AWS Startups Blog
Architecture II: Distributed Data Stores
It’s the Question that Drives Us, Neo
Why does AWS have so many data storage options? Which one is right for me? These are commonly asked customer questions. In this three-part blog series, I will attempt to provide some clarity. In the first part, I discussed the basics of high availability and how redundancy is a common way of achieving it. I also briefly mentioned that bringing redundancy to the data tier introduces new challenges. In this second part of the blog series, I discuss some of those challenges and common tradeoffs that you need to take into consideration while overcoming them. The third part of this blog series will build on this information and discuss specific AWS data storage options and which workloads each storage option is optimized for. After you read all three parts of this blog series, you will come to appreciate the richness of AWS data storage offerings and learn to select the right option for the right workload.
What’s Wrong with Relational Databases Anyway?
As many of you probably know, relational database (RDB) technology has been around since the 1970s and has been the de facto standard of structured storage until the late 1990s. RDBs have done an excellent job of supporting high-consistency transactional workloads for many decades and are still going strong. Over time, this venerable technology acquired new capabilities in response to customer demand, such as BLOB storage, XML/document store, full-text search, in-database code execution, data warehousing with its star schema, and geo-spatial extensions. As long as everything was squeezable in a relational schema definition and would fit on a single box, it could be done in a relational database.

Then, Internet commercialization happened and that drastically changed things, making relational databases no longer sufficient for all storage needs. Availability, performance, and scale were becoming equally important — and sometimes more important — than consistency.
Performance has always been important, but what had changed with the advent of Internet commercialization was the scale. It turns out that achieving performance at scale requires different techniques and technologies than what was acceptable in the pre-Internet era. Relational databases were built around the notion of ACID (Atomicity, Consistency, Isolation, Durability) and the easiest way to achieve ACID was to keep everything on the same box. Therefore, the traditional RDB approach to scaling was to scale UP, or in plain English, to get a bigger box.
Oh-oh, I Think I Need a Bigger Box
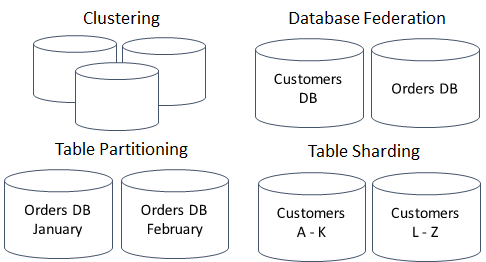
The solution to simply get a bigger box was fine until the Internet brought a load that was just too much for a single box to handle. This forced engineers to figure out clever techniques for overcoming the limitations of a single box. There are many different approaches, each with its pros and cons: master-replica, clustering, table federation and partitioning, and sharding (which one might argue is a specific case of partitioning).
Another factor that drove the proliferation of data storage options was availability. Users of pre-Internet systems were usually internal to an organization, which made it possible to have scheduled downtime during non-business hours, and even an unplanned outage had limited blast radius. The commercial Internet changed that as well: now everyone with access to the Internet was a potential user, so unplanned downtime had potentially large blast radius, and the global nature of the Internet made it difficult to determine non-business hours and have scheduled downtime.
In the first part of this blog series, I discussed the role of redundancy in achieving high availability. When applied to the data storage layer, though, redundancy brings a new set of interesting challenges. The most common way of applying redundancy at the database layer is the master/replica configuration.

This seemingly simple setup has one huge difference when compared to a traditional single-box relational database: we now have more than one box separated by a network. When a database write occurs, we now need to decide when to consider it complete: as soon as it is persisted on the master, or only after it is persisted on a replica (or even n replicas if we want higher availability — check the first part of this blog series to see what adding another box does to the overall availability). If we decide that persisting it on the master is enough, we risk losing data if the master fails before replicating the data. If we decide to wait until the data is replicated, we incur latency penalty. In rare cases when a replica may be down, we need to determine whether to accept the write anyway or decline it.
Thus, from a world of consistency by default, we have entered a world where consistency is a choice. In this world, we could choose to have so-called eventual consistency, where the state is replicated across multiple nodes, but not every node has a complete view of the entire state. In our example configuration above, if we choose to consider a write complete as soon as it hits the master (or the master and any one replica, but not necessarily both), then we choose eventual consistency. It is eventual because every write eventually will be replicated to every replica. But at any point in time if we query one of the replicas, we have no guarantee that it contains all the writes made up to that moment.
Let’s Try On this New CAP
To recap, when data storage gets replicated (also known as partitioned), a system’s state gets distributed. This means that we leave the comfortable province of ACID and enter the brave new world of CAP. The CAP Conjecture was introduced by Dr. Eric Brewer from the University of California, Berkeley in 2000. In its simplest form it goes like this: a distributed system has to trade off Consistency against Availability against Partition Tolerance, and it can achieve only two out of three.

CAP Conjecture expanded the discussion about data storage beyond ACID and inspired the creation of many non-relational database technologies. Ten years after introducing his CAP Conjecture, Dr. Brewer issued a clarification stating that his original “pick two out of three” concept was greatly simplified in order to open up a discussion and help move it beyond ACID. This great simplification, though, led to numerous misinterpretations and misunderstandings. In a more nuanced interpretation of CAP, all three dimensions are understood to be ranges rather than Booleans. Also, it is understood that distributed systems most of the time work in non-partitioned mode, in which case they need to make a tradeoff between consistency and performance/latency. In rare cases when partitioning does happen, the system has to choose between consistency and availability.

