AWS Compute Blog
Amazon ECS Task Placement
![]()
Topics
Intro
Attributes, task groups, and expressions
Task placement constraints
Task placement strategies
Use cases
Intro
Amazon Elastic Container Service (ECS) is a highly scalable, high-performance container orchestration service that allows you to easily run and scale containerized applications on AWS. This post covers how Amazon Elastic Container Service (Amazon ECS) runs containers in a cluster with the EC2 launch type. Topics include why AWS built the task placement engine, the different strategies and constraints available to decide where and how containers are run, and things to consider when picking placement strategies.
If you are not familiar with the relationship between ECS and Amazon EC2 or its components, see the Building Blocks of Amazon ECS post.
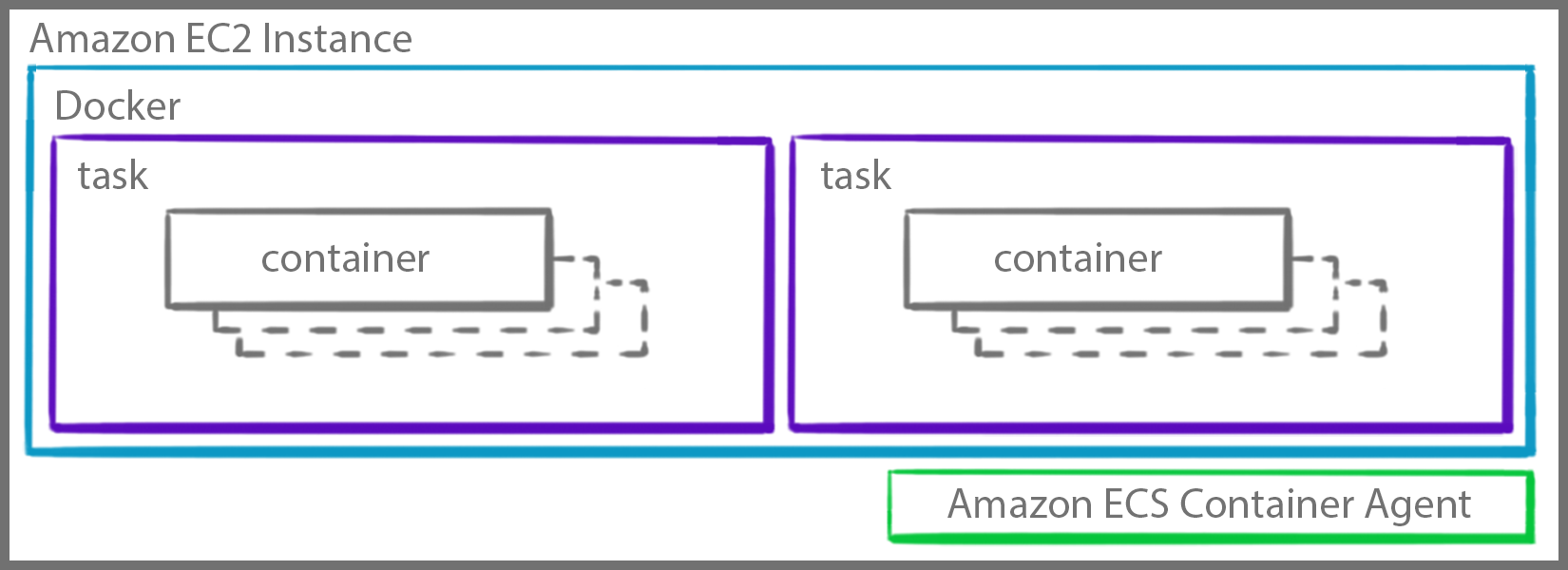
When a task is launched in a cluster, a decision has to be made to choose which container instance should run that task. Conversely, when scaling down a service, a decision has to be made to choose the specific task to be terminated.
Task placement
By default, ECS uses the following placement strategies:
- When you run tasks with the RunTask API action, tasks are placed randomly in a cluster.
- When you launch and terminate tasks with the CreateService API action, the service scheduler spreads the tasks across the Availability Zones (and the instances within the zones) in a cluster.
