AWS Big Data Blog
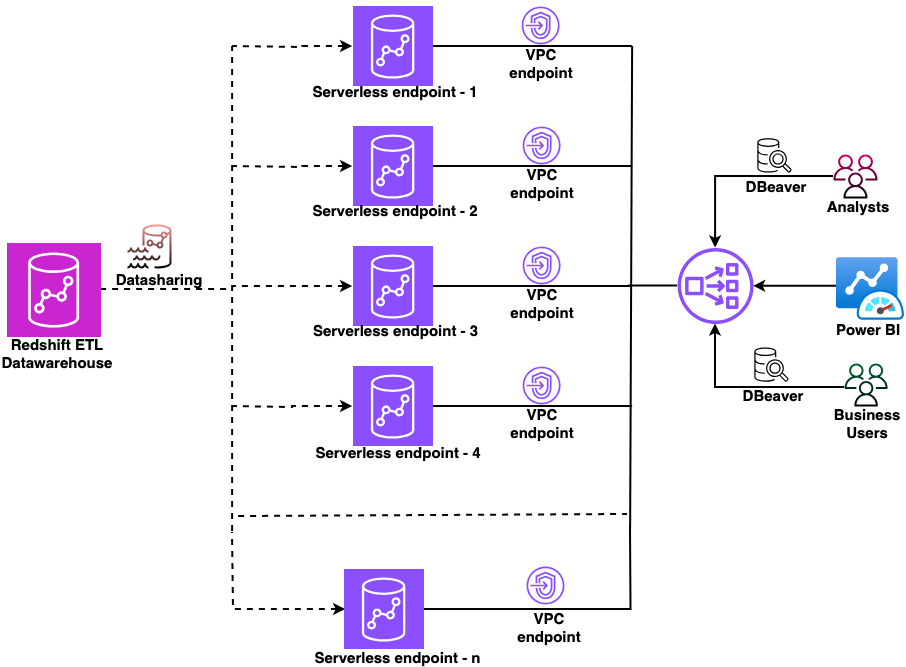
Secure multi-warehouse Amazon Redshift access behind a Network Load Balancer using Microsoft Entra ID
In this post, we show you how to configure a native identity provider (IdP) federation for Amazon Redshift Serverless using Network Load Balancer. You will learn how to enable secure connections from tools like DBeaver and Power BI while maintaining your enterprise security standards.

Securely connect Kafka client applications to your Amazon MSK Serverless cluster from different VPCs and AWS accounts
In this post, we show you how Kafka clients can use Zilla Plus to securely access your MSK Serverless clusters through Identity and Access Management (IAM) authentication over PrivateLink, from as many different AWS accounts or VPCs as needed. We also show you how the solution provides a way to support a custom domain name for your MSK Serverless cluster.

Build AWS Glue Data Quality pipeline using Terraform
AWS Glue Data Quality is a feature of AWS Glue that helps maintain trust in your data and support better decision-making and analytics across your organization. You can use Terraform to deploy AWS Glue Data Quality pipelines. Using Terraform to deploy AWS Glue Data Quality pipeline enables IaC best practices to ensure consistent, version controlled and repeatable deployments across multiple environments, while fostering collaboration and reducing errors due to manual configuration. In this post, we explore two complementary methods for implementing AWS Glue Data Quality using Terraform.

Automating data classification in Amazon SageMaker Catalog using an AI agent
If you’re struggling with manual data classification in your organization, the new Amazon SageMaker Catalog AI agent can automate this process for you. Most large organizations face challenges with the manual tagging of data assets, which doesn’t scale and is unreliable. In some cases, business terms aren’t applied consistently across teams. Different groups name and tag data assets based on local conventions. This creates a fragmented catalog where discovery becomes unreliable and governance teams spend more time normalizing metadata than governing. In this post, we show you how to implement this automated classification to help reduce the manual tagging effort and improve metadata consistency across your organization.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 2
(Continued from Part 1) In this post, we show how you can give on-premises clients and spoke account resources private access to OpenSearch Serverless collections distributed across multiple business unit accounts.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 1
In this post, we show how organizations can provide secure, private access to multiple Amazon OpenSearch Serverless collections from both on-premises environments and distributed AWS accounts using a single centralized interface VPC endpoint and Route 53 Profiles.

Extract data from Amazon Aurora MySQL to Amazon S3 Tables in Apache Iceberg format
In this post, you learn how to set up an automated, end-to-end solution that extracts tables from Amazon Aurora MySQL Serverless v2 and writes them to Amazon S3 Tables in Apache Iceberg format using AWS Glue.

Simplifying Kafka operations with Amazon MSK Express brokers
In this post, we show you how Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express brokers brokers streamline the end-to-end activities for Kafka administration.

Filter catalog assets using custom metadata search filters in Amazon SageMaker Unified Studio
Finding the right data assets in large enterprise catalogs can be challenging, especially when thousands of datasets are cataloged with organization-specific metadata. Amazon SageMaker Unified Studio now supports custom metadata search filters. In this post, you learn how to create custom metadata forms, publish assets with metadata values, and use structured filters to discover those assets.
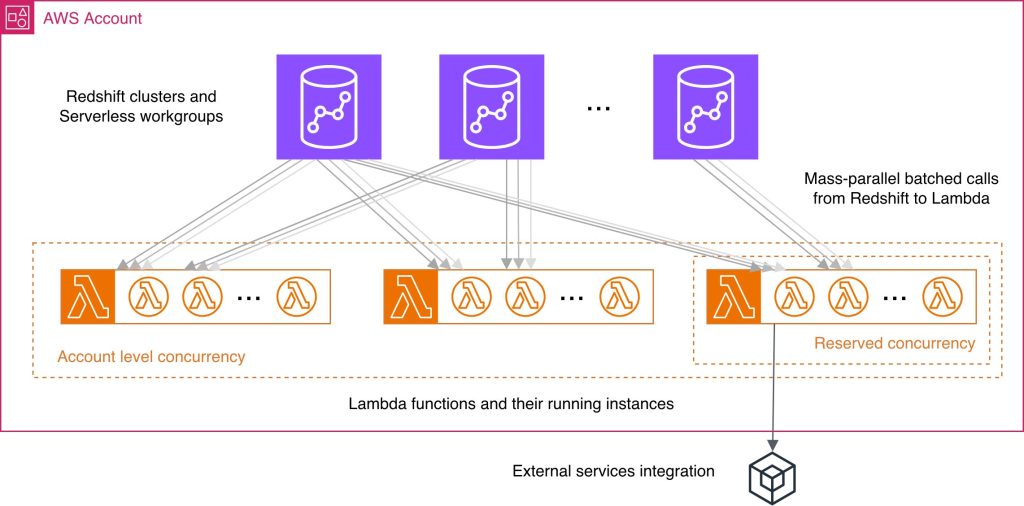
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.