AWS News Blog
New – Amazon FSx for Lustre

|
A pebibyte (PiB – 1,125,899,906,842,624 bytes) is an impressive amount of data, slightly less than half of the estimated memory capacity of a human brain. Data lakes, High-Performance Computing (HPC), and Electronic Design Automation (EDA) applications traditionally work at this scale, as do more recent data-intensive applications such as Machine Learning and media processing.
Amazon FSx for Lustre
Today we are launching Amazon FSx for Lustre, designed to meet the needs of these applications and others that you will undoubtedly dream up. Based on the mature and popular Lustre open source project, FSx for Lustre is a highly parallel file system that supports sub-millisecond access to petabyte-scale file systems. Thousands of simultaneous clients (EC2 instances and on-premises servers) can drive millions of IOPS (Input/Output Operations per Second) and transfer hundreds of gibibytes of data per second.
You can create a file system in minutes, mount it on any number of clients, and start accessing it right away. This is a fully managed service so there’s nothing to maintain and nothing to administer. You can build standalone file systems for ephemeral use, or you can seamlessly join them to an S3 bucket and then access the contents of the bucket as if it were a Lustre file system. Each file system is backed by NVMe SSD storage, provisioned in increments of 3.6 TiB, and designed to deliver 200 Mbps of aggregate throughput at 10,000 IOPS for every 1 TiB of provisioned capacity.
Creating a Lustre File System
You can create a Lustre file system from the AWS Management Console, CLI, or by calling the CreateFileSystem function. I’ll use the CLI today; I simply specify the subnets for the Lustre endpoints and the desired storage capacity:
This takes about 5 minutes and then it becomes AVAILABLE:
My EC2 instance already has the Lustre kernel modules and the Lustre client installed:
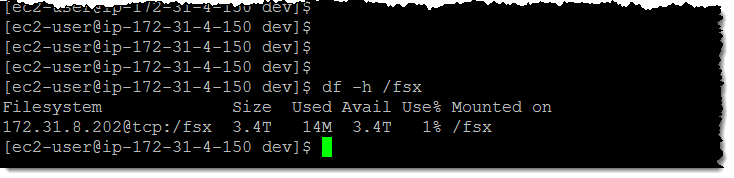
I create a mount point and mount my Lustre file system:
And my 3.4 TiB Lustre file system is ready to use:
I can also create a file system that sits in front of an S3 bucket (or a prefixed section of an S3 bucket). This allows me to treat my bucket as a data lake, and to process it using tools and applications that are file-based. I simply include the bucket name as the ImportPath when I create the file system:
My bucket has about 1 million files inside, so the creation process takes about 30 minutes (the team told me that this takes about 500 files per second). Here is my bucket:
And here is what it looks like from my EC2 instance:
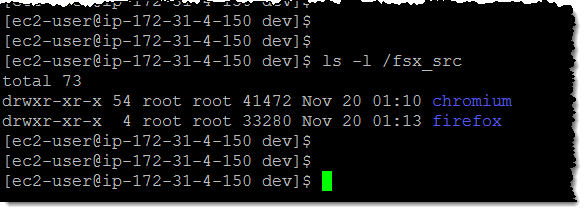
At this point, the Lustre file system contains all of the metadata (names, dates, sizes, and so forth) for my objects but it does not have the actual file data. This data is copied from S3 on an as-needed basis. As a result, this command will not access S3:
And this one will, with a small latency penalty for each access because objects are copied from S3 to the file system on an as-needed basis:
If I understand my code’s access pattern, I can use the hsm_restore option of the lfs command to pre-load them. Perhaps I plan to analyze all of the C header files:
Any changes that I make to the files remain within the file system. I can export changed files back to S3 using the hsm_archive option of the lfs command:
The first command initiates the export operation and the second one indicates that it is complete by printing NOOP. The changed files are written to the same bucket, prefixed by the ExportPath of the file system:
I can discover the ExportPath from the command line:
Each file system publishes a rich set of metrics to CloudWatch:
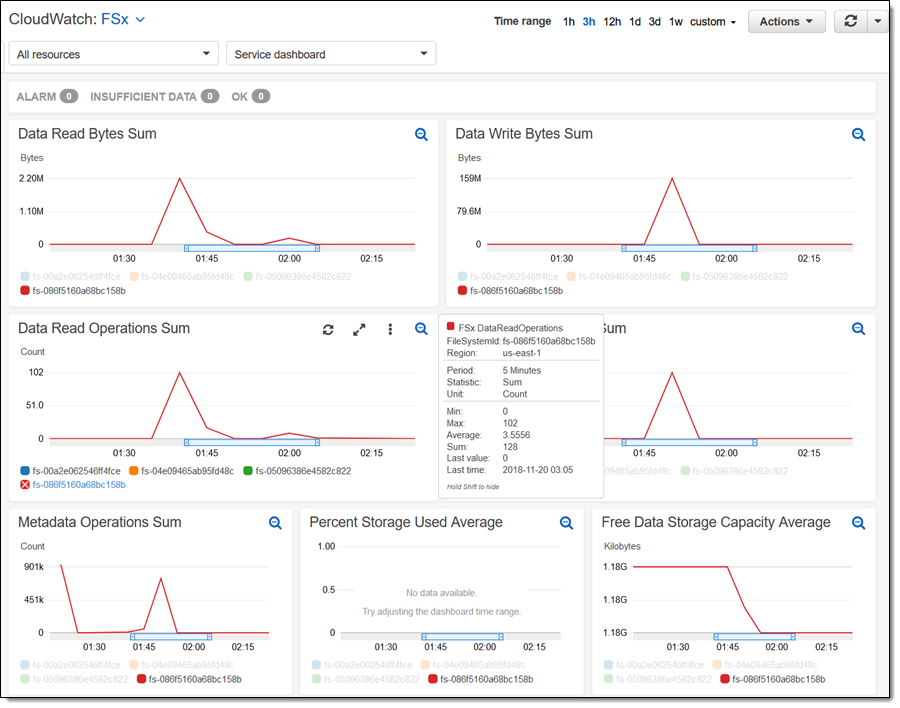
There’s a lot more, but I’m just about out of space! For example, I didn’t show you the scale that you can achieve using Amazon FSx for Lustre. I used one client, but could just have easily used thousands.
Things to Know
Here are a couple of interesting things to keep in mind regarding Amazon FSx for Lustre:
Console Access – I wrote this post using the CLI; a full console is also available.
Regions – You can create Lustre file systems in the US East (N. Virginia), US West (Oregon), US East (Ohio), and Europe (Ireland) Regions.
Pricing – Pricing is based on the amount of storage that you have provisioned, and starts at $0.14 per GiB per month in the US East (N. Virginia), US West (Oregon), and Europe (Ireland) Regions.
Access – You can access your file systems from EC2 instances. You can also use AWS Direct Connect to connect your existing data center or colo to AWS, and access your file systems from there.
Security – Access to each file system goes through a security group, with IAM policies for fine-grained access control. Data at rest is encrypted using a 256-bit block cypher and keys managed by Amazon FSx for Lustre.
Available Now
Amazon FSx for Lustre is available now and you can start using it today!
— Jeff;