Before December 2016, tasks could only be placed by their default placement strategies. This meant making the decision yourself, such as writing your own scheduler, and calling the StartTask API action to achieve custom task placement. When you manually constrained the placement of your grouping of containers, you could only place based on CPU, memory, and ports. Additionally, while creating your own scheduler can be powerful, there’s a tradeoff with complexity.
AWS built the task placement engine, which removes the need for you to build, run, and manage your own scheduling and placement services. There are several new features that provide you with more control over how applications run across clusters through custom attributes.
You can think of this flow as a funnel with filters for your instances. Constraints must be obeyed. If an instance doesn’t fit, it isn’t used. Strategies are then used to sort the rest of the instances by preference to determine which are the “best.”
For every instantiation of your task, it runs through every step. Calling run-task with a count of n is effectively calling run-task n times (create-service also works the same way).

Example
Here’s how to use these placement features. In this example, you use the AWS CLI run-task command. For the last couple of filters, I show how to use them with placement flags, but you can just as easily include them in your task definition file instead. This can all be done in the console as well. Start with the cluster shown earlier:
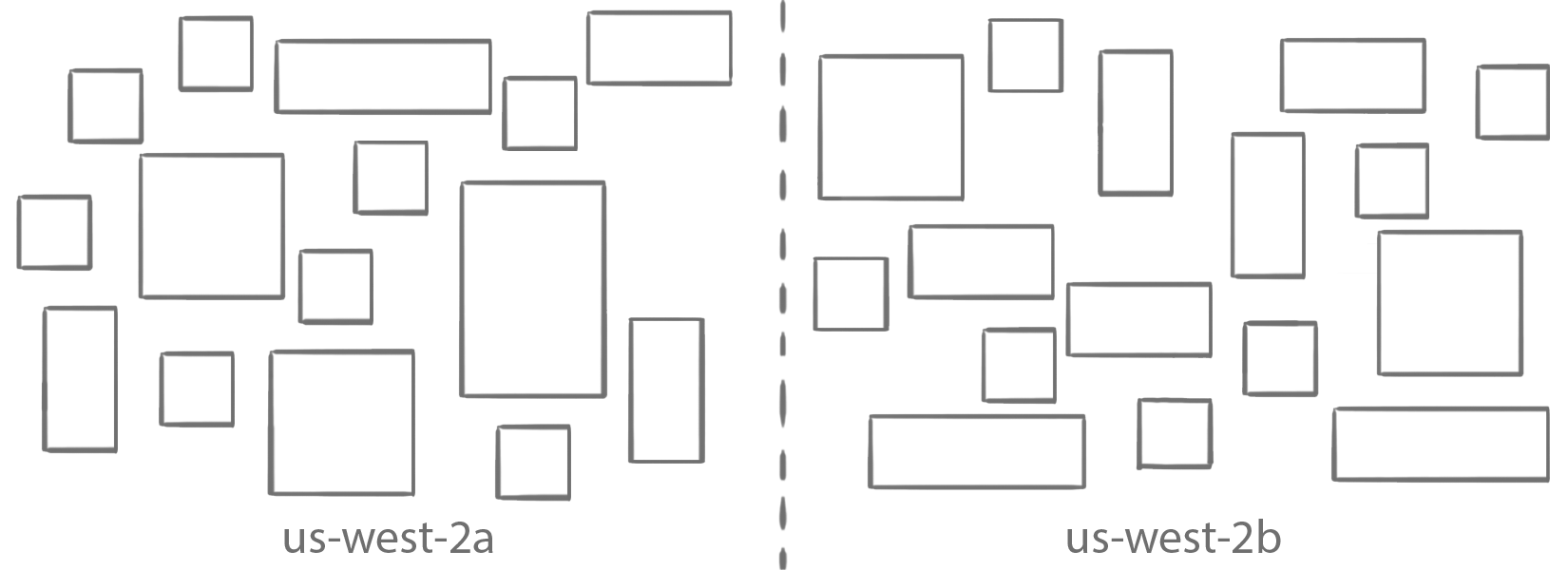
Cluster constraints
In the first step, eliminate all the instances that don’t have the required resources based on what you defined either in the JSON task definition or what you provided overrides for to RunTask.
Not enough CPU? Not enough memory? A port is needed, but it is already in use on that instance? Then the instance is eliminated from the set of valid candidates.

