AWS Storage Blog
Caching data using Amazon FSx for NetApp ONTAP
Accessing network attached storage (NAS) over long distances can introduce latency that can potentially impact business processes, slow down engineering jobs, and increase costs. Often only a small percent of the dataset needs to be accessed at any given time, allowing caching data locally to solve these challenges without replicating the full dataset. This is especially useful when compute resources are deployed in multiple locations including on-premises and in the cloud (for example, cloud-bursting), in multiple AWS Availability Zones (AZs) to gain access to additional compute resources, or across multiple Regions.
Amazon FSx for NetApp ONTAP offers customers the full power and performance of ONTAP’s data access and enterprise data management capabilities. This includes FlexCache volumes, an ONTAP volume in one location, caching data from a remote ONTAP volume (that is, origin volume), reducing latency for local reads. The origin volume can be in another FSx for ONTAP file system, a NetApp Cloud Volumes ONTAP (CVO) instance, or even a physical NetApp system running on premises. While reads will be cached locally in the FlexCache volume, writes are sent “through” the cache to the origin volume, preserving a single source of truth for your data. This prevents inconsistencies where one engineer may change a project file, and another engineer in another location will read an older version of the same file.
NetApp is used by multiple industries globally such as software development, media and entertainment, and semiconductors. These industry workloads can benefit from the simplicity of a fully managed ONTAP service with all the enterprise features they rely on today. With your data in AWS, engineers can scale to tens of thousands of compute cores in minutes, build out AI/ML pipelines, or integrate with other AWS services like analytics.
In this post, we explore several patterns for leveraging FSx for ONTAP FlexCache to increase shared file system performance and reduce data transfer costs. All of the following configurations require network communication between FSx for ONTAP and the source ONTAP system. See the FSx for ONTAP getting started guide for details on how to set up peering.
Caching unknown working datasets
Existing on-premises NetApp file systems often share data from multiple projects, creating challenges when one project must burst or move entirely to the cloud. Customers are faced with a dilemma: should they break up the file system to minimize data migration, at the expense of business disruption, or migrate a lot more data than necessary. By caching the data with FlexCache, only data blocks that are used in AWS will be copied into the cache and the cache will get populated over time (lazy loading). This results in faster bursting to AWS and reduced bandwidth and costs.

Figure1: FlexCache only caches the blocks within files that users read locally
Cloud bursting
A simple use case for FlexCache volumes is to burst to the cloud, providing low-latency data access to Amazon EC2 instances while the data’s single source-of-truth remains on premises.

Figure 2: Caching data from an on-premises NetApp system
Scaling-out instead of scaling-up
As applications grow and need additional read capacity, you can choose to leverage FlexCache, spreading the clients between different Amazon FSx for NetApp ONTAP file systems to increase performance beyond the capability of a single file system instead of scaling up your storage. When new clients are added, they can be mounted to a new FlexCache volume that will provide additional performance to the source volume.

Figure 3: Achieving higher read performance with multiple FSx for ONTAP file systems
Scaling beyond a single Availability Zone
Many workloads can benefit from scaling beyond a single AWS Availability Zone, such as high performance computing (HPC), workloads requiring large numbers of a specific instance type (for example, GPU powered ones), or workloads relying on large Spot Fleets that will have a higher number of available instances. Many of these workloads require fast access to a shared storage, and additional latency may result in slower data processing or extend the use of expensive software licenses. This can also enable scaling beyond the maximum throughput of a single Amazon FSx for NetApp ONTAP file system.
These workloads can benefit from FSx for ONTAP in one Availability Zone, and one (or more) FlexCache volumes in other Availability Zones in the same AWS Region. Low latency between AZs fetches data from the origin cache quickly, and writes though the cache experience—with only a small increase in latency.

