AWS Compute Blog
A Serverless Authentication System by Jumia
Jumia is an ecosystem of nine different companies operating in 22 different countries in Africa. Jumia employs 3000 people and serves 15 million users/month.
Want to secure and centralize millions of user accounts across Africa? Shut down your servers! Jumia Group unified and centralized customer authentication on nine digital services platforms, operating in 22 (and counting) countries in Africa, totaling over 120 customer and merchant facing applications. All were unified into a custom Jumia Central Authentication System (JCAS), built in a timely fashion and designed using a serverless architecture.
In this post, we give you our solution overview. For the full technical implementation, see the Jumia Central Authentication System post on the Jumia Tech blog.
The challenge
A group-level initiative was started to centralize authentication for all Jumia users in all countries for all companies. But it was impossible to unify the operational databases for the different companies. Each company had its own user database with its own technological implementation. Each company alone had yet to unify the logins for their own countries. The effects of deduplicating all user accounts were yet to be determined but were considered to be large. Finally, there was no team responsible for manage this new project, given that a new dedicated infrastructure would be needed.
With these factors in mind, we decided to design this project as a serverless architecture to eliminate the need for infrastructure and a dedicated team. AWS was immediately considered as the best option for its level of
service, intelligent pricing model, and excellent serverless services.
The goal was simple. For all user accounts on all Jumia Group websites:
- Merge duplicates that might exist in different companies and countries
- Create a unique login (username and password)
- Enrich the user profile in this centralized system
- Share the profile with all Jumia companies
Requirements
We had the following initial requirements while designing this solution on the AWS platform:
- Secure by design
- Highly available via multimaster replication
- Single login for all platforms/countries
- Minimal performance impact
- No admin overhead
Chosen technologies
We chose the following AWS services and technologies to implement our solution.
Amazon API Gateway
Amazon API Gateway is a fully managed service, making it really simple to set up an API. It integrates directly with AWS Lambda, which was chosen as our endpoint. It can be easily replicated to other regions, using Swagger import/export.
AWS Lambda
AWS Lambda is the base of serverless computing, allowing you to run code without worrying about infrastructure. All our code runs on Lambda functions using Python; some functions are
called from the API Gateway, others are scheduled like cron jobs.
Amazon DynamoDB
Amazon DynamoDB is a highly scalable, NoSQL database with a good API and a clean pricing model. It has great scalability as well as high availability, and fits the serverless model we aimed for with JCAS.
AWS KMS
AWS KMS was chosen as a key manager to perform envelope encryption. It’s a simple and secure key manager with multiple encryption functionalities.
Envelope encryption
Oversimplifying envelope encryption is when you encrypt a key rather than the data itself. That encrypted key, which was used to encrypt the data, may now be stored with the data itself on your persistence layer since it doesn’t decrypt the data if compromised. For more information, see How Envelope Encryption Works with Supported AWS Services.
Envelope encryption was chosen given that master keys have a 4 KB limit for data to be encrypted or decrypted.
Amazon SQS
Amazon SQS is an inexpensive queuing service with dynamic scaling, 14-day retention availability, and easy management. It’s the perfect choice for our needs, as we use queuing systems only as a
fallback when saving data to remote regions fails. All the features needed for those fallback cases were covered.
JWT
We also use JSON web tokens for encoding and signing communications between JCAS and company servers. It’s another layer of security for data in transit.
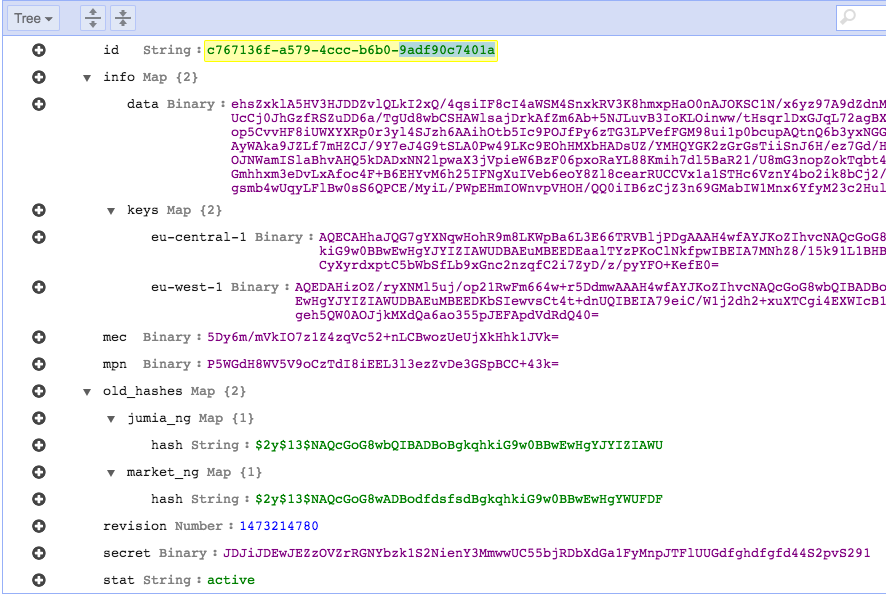
Data structure
Our database design was pretty straightforward. DynamoDB records can be accessed by the primary key and allow access using secondary indexes as well. We created a UUID for each user on JCAS, which is used as a primary key
on DynamoDB.
