AWS Startups Blog
Monitoring SageMaker ML Models with WhyLabs
Guest post written by Danny D. Leybzon, WhyLabs MLOps Architect and Ganapathi Krishnamoorthi, AWS Solutions Architect
![]() As the real-world changes, machine learning models degrade in their ability to accurately represent it, resulting in model performance degradation. That’s why it’s important for data scientists and machine learning engineers to support models with tools that provide ML monitoring and observability, thereby preventing that performance degradation. In this blog post, we will dive into the WhyLabs AI Observatory, a data and ML monitoring and observability platform, and show how it complements Amazon SageMaker.
As the real-world changes, machine learning models degrade in their ability to accurately represent it, resulting in model performance degradation. That’s why it’s important for data scientists and machine learning engineers to support models with tools that provide ML monitoring and observability, thereby preventing that performance degradation. In this blog post, we will dive into the WhyLabs AI Observatory, a data and ML monitoring and observability platform, and show how it complements Amazon SageMaker.
Amazon SageMaker is incredibly powerful for training and deploying machine learning models at scale. WhyLabs allows you to monitor and observe your machine learning model, ensuring that it doesn’t suffer from performance degradation and continues to provide value to your business. Today, we’re going to demonstrate how to use WhyLabs to identify training-serving skew in a computer vision example for a model trained and deployed with SageMaker. WhyLabs is unique in its ability to monitor computer vision models and image data; whylogs library is able to extract features and metadata from images, as described in Detecting Semantic Drift within Image Data. The ability to create profiles based on images means that users can identify differences between training data and serving data and understand whether they need to retrain their models.
To follow along with this tutorial, we’ll utilize the WhyLabs AI Observatory, which you can access through the WhyLabs free, self-serve Starter tier.
Prepare the data and profile the training dataset with whylogs
The WhyLabs AI Observatory helps data scientists and machine learning engineers prevent model performance degradation by allowing them to monitor machine learning models, the data being fed to them, and the inferences they generate. It leverages the open-source library whylogs to generate “data profiles” (statistical summaries of datasets); these profiles are then sent to the WhyLabs platform, which allows users to analyze and alert on changes in these profiles over time.
For this example, we will build a simple model using SageMaker’s built-in algorithm for multi-label Image Classification. We will leverage whylogs’ unique ability to profile image data for data profiling and send the profiles to the WhyLabs platform for monitoring and observability. We are leveraging pycocotools 2017 images dataset for this example. This is a huge dataset with over 80 classes of images. For ease of use, we will consider only four classes and profile one image per class in the training dataset and send it to the WhyLabs platform.
The model in this blog was built using Python3 in an AWS environment on a Jupyter notebook instance. You can also run it in a Jupyter notebook on a local machine configured to run Amazon SageMaker training jobs. You will need an instance with Python3 and other Python libraries like SageMaker and WhyLabs used in the code. The dataset that we use is closer to 1GB, so make sure you have enough space in your notebook instance to download and process this dataset.
The IAM role attached to the notebook should have read and write permissions to Amazon Simple Storage Service (Amazon S3), and it should also have the access to launch training jobs and deployment endpoints in SageMaker. If you are running your notebook outside of AWS, you may want to ensure that you assume an IAM role that has these permissions attached.
Let this dissect the code to understand the flow.
First, we need to download pycocotools and install Python libraries using pip install.
Next, we will need to import certain libraries, including the SageMaker library for model training and deployment, the whylogs library for data profiling, and some standard Python libraries for numeric and image data manipulation.
In order to utilize WhyLabs, we need to specify an API key and org ID as environment variables. To generate your own API key and org ID, follow this documentation for generating the key and ID using your free WhyLabs account.
We will use SageMaker’s built-in algorithm for image classification by referencing the latest container image as below
Next, we’ll download the images from pycocotools. In our example, we will download a 2017 version of the image repository called ‘val2017,’ which also comes with an annotations json file.
As a standard practice, we will unzip the file to access the underlying images and annotations file.
To make it simple, we will choose the first four classes in pycocotools images for extraction. The category ids are mapped as below:
- Person
- Bicycle
- Car
- Motorcycle
We will use pycocotools built-in libraries to extract images from these four classes by referring to the annotations and creating a lst file. A lst file is a text file that consists of a list of pointers to images in other files. The below code snippet gets the four image categories listed above and extracts the images within each category. A lst file is constructed with the image ids and the labels as shown below.
Now that we’ve extracted our training data, we can profile it and send those profiles to WhyLabs in a few easy lines of code.
Profiling these images should take less than a second. From here, we can navigate back to the WhyLabs UI (where we had previously generated our API key) and head to the Model Dashboard to verify that our model is now populated with these profiles.
As we can see, our “Image Classifier” model is now populated with some profiles. We can explore this “baseline” training profile by navigating to the model summary page and then drilling down to that particular profile.
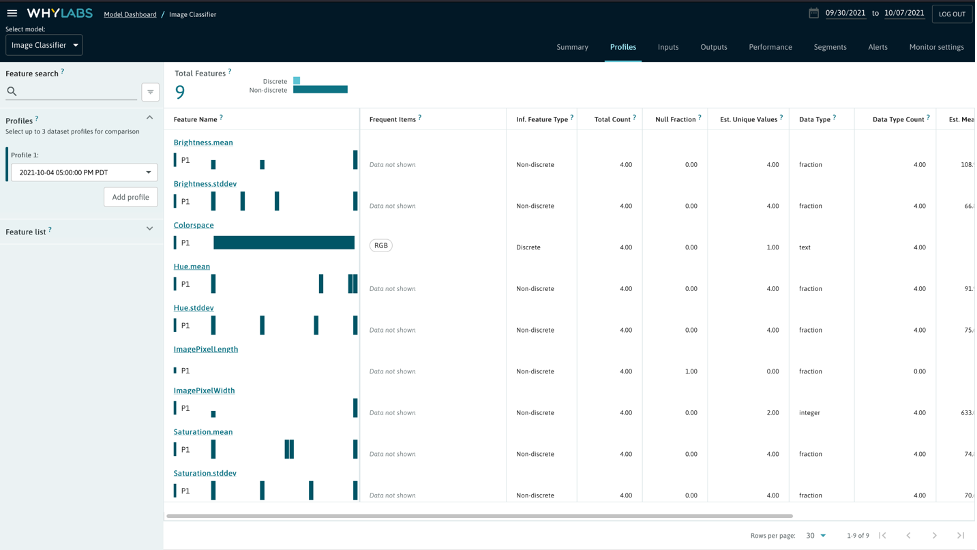
As illustrated above, whylogs was able to extract some key metadata (such as the pixel width and pixel height) and image features (such as the brightness mean and the standard deviation within the saturation) from the images we fed it. One particularly interesting piece of metadata is the ImagePixelWidth, which we will return to after uploading a profile from our inference dataset that doesn’t match the training dataset.
Train and deploy the model with Amazon SageMaker
Let us now move on to our standard practice of creating the lst file and splitting the input dataset into train and validation channels for the image file and the lst file.
We now configure the SageMaker training job with required parameters including the container image for object detection algorithm, IAM role, type of training instances, number of training instances, maximum training time in seconds, EBS volume storage, input mode and output location of the model artifact. For deep learning, we normally recommend GPU instance families like P2, P3 etc. as training is much faster on a GPU instance, but if you are on a budget or attempting to explore and learn, you can use CPU instances like C5, C4 and C3. In the below code we are using a GPU instance for training.
With any SageMaker training, it’s important to set hyperparameters for better accuracy. Every built-in algorithm would need a certain set of hyperparameters (required and optional) to be tuned as listed in the documentation. Here we set some static values to hyperparameters, but you can also pass on a range of values in a json document as shown here.
We then set up four different channels for the SageMaker training job as below and kick off a training job.
We now kick off the SageMaker training job that we just configured with a fit command.
Once the training completes, we deploy the model to a real-time SageMaker endpoint, so we can start inferencing. With this deployment, SageMaker spins up server(s) for inference based on the configuration, deploys the model artifact and processes inference payloads. We go on to configure instance type, instance count and serializer library for the SageMaker deployment endpoint as shown below. You can also refer to the recommended instance types for built-in algorithms here.
The model is now ready for inference.
Make a prediction on out-of-distribution data
We will now showcase how WhyLabs can be effective in this scenario by taking an image from a class outside of what the model was trained on and lowering the image resolution. This realistically represents training-serving skew, where the data used to build the model is different from the data that the model tries to infer against in production. We can then use WhyLabs to analyze the inference data and see how it differs from the training data.
Let’s pick an image from a different class outside of what the model was trained and lower the image resolution.
Now, let’s generate a whylogs profile of that image and send it to WhyLabs.
In the WhyLabs UI, we can now see that we have two profiles for this model: one for training and one for inference:

