goals; the service had to satisfy the needs of our clients and be easy for our engineering team to build and maintain. To address this first goal, we designed our cloud API to operate as similarly as possible to our already successful on-prem application. This has the added benefit of allowing us to build the cloud application as a wrapper which feeds data and configuration information to the same core libraries, drastically reducing the time needed to get something up and running. The API, input and output data file formats, were left largely unchanged from the on-prem application.
This is crucial, as it allows our clients using the two services to share data without compatibility concerns. Inevitably, some changes were made when adapting on-prem to the cloud. Namely, we created a way for clients to transmit data to/from our environment and a system to notify clients of the status of their jobs.
After the product requirements were settled, we turned to AWS, looking for a way to deploy our cloud application. Luckily, AWS has a number of useful infrastructure tools to build a system that is lightweight, scalable, and easy to maintain.
AWS Batch
AWS Batch manages fleets of EC2 instances to perform batch processing jobs. Some convenient features are job templates, job queuing, and automatic scaling of compute resources to meet job demand. For us, the ability to set up a continuous deployment pipeline to AWS Batch, using Docker, ECS, and Travis CI was crucial. This meant that our on-prem and cloud applications could share code and remain in sync over time.
AWS API Gateway
AWS API Gateway greatly simplifies the process of deploying a web-facing application, allowing us to stand up a simple secure endpoint in a matter of minutes. It can flexibly parse HTTP requests and manage client authentication / authorization to our service while providing convenient integrations with AWS Lambda.
AWS Lambda
AWS Lambda is the glue that holds this whole system together. It is used to shuttle request parameters from API gateway to our application and then report changes in the status of a job back to the client. Like every other component of this system, this library code resides within our mono-repo and is continuously deployed to AWS Lambda using Travis CI. Lambda is serverless, which means that we don’t have to worry as much about securing, and monitoring a fleet of virtual machines.
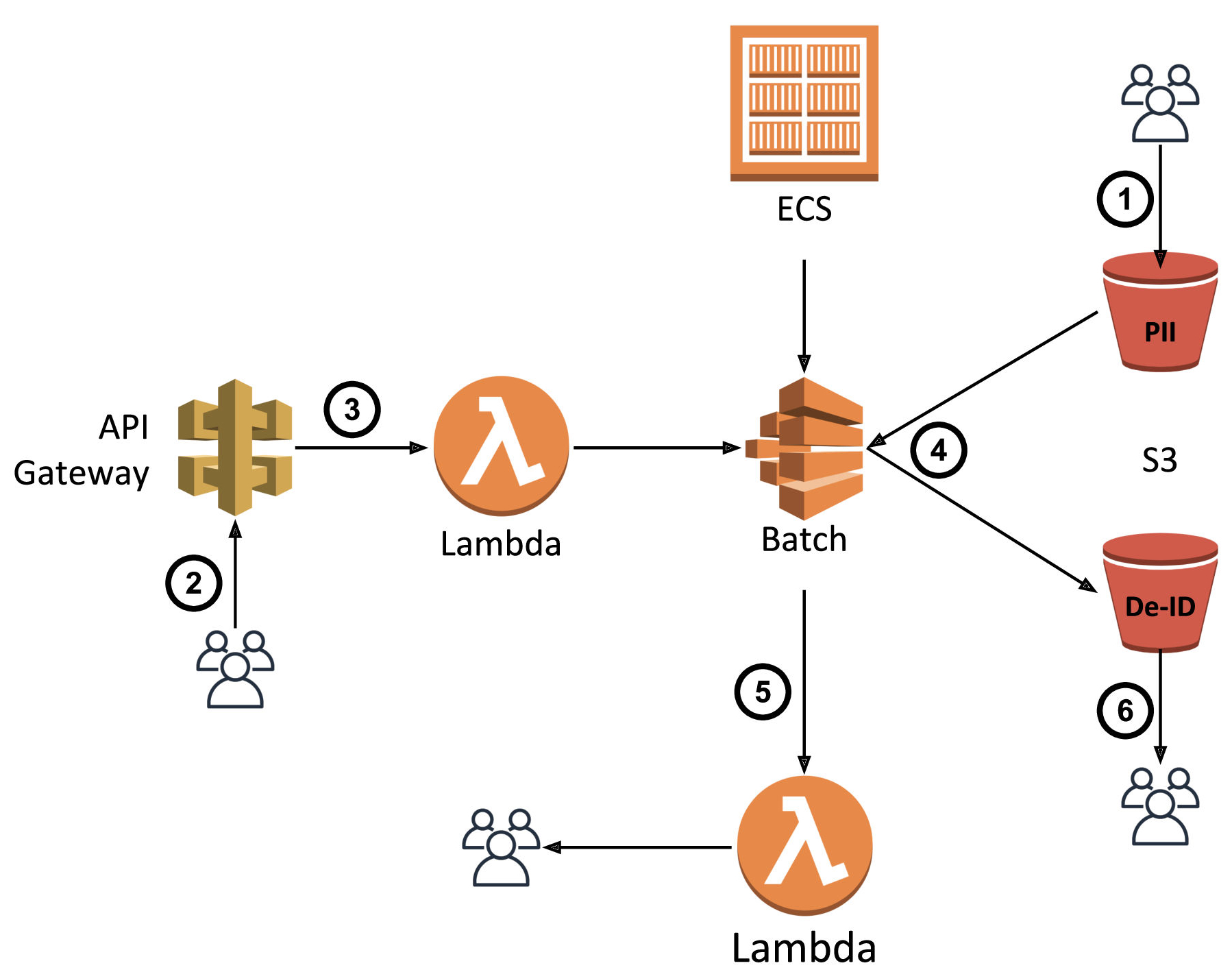
End-to-end User Flow