Most data must be encrypted so we use a single field for that data. On the other hand, there’s data that needs to be stored in separate fields as they need to be accessed from the code without decryption for lookups or basic checks. This indexed data was also stored, as a hash or plain, outside the main ciphered blob store.
We used a field for each searchable data piece:
Id(primary key)main phone(indexed)main email(indexed)account statusdocument timestamp
To hold the encrypted data we use a data dictionary with two main dictionaries, info with the user’s encrypted data and keys with the key for each AWS KMS region to decrypt the info blob.
Passwords are stored in two dictionaries, old_hashes contains the legacy hashes from the origin systems and secret holds the user’s JCAS password.
Here’s an example:
Security
Security is like an onion, it needs to be layered. That’s what we did when designing this solution. Our design makes all of our data unreadable at each layer of this solution, while easing our compliance needs.
A field called data stores all personal information from customers. It’s encrypted using AES256-CBC with a key generated and managed by AWS KMS. A new data key is used for each transaction. For communication between companies and the API, we use API Keys, TLS and JWT, in the body to ensure that the post is signed and verified.
Data flow
Our second requirement on JCAS was system availability, so we designed some data pipelines. These pipelines allow multi-region replication, which evades collision using idempotent operations on all endpoints. The only technology added to the stack was Amazon SQS. On SQS queues, we place all the items we aren’t able to replicate at the time of the client’s request.
JCAS may have inconsistencies between regions, caused by network or region availability; by using SQS, we have workers that synchronize all regions as soon as possible.
Example with two regions
We have three Lambda functions and two SQS queues, where:
1) A trigger Lambda function is called for the DynamoDB stream. Upon changes to the user’s table, it tries to write directly to another DynamoDB table in the second region, falling back to writing to two SQS queues.
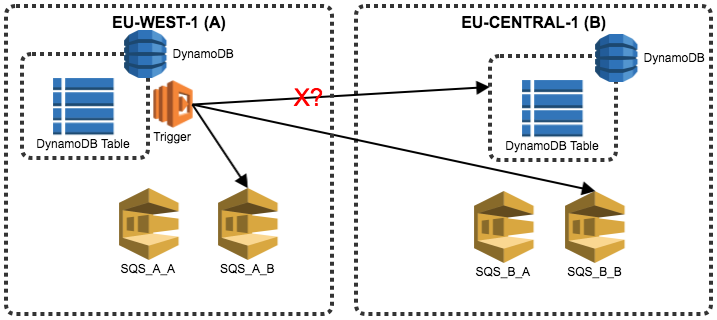
2) A scheduled Lambda function (cron-style) checks a SQS queue for items and tries writing them to the DynamoDB table that potentially failed.

3) A cron-style Lambda function checks the SQS queue, calling KMS for any items, and fixes the issue.
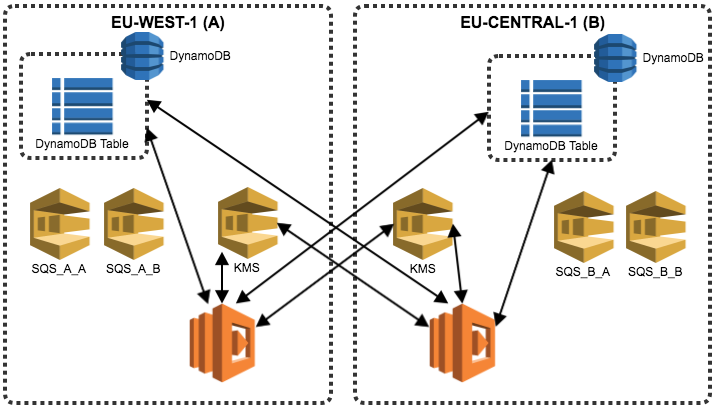
The following diagram shows the full infrastrucure (for clarity, this diagram leaves out KMS recovery).

Results
Upon going live, we noticed a minor impact in our response times. Note the brown legend in the images below.
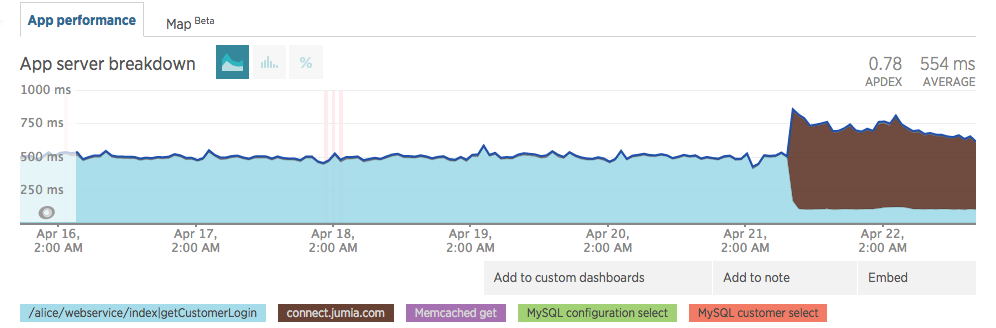
This was a cold start, as the infrastructure started to get hot, response time started to converge. On 27 April, we were almost at the initial 500ms.
