Amazon Web Services ブログ

【寄稿】「12時間で PoC が完成」― サミット株式会社の情報システム部門が AI コーディングアシスタント Kiro で実現した、圧倒的スピードの内製開発
こんにちは。AWS シニアソリューションアーキテクトの崔 祐碩です。首都圏を中心に 125 店舗のスーパーマー […]

AWS CloudShell で RDS / Aurora のリザーブドインスタンスを一括購入するサンプルスクリプト
Amazon Relational Database Service(以下、RDS)や Amazon Auro […]
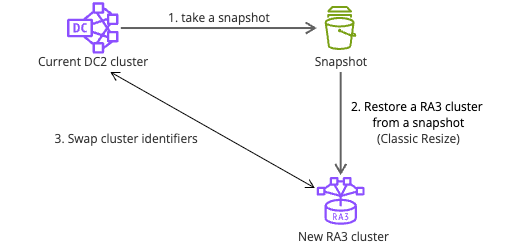
Amazon Redshift DC2 インスタンスからの移行アプローチ:お客様事例
本記事では、小売業の大手企業が Amazon Redshift DC2 から RA3 インスタンスへ移行した事例を紹介します。Blue-Green デプロイメントアプローチで安全に移行し、ETL クエリパフォーマンスの向上とストレージ容量の拡大を実現しました。マテリアライズドビューや AutoMV などの RA3 固有の機能を活用し、コスト効率を維持しながら全体的なクエリパフォーマンスを最適化した方法を解説します。

AWS Weekly Roundup: Amazon Connect Health、Bedrock AgentCore ポリシー、GameDay Europe など (2026 年 3 月 9 日)
Fiti (スワヒリ語のスラングで「最高」) AWS Student Community Kenya! 202 […]

試験運用から本番へ: Hannover Messe 2026 で知る AWS による産業 AI の大規模展開
本記事は 2026/03/11 に公開された “From Pilot to Production: […]

月刊 AWS 製造 2026年3月号
月刊 AWS 製造 2026年3月号 みなさん、こんにちは。AWS のソリューションアーキテクトの山田です。 […]

寄稿: 三菱電機が挑む製造業の商談変革 – AWS で実現した商談支援サービス「Memory Tech」
本稿は、三菱電機株式会社 名古屋製作所が新たに開発した AI を活用した商談支援サービス「Memory Te […]

セルフマネージド Db2 on Linux データベースを Amazon RDS for Db2 にリストアする
本投稿は、 2025 年 10 月 21 日に公開された記事 「Restore self-managed Db […]

Kinesis On-demand Advantage でストリーミングコストを 60% 以上削減
Amazon Kinesis Data Streams の On-demand Advantage モードを使用して、ストリーミングコストを 60% 以上削減する方法を 3 つの実際のシナリオで紹介します。安定したスループット、延長保持、Enhanced Fan-Out コンシューマーなど、さまざまなユースケースでのコスト最適化効果を検証しました。

「フィジカル AI 開発支援プログラム by AWS ジャパン」キックオフイベントを開催しました
2026 年 3 月 3 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フィ […]