We can see that our new profile has the same features as the old one:

And compare the two:

Looking at the ImagePixelWidth feature specifically, we can observe that the width of the images in first profile is significantly higher than in the second profile, indicating that our inference data is lower in resolution.

In this exercise, we’ve used a very simple example, and we knew that there would be some disparity (training-serving skew) because we set the training and inference data to be different. In the real world, this would be a clear indicator that our model might not perform as well in production as it did during our initial testing in our training sandbox. As an action to such an indication, we might need to take into account that lower image resolution leads to lower model accuracy and potentially retrain our model to help mitigate that.
Conclusion
Following the steps above, we trained a computer vision model in SageMaker and monitored the input image data with WhyLabs. We intentionally created synthetic data for production that didn’t match the data being used for training the model, so that we could highlight WhyLabs’ ability to identify training-serving skew. In the real world, data scientists don’t intentionally make their production data mismatch their training data. However, data in the real world tend to be messier and more prone to produce errors than those used by data scientists during the training and validation phase.
Training-service skew is one of a number of different examples of problems that can cause model performance degradation in production environments, but through this example, we saw how WhyLabs can help reduce this risk in image data. For those working with other formats, text support is available now, and video and speech data support will be coming soon.
To get support for the open source whylogs library, the self-serve AI Observatory, or for any ML monitoring questions, join the WhyLabs Community Slack.
 |
Danny D. Leybzon is an MLOps Architect at WhyLabs. Danny evangelizes machine learning best practices and has helped countless customers bring their ML models out of the sandbox and into production. When Danny isn’t thinking, talking, or writing about MLOps, he’s hiking, skiing, or scuba diving. |
 |
Ganapathi Krishnamoorthi is a Senior Solutions Architect at AWS. Ganapathi provides prescriptive guidance to enterprise customers helping them to design and deploy cloud applications at scale. He is passionate about machine learning and is focused on helping customers leverage AI/ML for their business outcomes. When not at work, he enjoys exploring outdoors and listening to music. |