Placement constraints
In the second step, keep only the instances that satisfy the attribute or task group constraints. Yes, this means that you can indicate what instance to use for a task (for example, to make sure that CPU-intensive jobs are scheduled on the right type of instance, or in which Availability Zone).
You can also create any custom tags of your choosing. The green tasks on the green instances, the blue tasks on the blue instances! You can also use the Cluster Query Language to write expressions to check for multiple attributes. In the next section, I cover how to write and use the attributes and expressions.
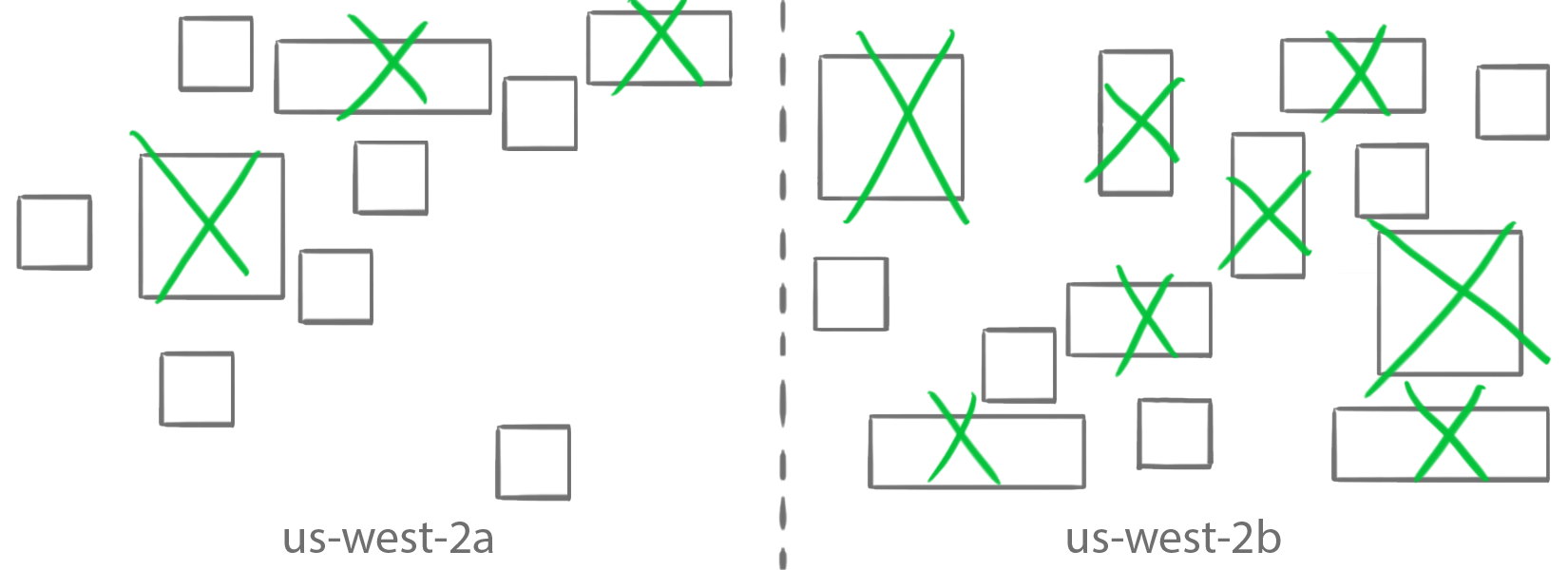
Placement strategies
In the third step, filter on the following supported task placement strategies:
randombinpackspread
By default, tasks are randomly placed with RunTask or spread across Availability Zones with CreateService. Spread is typically used to achieve high availability by making sure that multiple copies of a task are scheduled across multiple instances based on attributes such as Availability Zones.
Conversely, binpack places tasks together to be as cost-efficient as possible. Later in this post, you’ll see how these placement strategies work, as well as how to chain them together and why you may want to do so.

Task copies
This isn’t part of the filter, but instead, the count flag is used to indicate how many copies (n) of a given task to run. Effectively, it tells ECS to re-run this workflow n times. By default, the count is set to 1, so run-task is executed one time. For services, the desired-count flag is used.