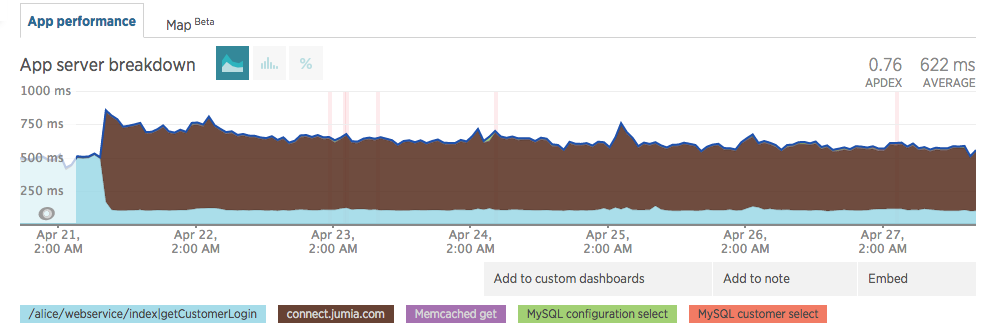
It kept steady on values before JCAS went live (≈500ms).
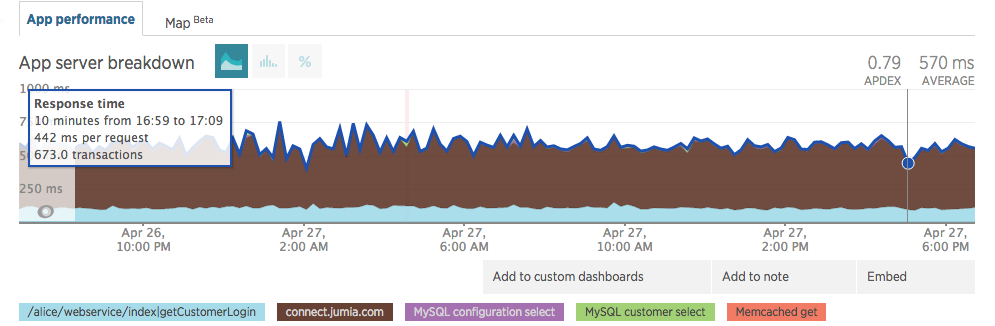
As of the writing of this post, our response time kept improving (dev changed the method name and we changed the subdomain name).
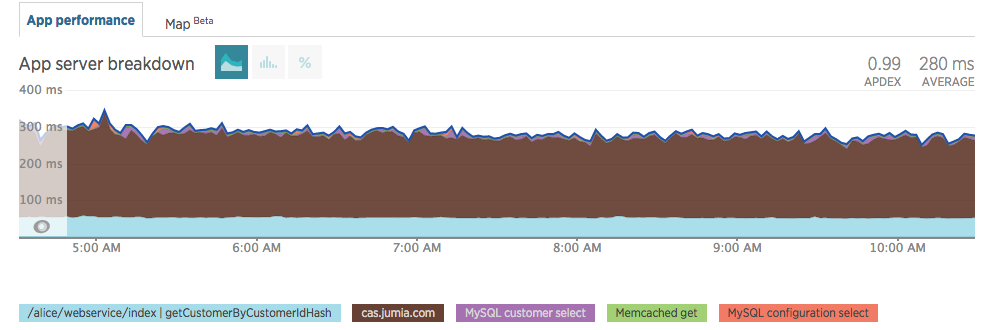
Customer login used to take ≈500ms and it still takes ≈500ms with JCAS. Those times have improved as other components changed inside our code.
Lessons learned
- Instead of the standard cross-region replication, creating your own DynamoDB cross-region replication might be a better fit for you, if your data and applications allow it.
- Take some time to tweak the Lambda runtime memory. Remember that it’s billed per 100ms, so it saves you money if you have it run near a round number.
- KMS takes away the problem of key management with great security by design. It really simplifies your life.
- Always check the timestamp before operating on data. If it’s invalid, save the money by skipping further KMS, DynamoDB, and Lambda calls. You’ll love your systems even more.
- Embrace the serverless paradigm, even if it looks complicated at first. It will save your life further down the road when your traffic bursts or you want to find an engineer who knows your whole system.
Next steps
We are going to leverage everything we’ve done so far to implement SSO in Jumia. For a future project, we are already testing OpenID connect with DynamoDB as a backend.
Conclusion
We did a mindset revolution in many ways.
Not only we went completely serverless as we started storing critical info on the cloud.
On top of this we also architectured a system where all user data is decoupled between local systems and our central auth silo.
Managing all of these critical systems became far more predictable and less cumbersome than we thought possible.
For us this is the proof that good and simple designs are the best features to look out for when sketching new systems.
If we were to do this again, we would do it in exactly the same way.
Daniel Loureiro (SecOps) & Tiago Caxias (DBA) – Jumia Group