- After signing a business associate agreement with Datavant, the client uploads their PII input file to an S3 bucket in our environment. Historically, we’ve allowed clients to accomplish this by using the AWS S3 CLI directly or with an SFTP interface, courtesy of AWS Transfer for SFTP.
- The client invokes our batch cloud de-identification service by issuing an HTTP request to a specified endpoint while providing their client-specific credentials.
- Behind the scenes, API Gateway authenticates and authorizes the client then forwards the request parameters to the first of two Lambda functions. The job of this function is to parse and validate the request parameters and then create a properly-configured batch de-identification job. It then adds this job to a queue, managed by AWS Batch using Batch’s API.
- Once AWS Batch receives the job, it loads the latest version of our de-identification application code from a docker image stored in AWS ECR onto a managed EC2 instance. The application reads in personally-identifiable information (PII) records from a location in S3, processes them, and writes out de-identified records to another location in S3 as specified by the client’s configuration.
- Batch will generate and write an event to AWS Cloud Watch. A second Lambda function listening to the Cloud Watch Event stream filters and parses the events. Upon success or if an error occurs during processing, the Lambda function notifies the client via email and writes logs to our system.
- Assuming the job ran successfully, upon receiving an email notification, the client can retrieve their de-identified output data from another location in S3.
Future Enhancements
Since standing up our cloud-hosted de-identification service within a sprint, we’ve learned of a number of other AWS features which integrate nicely into our design and provide additional automation and functionality. AWS Step Functions can be used to sequentially stitch together AWS Batch, Lambda as well as provide convenient error handling, logging, and retry logic. AWS S3 has a built-in Lambda integration that can be used to trigger execution of our cloud de-identification application on any PII that lands in a particular S3 location.
Hopefully this guide is useful to others developers new to AWS looking to migrate their own services from on-prem to the cloud in a short amount of time. With this architecture, we were able to rapidly configure a cloud-hosted API nearly-identical to that of our on-premise software while making minimal changes to the code and using scalable infrastructure that requires minimal maintenance from our engineers. Please reach out to me at david@datavant.com with any questions or feedback!