Attributes, task groups, and expressions
For task placement, you can use instance fields, such as attributes, as well as task groups. These can be used in expressions for task placement constraints, or instance fields can be used standalone for task placement strategies. Here’s a quick overview of attributes, task groups, and expressions before you go any further.
Instance: Fields
Because you are using these fields with respect to instances in task placement, the instance: preface is optional and can be used either of the following ways with a field name or an attribute.
Field names
The currently supported field names are as follows:
Attributes
There are also instance attributes, which are prefaced with attribute. Again, instance: is optional:
Built-in attributes
The following are some of the provided attributes:
Custom attributes
Well, what if you don’t see an attribute that you want? This is where custom attributes come in handy! Want to differentiate between test and prod? What about blue versus green?
Task groups
In addition to placing tasks based on attributes, you can use task groups. Every task is assigned a group ID that you can reference in placement. For both tasks and services, a default ID is given, or you can choose your own. Perhaps you want to run version 2 of a service but only on instances with version 1.
Expressions
Alright, so you have some attributes and task groups… now what? Well, AWS created the Cluster Query Language to make it easy to create expressions for task placement constraints. These attributes and task groups are used with the available comparison operators, which may look familiar if you’ve used Boolean operators before. Some of these operators can be written in multiple ways, such as “!” or “not”.
For instance, to create an expression using a single attribute to select only t2.micro instances, use the ecs.instance-type attribute and the string equality comparator as follows:
For t2.micro and t2.nano instances, you have a few options. You could use the same syntax as earlier with the or comparator:
Another way is to use the in comparator with an argument list:
To include all t2 instances, use a wildcard and the pattern match operator instead of listing out each one:
Task group comparisons work the same way. The following snippet selects any instance upon which the task group “database” is running:
To select only task groups that are not “database,” combine expressions:
You can use these expressions to filter your instances:
These expressions and attributes, respectively, are also used for task placement constraints and strategies, which I cover in the next few sections.
Constraints
Now look at placement constraints. When determining task placement, there may be certain EC2 instances to include or exclude from running containers. For example, you may want to place tasks only on GPU types.
Task placement constraints let you define where your containers should run across your cluster. ECS currently supports two types of placement constraints: distinctInstance and memberOf. By default, ECS spreads tasks across Availability Zones and instances.
Distinct Instance
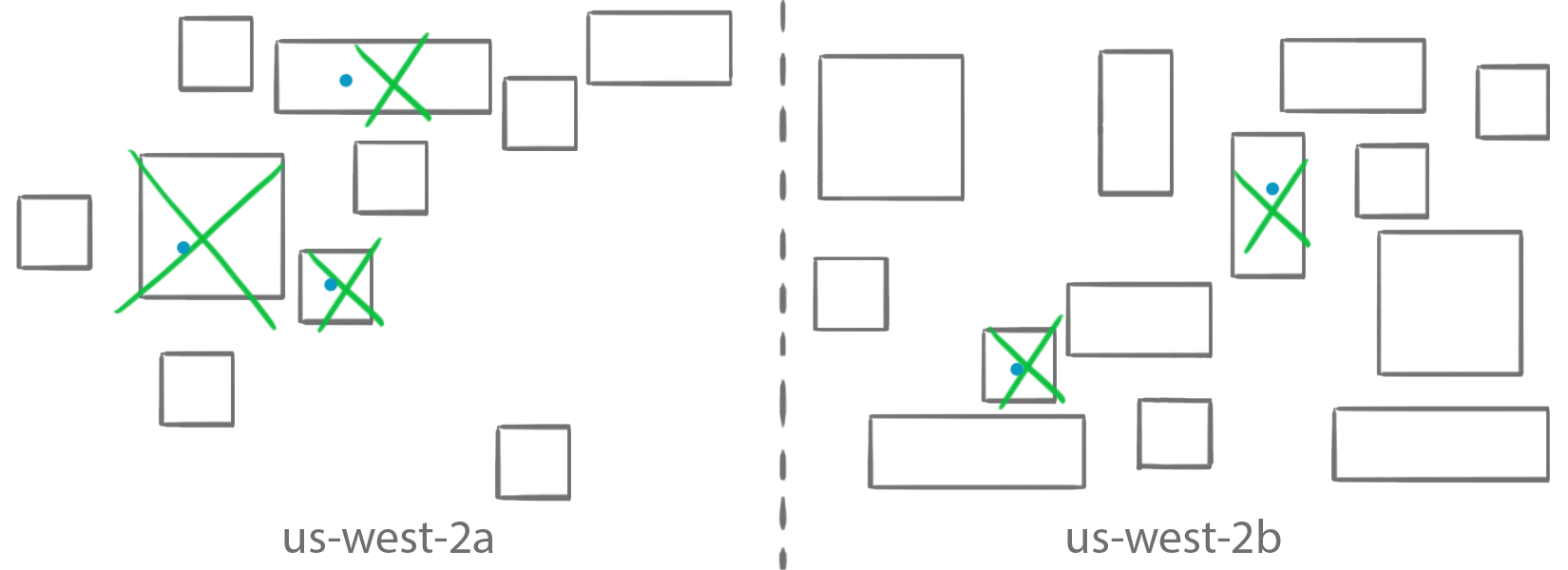 The distinctInstance constraint makes it possible to ensure that every container is started on a unique instance in your cluster. The distinctInstance constraint never places multiple copies of a task on a single instance, even if you request more running tasks than available instances.
