AWS Storage Blog
Cloud-based disaster recovery: Simple protection for every budget
Data is an organization’s lifeblood—and more vulnerable than ever to breach, attacks, and disastrous loss. Yet too many companies aren’t acting as quickly or effectively on their disaster recovery (DR) strategy as they should, due to constraints in funding, staffing, and resources, amongst other things. At ePlus, we help organizations navigate their technology options – and then design, orchestrate, and seamlessly implement solutions in areas of need, like effective DR.
Recently, our ePlus team of AWS experts showed our customers that it’s possible to stand up cloud DR quickly with a limited upfront financial investment if you have the right planning, methodology, and technology. Think going from no DR to fully functional DR within a week. In our customer webinar (you can view the recording here), we presented a fictional use case and our five-step process:
- Planning
- Proof of concept
- Automated deployment
- Testing
- Go-live
We walked through AWS services CloudEndure Disaster Recovery (CloudEndure DR) and AWS Control Tower. The last step was our demo: setting up replication of Linux servers to AWS and conducting a failover test of our fictional customer’s DR plan. Now that you have seen the power and simplicity of the technology, it is time to turn it into reality. In this blog, I discuss the importance of a strong disaster recovery plan, a path to develop confidence in that plan, and the proven ePlus framework for accelerated success.
An urgent need to escalate DR
Data has become “the world’s most valuable resource,” an Economist magazine cover declared in 2017, and this statement has become even more true in the years since. Companies use data to make predictions, discover trends, better understand their customers, and bring new products to market faster, cheaper, and more effectively.
Unfortunately, organizations rarely protect this precious data to the extent they should, nor do they prioritize DR. Furthermore, much of the DR focus has been on replication rather than actual recovery. You can replicate your data with low RPOs and RTOs to a different facility on a different power grid, but if you don’t have your network and security posture built out—and a plan for your users to access the data—you’re going to face a rude awakening when you go into failover mode.
Many factors contribute to recovery failure: financial and staffing restraints, improper SLA alignment, a lack of regular testing and automation, prioritization of replication over recovery, and the list goes on. This is a disaster waiting to happen.
Due to COVID-19, we’ve all been thinking differently about disasters—how vulnerable we are and how important it is to be ready for anything. According to Gartner’s Business Continuity Survey
- 12% of more than 1,500 respondents believe that their businesses were highly prepared for the impact of coronavirus
- 2% of respondents believe that their business can continue as normal
- 57% of respondents expect business to continue at a reduced pace, 16% expect to be severely restricted, and 1% expect to be discontinued altogether
The most common causes of IT disaster are not natural disasters, but rather human error, hardware and software failures, and malicious activity. We now have new types of DR challenges linked to COVID-19, which introduce a new set of questions and concerns. What if I don’t have physical access my facility? What if all my employees have to shift to remote work overnight?
As a longtime AWS Partner, ePlus has seen the industry respond to help companies meet these extraordinary challenges. A perfect example are special offers from ePlus and AWS related to accelerating the adoption of DR via tools such as CloudEndure DR.
We realized, now is the time to bring DR to the forefront—to take advantage of this critical moment to help our customers rethink traditional approaches and give the DR piece of the puzzle the attention it deserves.
“Cloud DR in one week” (starting with this one-hour webinar)
For years, ePlus has worked with our customers to create data protection strategies to support business continuity and DR initiatives. We have seen what works well, and what hasn’t worked so well, when it comes time to perform an actual failover. This puts us in a great position to “demystify DR.”
For example, we now know that with proper planning and a methodology, backed by a highly automated regimen, organizations can rapidly deploy, test, and go live with DR in AWS. What’s more, we understand how such an approach can lay the foundation for future modernization and accelerated cloud adoption.
This is knowledge we had to share with our customers.
To spread the word, the ePlus Cloud team swiftly scheduled a webinar, “How to Stand Up Cloud DR in One Week.” We limited our agenda to an hour, featuring a use case, key product tutorials, and a demo with an actual failover with time for Q&A at the end.
The webinar attendees included an even mix between frontlines tech experts and IT managers and directors.
A fictional use case—and our five-day framework
We created a fictional healthcare organization looking to move 650 virtual machines (VM) from an on-premises colocation setup to a secondary site, with a new AWS footprint for VMs, virtual desktop infrastructure, and other future growth.
We then posed the question: Could the organization have all workloads replicated and the initial app tested in AWS in only five days?
Though we couldn’t offer a minute-by-minute duplication of the entire experience in a one-hour webinar, we walked through the cornerstones that make such efficiency possible, including:
- Our agile methodology, featuring sprint-based services and dedicated teams working hand in hand to drive DR outcomes
- A security framework hardened by AWS native and third-party integrations and augmented by CloudEndure DR’s streamlined approach (To illustrate, the process only leverages one port, TCP1500.)
