AWS Startups Blog
Containers for KidTech: Here’s How We Manage Them at Scale
Guest post by Nicolas Trésegnie, Chief Architect, SuperAwesome
This post is about SuperAwesome’s journey with containers and how our decisions allowed us to focus on making the Internet safer for kids. Containers are a critical part of our infrastructure, and they allowed us to grow SuperAwesome very rapidly without losing focus on our goals. Sometimes, some really simple changes can save you money, give you a simpler infrastructure and a better developer experience, and reduce maintenance.
What We Do
Every day, 170,000 children go online for the first time. Unfortunately, the Internet was built by adults for adults, without taking the specific needs of children into account. As a result, many of the platforms they use are collecting vast amounts of their personal data, which is now illegal, and haven’t been created for child engagement in terms of design or moderation.
Our mission at SuperAwesome is to make the Internet safer for kids. To do this, we built a technology platform that helps all players in the digital ecosystem create kid-safe digital engagement, including apps and sites, as well as additional functionality like video, safe ad monetization, authentication and community functionality.

At a technology level, we want to maximize our time building technology that keeps kids safe online. We also do our best to keep our platform simple. We go for tools and technologies that are maintainable, that allow us to get things off the ground quickly, and that can be improved in an iterative way.
From Development to Production
Our journey with containers started four years ago. At the time, to get their development environment up and running, developers had to clone a few repositories, build some virtual machines, and run them on their laptops. This was resource intensive and unreliable. It took new developers on our team a few days to even get set up. Then, that environment would use almost all the resources on their laptops.
To solve this problem, we introduced containers into our development process. We took all these projects and dockerized them. We got rid of all the virtual machines but one (docker for Mac did not exist at the time), installed docker and docker-compose on it, and ran our projects in containers.
At the time, our production environments were managed by an external company. We had one consultant working full time on it. One day, he went on holiday, and that external company sent us a replacement. The new guy made a manual change in production, brought our whole system down, and then couldn’t fix it. The team and I spent the whole day and night recovering from it. After that, we took our infrastructure back in-house and used containers in production.
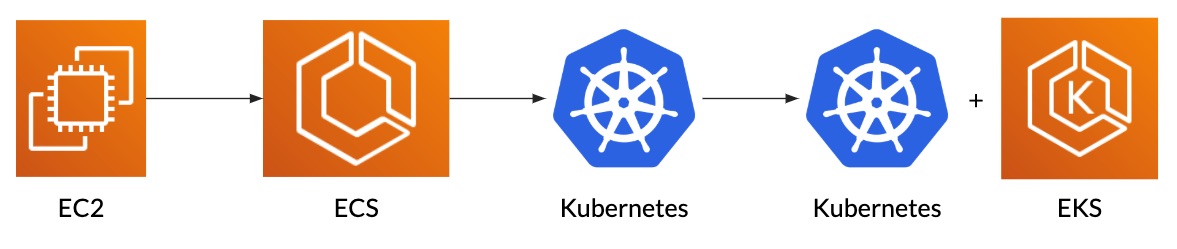
To start, we improved what we had on EC2 in the same way as our development environment. Over the following months, the team created more and more small services. This increased the number of EC2 instances that we were running and our infrastructure costs. To keep them under control, we decided to switch to something more adapted to containers. Kubernetes was in its infancy, so we opted for AWS Elastic Container Service (ECS). It did not have many features, but we knew it would be stable and reliable.
During the following two years, Kubernetes changed quite a lot. It got more features, became more stable, and grew its community. At some point, the benefits of switching were higher than the cost and the time it would take us. We created two Kubernetes clusters and a script to transform our ECS tasks into helm charts, and we switched to Kubernetes.
Switching to EKS
Over these four years, SuperAwesome changed significantly. We went from running a handful of EC2 instances in one region to hundreds in different regions and AWS accounts – from a few hundred of HTTP requests per minute to tens of thousands per second, from a few million analytics events per day to more than a billion, and from two Kubernetes clusters to more than twenty…
Growth brought complexity. To keep things simple and manageable, we switched to AWS’ Elastic Container Service for Kubernetes (EKS). This allowed us to keep benefits from all the features of Kubernetes without the hassle of managing the clusters ourselves.