Tying it back to our master/replica example, if we choose to consider a write complete only when the data is replicated everywhere (also known as synchronous replication), we will be favoring consistency at the expense of write latency. On the other hand, if we choose to consider a write complete as soon as it persists on the master, and let the replication happen in the background (also known as asynchronous replication), we will be favoring performance over consistency.
When a network partition occurs, distributed systems enter a special, partitioned mode in which they are making a tradeoff between consistency and availability. Back to our example: replicas may continue to serve queries even after they lose connection to the master, favoring availability over consistency. Or, we may choose that the master should stop accepting writes if it loses contact with replicas, thus favoring consistency over availability. In the age of the commercial Internet, choosing consistency usually means lost revenues, therefore many systems choose availability. In this case, when a system gets back to its normal state, it may enter a recovery mode, where all accumulated inconsistencies get resolved and replicated.
While we are on the subject of recovery mode, it is worth mentioning a type of distributed data store configuration called master-master (or active-active). In this setup, writes can go to multiple modes and then get mutually replicated. With such a system, even a normal mode gets complicated, because if two updates of the same piece of data happen at about the same time on two different master nodes, how do you reconcile them? And if such a system has to recover from a partitioned state, things get even worse. While it is possible to have a working master-master configuration and there are some products that make it easier, my advice is to avoid it unless absolutely necessary. There are many ways to achieve a good balance of performance and availability that don’t require the high complexity cost of master-master.
The Common Patterns of Many Modern Data Stores
One common approach that provides a good mix of performance/scale and availability is to combine partitioning and replication into a configuration (or rather into a pattern). This is sometimes referred to as a partitioned replica set.

Be it Hadoop or a MongoDB cluster, they essentially conform to this pattern, and so do many AWS data storage services. Cassandra, which is based on the principles outlined in famous Amazon Dynamo white paper, takes this one step further, where every node in a cluster can be a dispatcher and every node in a replica set can be a master for a particular write. This eliminates potential points of failures at the Dispatcher and Master level, making overall architecture even more resilient. Let’s review some of the common characteristics of a partitioned replica set:
- The data is partitioned (i.e., split) across multiple nodes (or rather clusters of nodes). No single partition has all the data. A write should go to only one partition. Multiple writes can potentially go to multiple partitions and therefore should be independent of each other. Complex, transactional multi-record (and thus potentially multi-partition) writes are discouraged, as they could tie down the entire system.
- The maximum amount of data a single partition can process may become a potential bottleneck. If a partition is reaching its bandwidth limits, adding more partitions and splitting the traffic across them helps solve the problem. Thus, you can scale this type of system by adding more partitions.
- A partition key is used to distribute data across partitions. You need to choose a partition key carefully so that reads and writes are as equally “spread” across all partitions as possible. If reads/writes are clustered, they may exceed the bandwidth of a specific partition and affect the performance of the entire system, while other partitions will be under-utilized. This is known as a “hot partition” problem.
- The data is replicated across multiple hosts. These could be completely separate replica sets for each partition or overlaying multiple replica sets on top of the same group of hosts. The number of times a piece of data is replicated is often called replication factor.
- This configuration has built-in high availability: the data is replicated across multiple hosts. Theoretically, the failure of a number of hosts that is less than the replication factor will not affect the availability of the entire system.
All this goodness, with its built-in scalability and high availability, comes with a price tag: it is no longer your Swiss Army Knife, single-box relational database management system (RDBMS). It is a complex system with many moving parts that require managing and parameters that need fine-tuning. Specialized expertise is required to set up, configure, and maintain these systems. In addition, a monitoring and alarming infrastructure is needed to ensure that they stay up. You can certainly do it yourself, but it will not be easy and you may not get it right the first time, nor the second.
To help our customers get the value of highly scalable and available data stores without the management overhead, AWS offers various managed data/storage services. Because there are many different dimensions for optimization, there is no single magic data store, but rather a set of services, each optimized for a particular kind of workload. In the next blog article, I will go over the data store options offered by AWS and discuss what each one is optimized (and not optimized) for.
This proliferation of data stores, while causing some choice-related headaches, is a really good thing. We just need to move beyond our conventional thinking of having a data store for our entire system, and adopt a mindset of using many different data stores within the system, each servicing a workload for which it is best suited. For example, we could use the following combination:
- High-performance ingest queue for an incoming clickstream
- Hadoop-based system for processing the clickstream
- Cloud-based object storage for low-cost, long-term storage of compressed daily clickstream digests
- Relational database for metadata that we could use to enrich the clickstream data
- Data warehousing cluster for analytics
- Search cluster for free-text searches
All of the above could be part of a single subsystem named something like Web Site Analytics Platform.
Summary
a. The commercial Internet brought with it scale and availability demands that could no longer be satisfied by the Swiss Army Knife of RDBMS.
b. Adding horizontal scale and redundancy to the data store increases complexity, makes ACID more difficult, forces us to consider CAP tradeoffs, and creates many interesting opportunities for optimization and specialization.
c. Use multiple data stores in your system, with each serving the workload that it is most suitable for.
d. Modern data stores are complex systems, requiring specialized knowledge and management overhead. With AWS, you can get the benefits of specialized data store without this overhead.