Figure 4: FSx for ONTAP in two AZs, caching data for local access within each AZ
Enabling collaboration at global scale
Some companies have globally distributed development teams collaborating on projects. For example, semiconductor companies developing the same Integrated Circuit (IC) in multiple countries need fast access to NAS locally in each Region. Historically this would be done using replications of the entire dataset that would provide read-only access to the data and require additional administrative overhead to manage. These replications were also asynchronous, resulting in some sites using older file version for longer periods of time.
Amazon FSx for NetApp ONTAP can be used to allow engineers to work in multiple AWS Regions on the same IC design files using a local cache and a single source of truth located in the Region of their choice. An engineer accessing a recently changed file will always get the latest version without any need for manual processes or waiting for the next replication cycle.
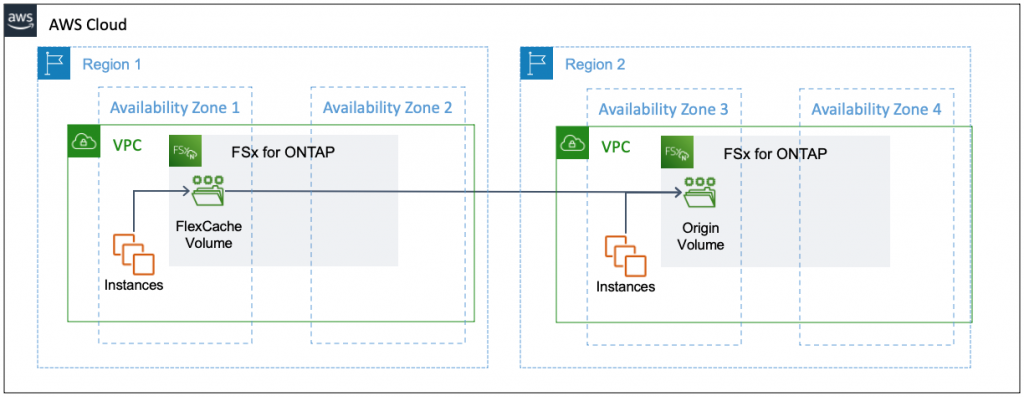
Figure 5: FSx for ONTAP in one Region caching data from a remote Region
Increasing cache hit ratio by grouping similar clients
To minimize latency, the goal when designing a caching solution is to increase cache hit ratio. This is achieved when clients mounting the same FSx for ONTAP FlexCache volume are working on similar datasets, which will minimize data fetching requests from the origin volume. For example, in an HPC cluster, mounting all the clients processing the same dataset to the same FlexCache volume will result in better performance compared to mounting clients randomly.

Figure 6: Grouping similar clients on different FlexCache volumes to increase cache hit ratio
Accelerating output access with bidirectional caching
A common bursting scenario involves running a job at scale on AWS with the source data either on AWS or still residing on-premises, generating output or detailed log files as the job runs, and then consuming these files from various locations.
FlexCache can be set up bidirectionally to accelerate access to outputs of cloud bursting jobs. In a bidirectional setup, input files reside on premises and are cached in the cloud, while output files reside in the cloud and are cached on premises.

Figure 7: Bidirectional caching input files cached in AWS and output files cached on premises
Measuring and monitoring
A successful FlexCache implementation requires planning and monitoring. A few best practices include:
Network: Cache misses require getting blocks of data from the origin volume, and writes get acknowledged by the origin. Both operations are bound by the available bandwidth and are slowed down when the link adds substantial latency. Measure the available bandwidth, and estimate the size of the data that needs to be accessed (working set size), to estimate the cache warm-up (hydration) time. You can decide to hydrate the cache in advance of launching new instances if the bandwidth is limited.
Scalability: File systems tend to grow over time in capacity and performance. Since the FlexCache volume can be smaller than the origin volume, it’s important to identify when the FlexCache volume size must be increased. This is best measured by monitoring the cache hit ratio of the FlexCache volume, and potentially experimenting with different sizes over time to see how your specific workload responds to different sizes of caches. When the cache hit ratio starts dropping, try increasing the size of your cache.
Monitoring: For both the network and scalability to work over time, monitoring is required. Monitoring should include at least three main areas:
- Cache hit ratio for FlexCache, which you can monitor using the Harvest open-source tool and feed into Grafana.
- The network connection between the FlexCache volume and the origin volume – monitor for packet loss and available bandwidth as both may lead to higher latency for writes and for origin fetches. This is achieved through standard network monitoring tools.
- Origin volume response time –any bottleneck in the origin volume will increase latency of origin fetches as well as write-around the FlexCache volumes back to the origin. This too can be monitored using Harvest.
Conclusion
Amazon FSx for NetApp ONTAP allows you to accelerate access to NAS file systems remotely without the need to replicate entire datasets, but requires planning to meet the needs of your specific use case. Choosing the right deployment pattern (for example, caching within the same Availability Zone, across Availability Zone, or across Regions) can allow you access to the right amount of required resources, while leveraging bidirectional caching can accelerate on-premises access to data generated in the cloud and further improve your results. This all can all be achieved without replicating the full dataset to the cloud, reducing time, bandwidth, and capacity.
Thanks for reading this blog post on caching best practices using FSx for ONTAP. If you have any comments or questions, don’t hesitate to leave them in the comments section.