What should we manage?
To run a Kubernetes cluster, you need to run masters (the control plane) and nodes (the data plane). If you want a highly available cluster, you want to run at least three masters in different availability zones. On these masters, you need to run a few services. For example, etcd. – it is a distributed key value store used by Kubernetes to store its data. You need to set it up, secure it, back it up, and think about disaster recovery. As your cluster grows, you also need to think about whether you want to scale your masters up (add more CPU and memory) or out (start more of them).

While these are extremely interesting engineering challenges, solving them does not bring us closer to our goal of a safer internet for kids. Every hour spent on this is an hour that we are not spending making kidtech.
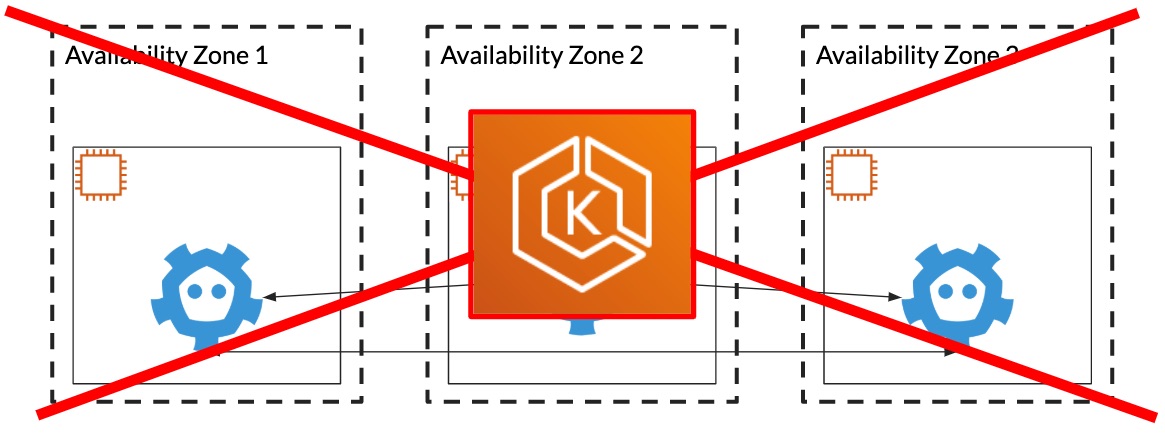
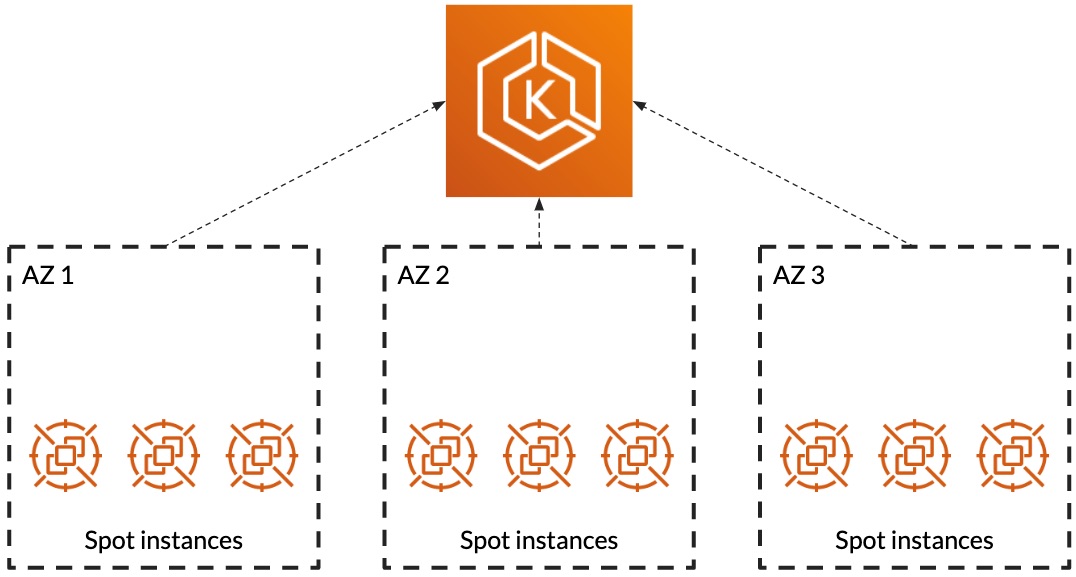
We still want to manage the nodes ourselves. We want to run some extra security tools and services and all of the nodes. Also, we want to have the ability to take advantage of spot instances. Today, 90% to 95% of our production workloads run on spot instances on Kubernetes.