The distinctInstance constraint makes it possible to ensure that every container is started on a unique instance in your cluster. The distinctInstance constraint never places multiple copies of a task on a single instance, even if you request more running tasks than available instances.
For example if you decide to place five copies of a task, each time it filters out the instances that are already running the task.
Member of
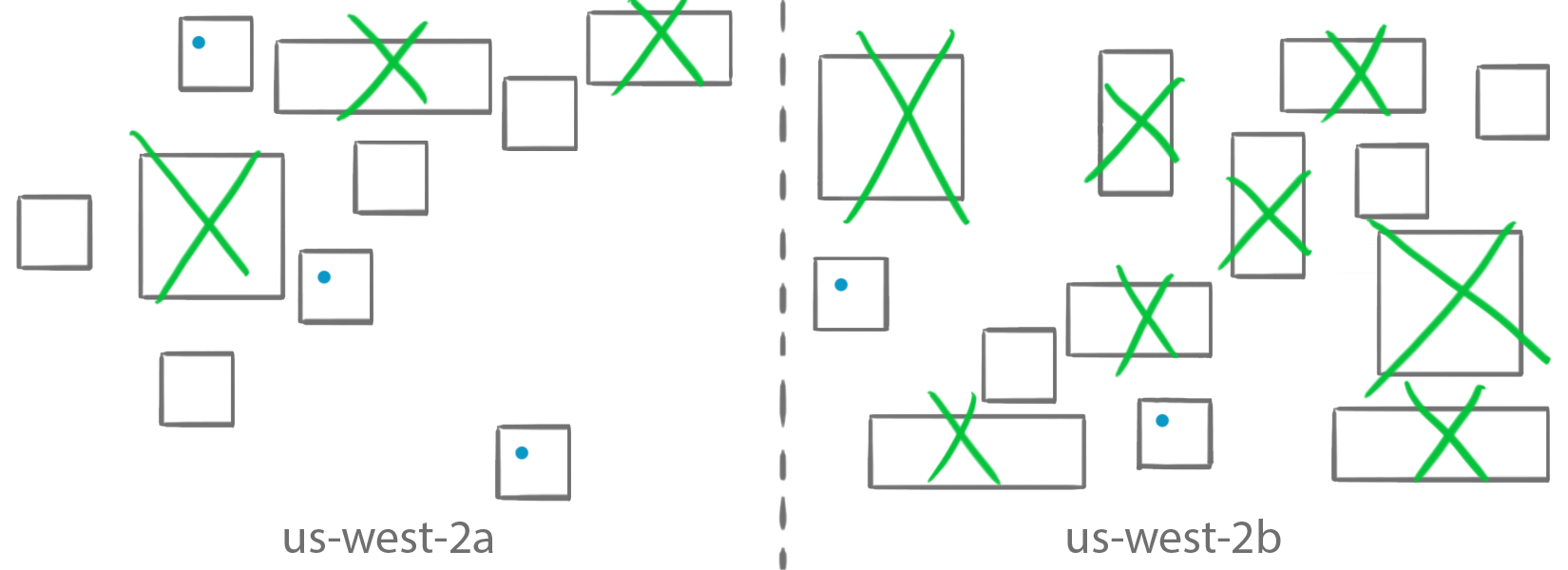 The memberOf constraint describes a set of instances on which your tasks should run. It is for anything you could define as an attribute or task. It also takes in an expression of attributes written in the Cluster Query Language.
