Amazon Web Services ブログ
Category: General

東海旅客鉄道株式会社:超電導リニアの電気設備保守を支える IoT プラットフォームの構築
このブログは、東海旅客鉄道株式会社(以下、JR 東海)中央新幹線推進本部 リニア開発部 藤原 海渡氏と、アマゾ […]

株式会社ラクス: 伝票作成 AI エージェントの構築と、品質を支える評価設計の取り組み
本ブログは株式会社ラクス様と Amazon Web Services Japan 合同会社が共同で執筆しました […]

【ブース展示報告】AWS Summit Japan 2026 不動産ブース 不動産業の未来を、生成 AI で切り拓く
はじめに AWS Summit Japan 2026(6/25-26 @幕張メッセ)にご来場いただいた皆様、あ […]

ITbook 株式会社様のAWS 生成 AI 活用事例:Amazon Bedrock を活用し、要件文書から提案書を自動生成する仕組みを構築し、提案書のドラフト作成を十日から半日に短縮
本ブログは ITbook 株式会社様とAmazon Web Services Japan 合同会社が共同で執筆 […]
完全なライフサイクル制御による分離されたサンドボックスの実行: AWS Lambda が MicroVM を導入
本記事は、2026 年 6 月 22 日に公開された Run isolated sandboxes with […]

【ベータ開始】AWS 認定を最新の状態に保つ新しい方法
AWS 認定の再認定に新たな方法が加わりました。Skill Builder 上のコースとハンズオンラボを完了することで、認定の有効期限を 1 年間延長できます。テストセンターの予約も不要で、自分のペースで取り組めます。現在は AWS Certified Solutions Architect – Associate、AWS Certified Developer – Associate、AWS Certified CloudOps Engineer – Associate、AWS Certified DevOps Engineer – Professional、AWS Certified Solutions Architect – Professional が対象で、今年後半に AWS Certified Data Engineer – Associate、 AWS Certified Security – Specialty、AWS Certified Machine Learning Engineer – Associate を含む追加の認定も対応予定です。

週刊生成AI with AWS – 2026/6/22 週
6 月 22 日週の生成 AI with AWS 界隈のニュースをまとめてお届けします。Amazon Bedrock AgentCore の Web Search 一般提供やマネージドナレッジベース、AWS DevOps/セキュリティエージェントの新機能など、AI エージェントを本番で活用するためのアップデートが充実しました。ユナイテッドアローズの店舗 AI エージェント「SMART」の国内事例や、Kiro の新機能・GovCloud 認証取得まで、今週の注目トピックをぜひご覧ください。
Amazon Quick on Desktop が東京リージョンに対応 – AWS Summit New York 2026 アップデート –
Amazon Quick on Desktop が AWS アジアパシフィック (東京) リージョンで利用可能になりました。本ブログでは、Amazon Quick on Desktop の機能やアップデートについて紹介します。
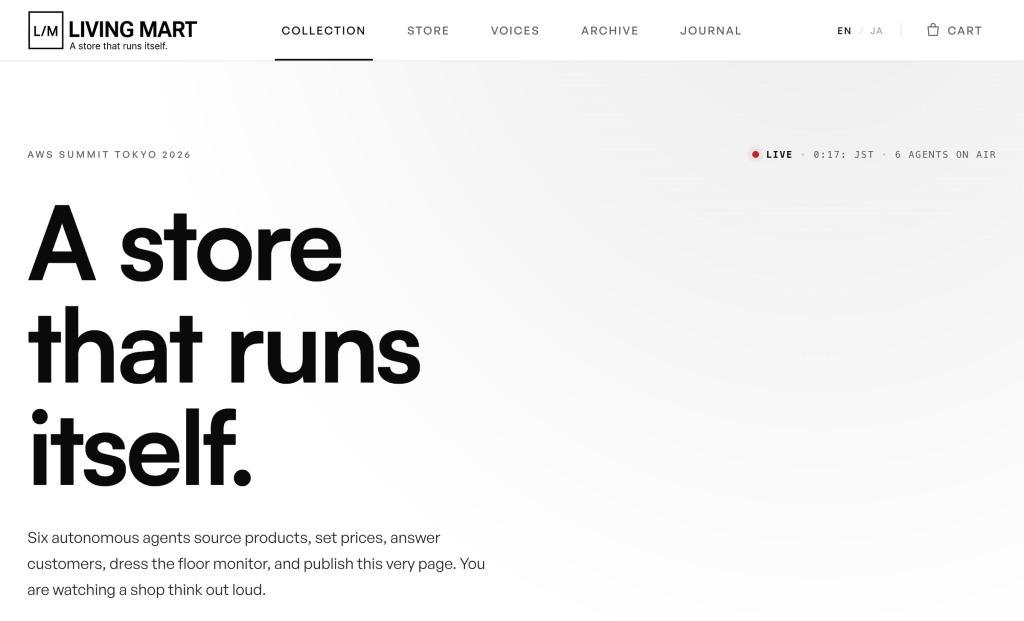
AI が経営するお店で買い物しませんか? — AWS Summit Japan 2026 Builders’ Fair で「Living Mart」体験
6 体の AI エージェントが、仕入れ・値付け・サイト運営・接客・広告までを人間の指示なしに動かすお店。AWS Summit Japan 2026(幕張メッセ/ブース A080)で、AI 運営の EC サイトでのお買い物と、当選者向け AI デザインのオリジナルステッカーを体験できます。
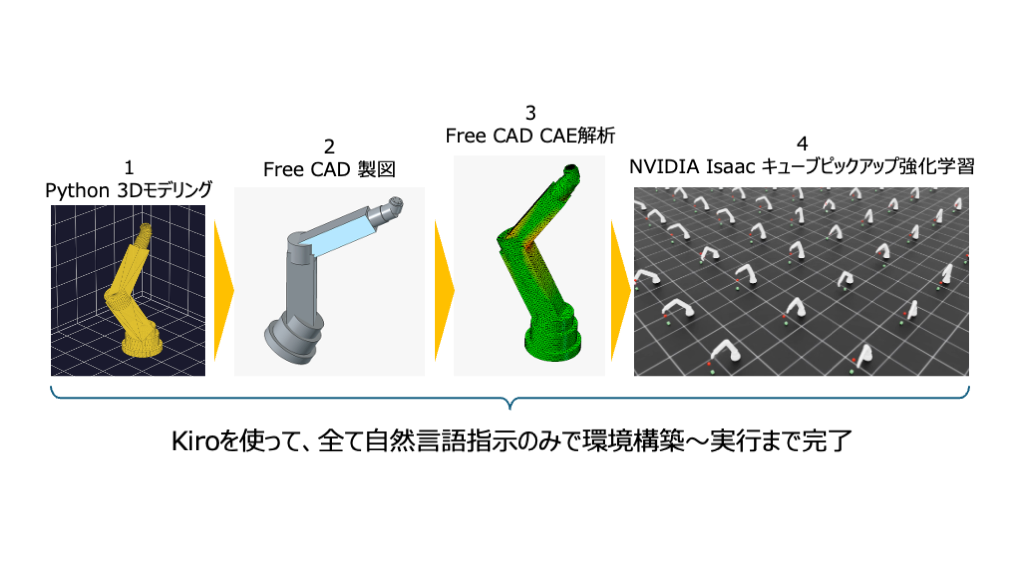
AWS Summit Japan 2026 ブース紹介 — 生成 AI 時代の製品設計開発
みなさんこんにちは。ソリューションアーキテクトの山田です。2026 年 6 月 25 日(木)、26 日(金) […]