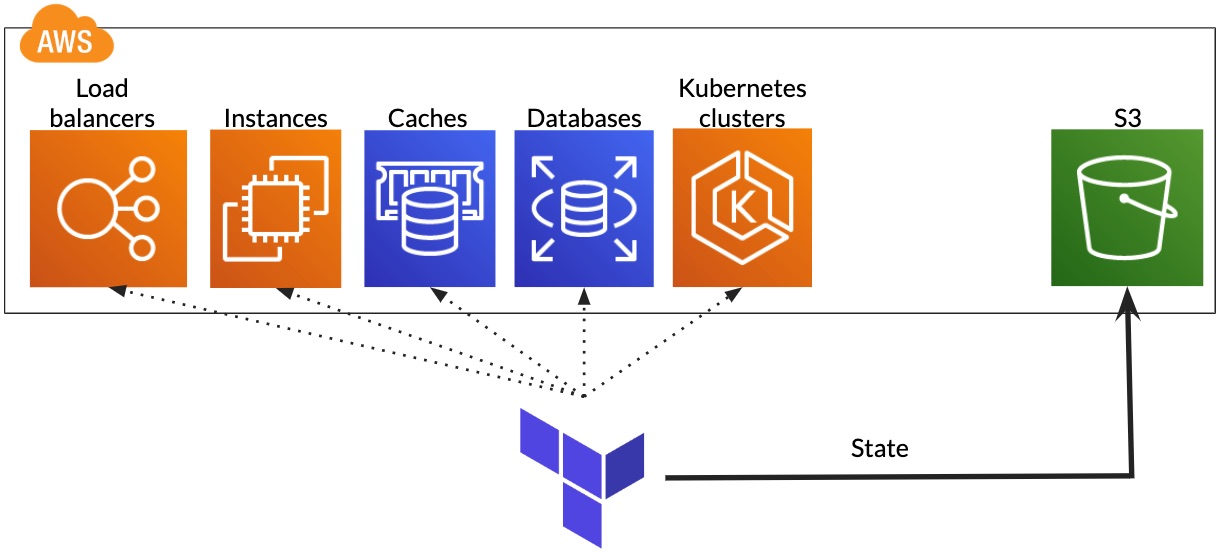
We were already using a number of AWS services. Wherever possible, we set them up using infrastructure as code with Terraform. EKS has a terraform integration, so it was easy to integrate with our existing automation.
Interestingly, using EKS is also cheaper. When we ran our own Kubernetes clusters, we would use 3 on-demand m4.large instances to avoid t2/t3 instances that have CPU credits in addition to 100GB of disk space, and we would monitor them using Datadog (15$/master). This cost us around $291 per cluster per month ($0.100/hour * 720 hours + $0.10/GB * 100GB + 15$). With EKS, we pay a flat fee of $144 ($0.20/hour * 720 hours).
Security and Networking
When dealing with containers, two of the recurring discussion points are security and networking. It would take a long time to go to the bottom of these topics, but here are two aspects that became easier to manage by switching to EKS.
When accessing some services provided by AWS, you need to go through IAM and authenticate with it. Then, the AWS API will check whether you have the right to perform the actions that you are trying to perform (authorization). With Kubernetes, you do something similar. First, you need to authenticate with the Kubernetes API. Then, using something like RBAC, Kubernetes will check that you are able to read, create, or modify Kubernetes objects.