The memberOf constraint describes a set of instances on which your tasks should run. It is for anything you could define as an attribute or task. It also takes in an expression of attributes written in the Cluster Query Language.
For example, if you have a small application and just want it to run on t2.micro instances:
You can create expressions using the Cluster Query Language to check for multiple attributes. Here’s how you can weed out all instances in the us-west-2c Availability Zone as well as instances that aren’t of type t2.nano or t2.micro:

You can also use constraints to place all tasks with the same task group on the same instance (affinity):
Or you can ensure that instances never have more than one task in the same group (anti-affinity):
aws ecs run-task –task-definition nouvelleApp –count 5 –group webserver –placement-constraints type=memberOf,expression=”not(task:group == webserver)”
Strategies
Now look at placement strategies. Placement strategies are used to identify an instance that meets a specific strategy. ECS supports three task placement strategies:
randombinpackspread
Random is how RunTask places tasks by default and is fairly straightforward (it doesn’t require further parameters). The two other strategies, binpack and spread, take opposite actions. Binpack places tasks on as few instances as possible, helping to optimize resource utilization, while spread places tasks evenly across your cluster to help maximize availability. By default, ECS uses spread with the ecs.availability-zone attribute to place tasks.
Random

Random places tasks on instances at random. This still honors the other constraints that you specified, implicitly or explicitly. Specifically, it still makes sure that tasks are scheduled on instances with enough resources to run them.
Bin packing

The binpack strategy tries to fit your workloads in as few instances as possible. It gets its name from the bin packing problem where the goal is to fit objects of various sizes in the smallest number of bins. It is well suited to scenarios for minimizing the number of instances in your cluster, perhaps for cost savings, and lends itself well to automatic scaling for elastic workloads, to shut down instances that are not in use.
When you use the binpack strategy, you must also indicate if you are trying to make optimal use of your instances’ CPU or memory. This is done by passing an extra field parameter, which tells the task placement engine which parameter to use to evaluate how “full” your “bins” are. It then chooses the instance with the least available CPU or memory (depending on which you pick). If there are multiple instances with this CPU or memory remaining, it chooses randomly.
Spread
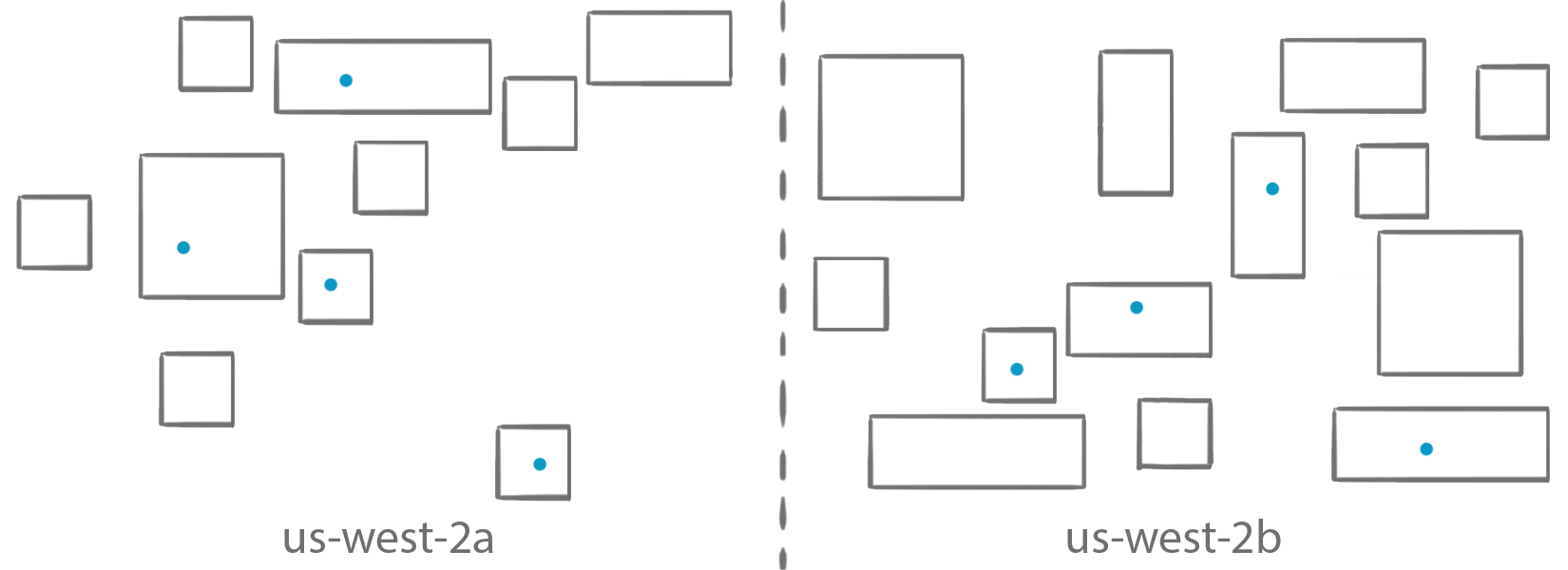
The spread strategy, contrary to the binpack strategy, tries to put your tasks on as many different instances as possible. It is typically used to achieve high availability and mitigate risks, by making sure that you don’t put all your task-eggs in the same instance-baskets. Spread across Availability Zones, therefore, is the default placement strategy used for services.
When using the spread strategy, you must also indicate a field parameter. It is used to indicate the “bins” that you are considering. The accepted values are instanceID to balance tasks across all instances, host, or attribute key:value pairs such as attribute:ecs.availability-zone to balance tasks across zones. There are several AWS attributes that start with the “ecs” prefix, but you can be creative and create your own attributes.
