Amazon Web Services ブログ

Amazon Bedrock AgentCoreによる、高度なネットワーク運用エージェントの構築
深夜2時、バージニア北部リージョンにてお客様のトランザクション処理が失敗したというアラートが、あなたのスマートフォンに届きました。Amazon Web Services (AWS)上で画像処理プラットフォームを管理するネットワーク運用者のあなたは、複雑なアーキテクチャのトラブルシューティングを迫られます。このネットワークは、複数のAmazon Virtual Private Cloud (Amazon VPC) がAWS Transit Gatewayで相互接続されており、その上で多数のマイクロサービスが実行されています。[…]

勝利を支えるデータ:Catapult と AWS IoT がプロスポーツを変革する方法
プロスポーツの世界では、わずかな差が勝敗を分けることが多いです。世界中のチームが、選手のパフォーマンス最適化、 […]
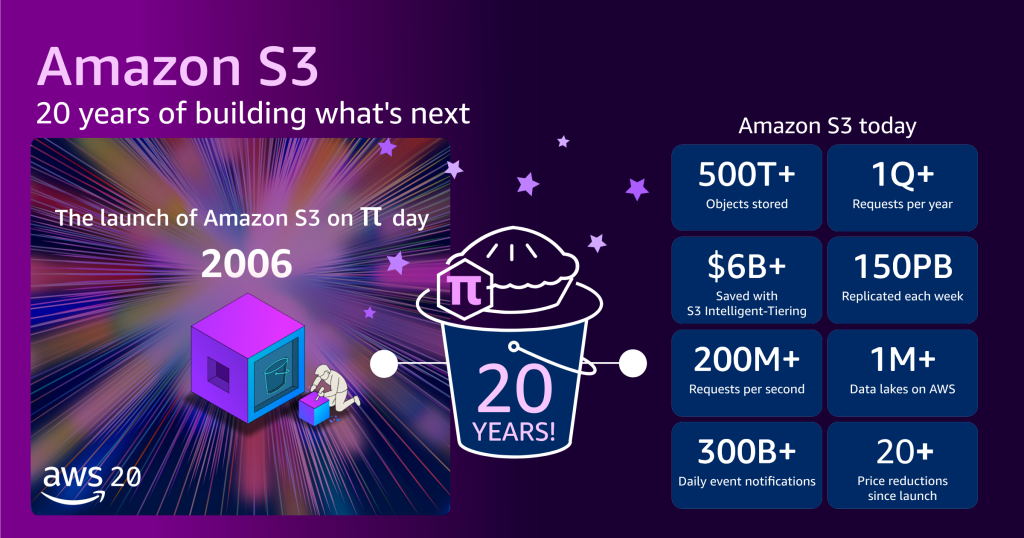
Amazon S3 の 20 年を振り返り、未来を築く
今から 20 年前の 2006 年 3 月 14 日、Amazon Simple Storage Servic […]
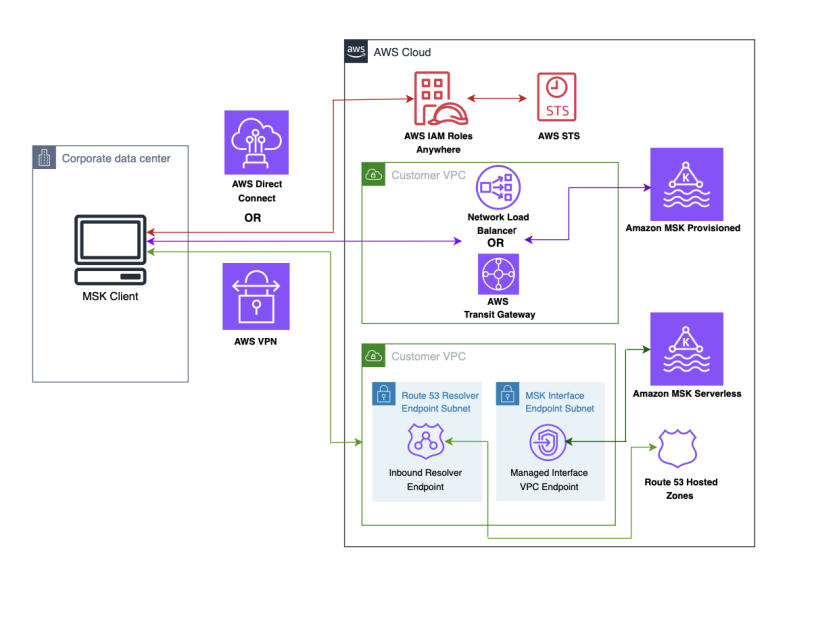
IAM Roles Anywhere を使用して AWS 外の Kafka クライアントから Amazon MSK にセキュアに接続する
本記事では、AWS IAM Roles Anywhere を使用して、AWS 外で動作する Kafka クライアントから Amazon MSK クラスターにセキュアに接続する方法を紹介します。X.509 証明書による一時的なセキュリティ認証情報の取得により、長期認証情報の管理が不要になり、セキュリティ体制を強化できます。

週刊生成AI with AWS – 2026/3/9 週
今回の週刊生成AI with AWSでは、三菱電機が AWS 上で開発した AI 商談支援サービス「Memory Tech」やサミットが Kiro で PoC を 12 時間で実現した事例など、生成 AI を実際のビジネスで活用するお客様事例に加え、Amazon Bedrock AgentCore Memory のストリーミング通知、Amazon Bedrock の新しいオブザーバビリティメトリクス、Kiro のエンタープライズガバナンス機能といったサービスアップデートも充実した一週間でした。製造業での Agentic AI 活用特集やフィジカル AI 開発支援プログラムのキックオフレポートなど、業界を問わず生成 AI の実践的な活用のヒントが詰まっていますので、ぜひブログ本編でチェックしてみてください。

Amazon Connect アップデート まとめ – 2026年2月
みなさん、こんにちは。Amazon Connect ソリューションアーキテクトの坂田です。 2026年2月に発 […]

Amazon S3 汎用バケットのアカウントリージョナル名前空間の紹介
2026 年 3 月 12 日、Amazon Simple Storage Service (Amazon S […]

AWS 上の Microsoft および VMware ワークロード: AWS re:Invent 2025 完全プレイリスト
AWS re:Invent 2025 の Microsoft および VMware ワークロード移行に関するセッションプレイリストを紹介します。AWS Transform によるエージェンティック AI での自動化、Amazon EVS でのネイティブ VMware 実行、CSL や Thomson Reuters などの顧客成功事例を含みます。

週刊AWS – 2026/3/9週
Amazon Route 53 Global Resolver が一般提供開始、Amazon Bedrock が First Token Latency と Quota Consumption の可観測性をサポート、Amazon Bedrock AgentCore Runtime がステートフル MCP サーバー機能をサポート開始、Amazon S3 が汎用バケット向けアカウントリージョナル名前空間を導入、Amazon EC2 Hpc8a / R8a インスタンスがアジアパシフィック (東京) で利用可能に、新しい SAM Kiro power でサーバーレスアプリケーション開発を加速

ブロックレベルレプリケーションを使用した Amazon RDS for SQL Server Web Edition の高可用性実装
この投稿では、SQL Server Web Edition の マルチ AZ RDS インスタンスをセットアップし、フェイルオーバーテストを通じてその高可用性機能を検証する方法を紹介します。