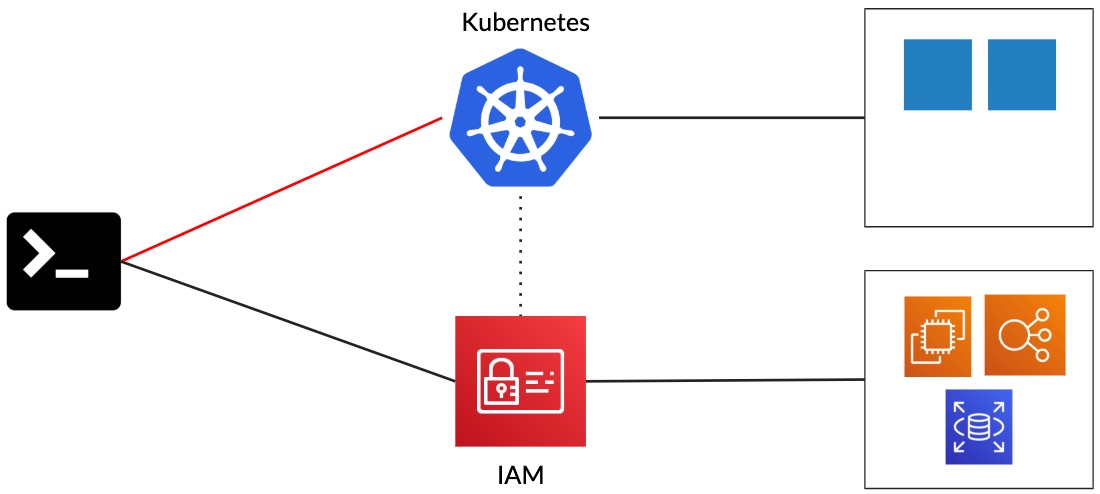
With EKS, you can authenticate to Kubernetes using the aws-iam-authenticator. In our case, this drastically reduced the number of kubeconfig files that we had to manage.
When running containers, you will have something similar to the setup below. Your EC2 instances get their IP addresses from one range and the containers from another. In our case, this adds some management overhead as we run clusters in multiple AWS regions, and we occasionally need to have pod-to-pod communication between clusters.

With the AWS CNI, pods are given an IP address on the VPC. With a small amount of configuration, you can have that pod-to-pod communication.
Once again, these things can be done without EKS, but that work would be undifferentiated heavy lifting. The aws-iam-authenticator can be used with clusters created with other tools like kops. Pod-to-pod communication across clusters can be done with other CNIs (or dealing with things like hostPort). For us, that extra work would have a big opportunity cost.
Load Balancing
If you run any kind of public API in your containers, you need to somehow make them accessible to the outside world. On Kubernetes, you create ingresses and run a reverse proxy (= ingress controller in this context). If, like us, you have a very dynamic environment, you would also need to create a network level load balancer.
Your traffic would flow like in the diagram below. The connections go to the load balancer that forward them to one of the reverse proxies where you terminate the SSL connections. Then, the requests are sent to the correct pods. If you have a highly available cluster, your traffic may well cross availability zone boundaries twice, and you will be charged for it twice (on AWS, traffic inside one availability zone is free).

There are different ways to solve this. Most solutions will force you to add some extra configuration or run some extra code to avoid having an unbalanced cluster.
To solve this for SuperAwesome, we simply got rid of our reverse proxy and switched to the application load balancer. As we are using EKS, it is aware of the ingresses defined on Kubernetes, and it can forward the traffic directly to the right pods.

Conclusion
We started with a very manual and unmaintainable setup. Slowly, we switched to containers, started deploying our code to more regions and environments, automated (almost) everything, and made the system more cost effective.
Now, more than 90% of our workloads run on spot instances (including some stateful services), which saves us a lot of money. By switching to EKS, we reduced the fixed cost of our Kubernetes clusters by 47% and reduced the time spent on maintenance by 80%. This also let us to take advantage of the Amazon VPC CNI Plugin and the Application Load Balancer to simplify our networking and reduce our data transfer costs.
All of this allowed us to stop doing undifferentiated work and focus on what really matters to us: making the Internet safer for kids. To learn more about why it is so important, have a look at the PwC Kids Digital Media Report 2019. To learn more about what SuperAwesome does, check out our website.
Do you have any questions? Would you have done things differently? If so, please don’t hesitate to get in touch!