Chaining placement strategies

Now that you’ve seen how to use task placement strategies, you can also chain multiple task placement strategies with their respective attributes together. You can have up to five strategy rules per service. Perhaps you want to spread tasks across Availability Zones and binpack:
Use cases
Here are some use cases for task placement so you can see how they can be solved by combining attributes, expressions, constraints, and strategies.
Task creation
Mariya is fairly new to using containers and especially container orchestrators. She wants to try ECS and has a simple application that she first wants to get running on a single node. (Solution: Use the RunTask API.)
Scaling
After trying this, Mariya wants to scale her application to run 10 containers across any available nodes in her cluster. (Solution: This means she needs to run a task using either random or spread placement strategies.)
Availability
Mariya then realizes that if she wants her tasks to automatically restart themselves if they fail, or if she wants more than 10 instantiations of her task running, she needs to create a service. (Solution: Create a service.)
Christopher wants to achieve high availability by distributing his tasks amongst all the instances in his cluster so he minimizes impact if any one host goes down. (Solution: To do this he uses spread placement over host name.)
Ming-ya wants to run a monitoring container on each instance in her cluster. To help her do this, she creates a service with a high desired count and a distinctInstance placement constraint. The ECS service scheduler ensures that each instance in the cluster runs this task (up to the desired count).
Availability and Task Groups
Alex wants to run a fleet of webservers. For performance reasons, they want each webserver to have local access to a caching process that was written by another team. They define their webserver as one task, the caching server as a second task. When they launch their webserver task they uses a placement constraint so that the tasks are only placed on instances that are already hosting the cache task. (Solution: Use placement constraints with a task group.)
Availability and resource optimization
Jake wants to achieve high availability, but he has a limited budget and needs to optimize all the resources he uses. (Solution: Take a balanced approach of spreading over availability Availability Zones and binpacking on memory within a zone.)
aws ecs run-task --task-definition nouvelleApp \
--count 9 \
--placement-strategy type="spread",field="attribute:ecs.availability-zone" type="binpack",field="memory"Instance type selection
Aditya has a GPU workload that they want to run in containers on ECS. He needs to ensure that only GPU-enabled instances are used for this workload. (Solution: Create a service and spread on instance type = G2* or whatever other GPU-enabled instance types are in the cluster)
Conclusion
You’ve now looked at task placement at a high level, as well as:
- Attributes, task groups, and expressions
- Constraints
- Strategies
- Example use cases
To dive deeper into any of these aspects, check out Task Placement. Also, feel free to ask any questions!