- Experience with the AWS ecosystem, from the foundational architecture to the suites of relevant products and tools
Putting the pieces together
We walked our participants through AWS Control Tower, which delivers proven architectures ready to go, both for building new environments and for incorporating existing ones into a standardized baseline, complete with governance guardrails and other security features. This default baseline removes a lot of the hard work from the DR process.
“What about Enterprise Landing Zone?” one attendee asked. Our reply: You can think of Control Tower as the next generation of ELZ, only with less configuration and complexity.

While you’ll still need outside expertise and resources for connectivity, AWS Control Tower offers some efficiencies, such as reusable reference architecture for best practices.
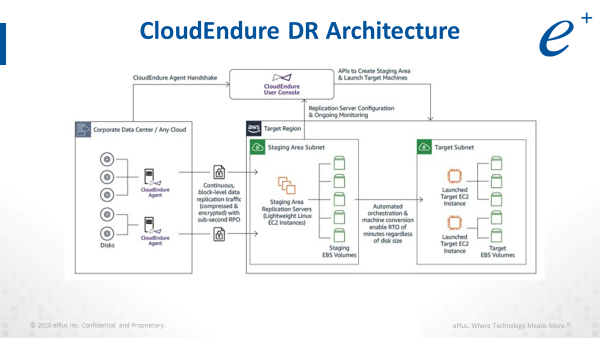
CloudEndure DR: The flexible, reliable DR “go-to”
Unsurprisingly, we spent a fair amount of time on CloudEndure DR, the “go-to” these days for any sort of lift-and-shift migration, DR to AWS and beyond.
CloudEndure DR simplifies the DR experience. It’s agent-based and extremely flexible. “Does it support physical machines or just virtual machines?” one attendee asked. Both and more, with failback to both cloud and on-premises environments; a wide range of OS, application, and database support; and a SaaS-based management plan that lets you use what you need and pay as you go.
CloudEndure DR is reliable, with robust, predictable, non-disruptive continuous replication, over IPsec, VPN, or straight internet with throttling capabilities. For recovery, you get about 60 different recovery points per VM over a 30-day period, which means users can leverage it to recover from ransomware incidents as well.
Finally, CloudEndure DR is efficient. A preconfigured service account gives CloudEndure DR all of those permissions necessary to stand up its launch components. Data lands in the staging subnet, and these replication servers are the only running compute in the solution unless there’s either a failover type of event or failover test. This keeps cost down by allowing you to only pay for the DR servers when you use them. And when it’s time for a failover event or test, that’s when all the orchestration and automation capabilities really kick in.
Acceleration through automation
DR efforts don’t have to be difficult, and CloudEndure DR is proof. It’s highly automated, with easy DR tests and a lightweight staging area that reduces total cost of ownership.
In addition to automated failover and failback, several automated features allowed us to significantly trim down our engagement time, including:
- Installing the agents
- Automatic scaling of the converter servers
- Enforcing tags
- Creating blueprints
A detailed look beneath the hood
Our webinar included a quick demo of the CloudEndure DR portal, the brains of the operation, and we installed the CloudEndure DR agent to give customers a quick glimpse of how all the components look on the AWS side. We also walked through the recovery plan that dictates which servers come up in which order, how you link the service with your target environment on the AWS side, and the sizes you want for your application servers.
For this demo, we replicated two machines from an on-premises environment—a single app with a web layer and a database layer completely up-to-date and tested, with no lag.
We replicated data over the internet, but the AWS approach also supports private connectivity. Test failovers can either be per machine or per recovery plan. The latter is the most common, because most of your workloads will require a full application stack.
Finally, we gathered our guests around the AWS Management Console to watch the launch, from conversion of the on-premises data to the spinning out of the VMs. One, two, three—we watched our VMs go live, then the database server.
Even with a fictional company, that’s exciting to witness.
Also exciting: the possibilities beyond DR. For our fictional healthcare customer, we laid down all the connectivity and network services for an SD-WAN transformation. Not only can organizations reuse AWS network “plumbing,” they have the groundwork for deploying future AWS services, with reference architecture that’s perfect for “lifting, shifting, and modernizing,” as we like to call it.
Conclusion
With AWS tools like CloudEndure DR and AWS Control Tower, backed by an agile approach and the right expertise, DR is far less daunting than it appears. You can stand up a recovery solution quickly—one that’s budget-friendly, as you’re eliminating costs like hardware and other equipment for on-premises data centers, and one that lays the groundwork for future innovation, from connectivity to VDI to ransomware protection and beyond.
What now? Our advice is to:
- Learn more about CloudEndure Disaster Recovery and AWS Control Tower.
- Work with ePlus to create your DR plan.
- Explore other AWS POC funding programs designed to fortify your DR efforts.
Email cloud@eplus.com to take advantage of the CloudEndure DR licensing offer or to learn more about the AWS POC funding programs. Our team is also available to answer any questions you may have about accelerating your cloud DR initiatives.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.