AWS News Blog
Amazon SageMaker – Accelerating Machine Learning
Machine Learning is a pivotal technology for many startups and enterprises. Despite decades of investment and improvements, the process of developing, training, and maintaining machine learning models has still been cumbersome and ad-hoc. The process of incorporating machine learning into an application often involves a team of experts tuning and tinkering for months with inconsistent setups. Businesses and developers want an end-to-end, development to production pipeline for machine learning.
Introducing Amazon SageMaker
Amazon SageMaker is a fully managed end-to-end machine learning service that enables data scientists, developers, and machine learning experts to quickly build, train, and host machine learning models at scale. This drastically accelerates all of your machine learning efforts and allows you to add machine learning to your production applications quickly.
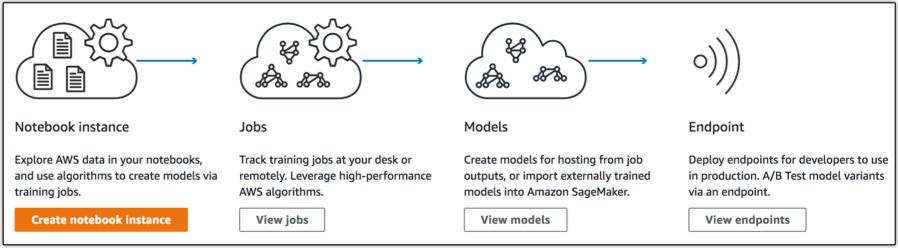
There are 3 main components of Amazon SageMaker:
- Authoring: Zero-setup hosted Jupyter notebook IDEs for data exploration, cleaning, and preprocessing. You can run these on general instance types or GPU powered instances.
- Model Training: A distributed model building, training, and validation service. You can use built-in common supervised and unsupervised learning algorithms and frameworks or create your own training with Docker containers. The training can scale to tens of instances to support faster model building. Training data is read from S3 and model artifacts are put into S3. The model artifacts are the data dependent model parameters, not the code that allows you to make inferences from your model. This separation of concerns makes it easy to deploy Amazon SageMaker trained models to other platforms like IoT devices.
- Model Hosting: A model hosting service with HTTPs endpoints for invoking your models to get realtime inferences. These endpoints can scale to support traffic and allow you to A/B test multiple models simultaneously. Again, you can construct these endpoints using the built-in SDK or provide your own configurations with Docker images.
Each of these components can be used in isolation which makes it really easy to adopt Amazon SageMaker to fill in the gaps in your existing pipelines. That said, there are some really powerful things that are enabled when you use the service end-to-end.
Working with SageMaker
I want to build, train, and deploy an Apache MXNet based image classifier. I’ll use the Gluon language, the CIFAR-10 dataset, and a ResNet V2 model architecture.
Authoring with Jupyter Notebooks

When I create a notebook instance it launches an ML compute instance that comes with Anaconda packages and libraries common in deep learning, a 5GB ML storage volume, and several example notebooks demonstrating various algorithms. I can optionally configure VPC support which creates an ENI in my VPC for easy and secure access to my resources.
Once my instance is provisioned I’m able to open my notebook and start writing some code!

Model Training
I’m going to leave out the actual model training code here for brevity, but in general for any kind of Amazon SageMaker common framework training you can implement a simple training interface that looks something like this:
def train(
channel_input_dirs, hyperparameters, output_data_dir,
model_dir, num_gpus, hosts, current_host):
pass
def save(model):
passI want to create a distributed training job on 4 ml.p2.xlarge instances in my Amazon SageMaker infrastructure. I’ve already downloaded all of the data I need locally.
import sagemaker
from sagemaker.mxnet import MXNet
m = MXNet("cifar10.py", role=role,
train_instance_count=4, train_instance_type="ml.p2.xlarge",
hyperparameters={'batch_size': 128, 'epochs': 50,
'learning_rate': 0.1, 'momentum': 0.9})Now that we’ve constructed our model training job we can feed it data by calling: m.fit("s3://randall-likes-sagemaker/data/gluon-cifar10").
If I navigate to the jobs console I can see that my job is running!

Hosting and Real Time Inferences
Now that my model has finished training I can start to generate predictions! Using the same code from earlier I’ll create and launch an endpoint.
predictor = m.deploy(initial_instance_count=1, instance_type='ml.c4.xlarge')
Then invoking the endpoint is as simple as running: predictor.predict(img_input)!
That’s an end-to-end Machine Learning pipeline in fewer than 100 lines of code.
I want to walk through one more example that shows how you could use just the model hosting components of Amazon SageMaker.
Using Custom Docker Containers
Amazon SageMaker defines a simple spec for Docker containers that allows you to easily write your own training algorithms or your own inference containers.
I have an existing model based on the architecture described here and I want to host this model for real time inferences.
I’ve created a simple Dockerfile and flask app to serve my inferences.
I’ve left my code that loads the models and generates predictions out here because yours will be different. Essentially, I built a method that would download an image from an input URL and then pass that image data onto the MXNet model for predictions.
from flask import Flask, request, jsonify
import predict
app = Flask(__name__)
@app.route('/ping')
def ping():
return ("", 200)
@app.route('/invocations', methods=["POST"])
def invoke():
data = request.get_json(force=True)
return jsonify(predict.download_and_predict(data['url']))
if __name__ == '__main__':
app.run(port=8080)FROM mxnet/python:latest
WORKDIR /app
COPY *.py /app/
COPY models /app/models
RUN pip install -U numpy flask scikit-image
ENTRYPOINT ["python", "app.py"]
EXPOSE 8080I push this image to ECR and then I navigate to the models console in Amazon SageMaker to create a new model.

After creating a new model I’ll provision an endpoint as well.

Now I can invoke the endpoint right from AWS Lambda or any other application! In fact I setup a twitter account to showcase this model. Just tweet @WhereML a picture to see if it can guess the location!
import boto3
import json
sagemaker = boto3.client('runtime.sagemaker')
data = {'url': 'https://pbs.twimg.com/media/DPwe4kMUMAAWCd_.jpg'}
result = sagemaker.invoke_endpoint(
EndpointName='predict',
Body=json.dumps(data)
)
Pricing
As part of the AWS Free Tier, you can get started with Amazon SageMaker for free. For the first two months of usage each month you’re provided 250 hours of t2.medium notebook usage, 50 hours of m4.xlarge usage for training, and 125 hours of m4.xlarge usage for hosting. Beyond the free tier, the pricing differs by region but is billed per-second of instance usage, per-GB of storage, and per-GB of Data transfer into and out of the service.
Before writing blog posts for re:Invent this year Jeff told me not to pick favorites. Well, I failed. Of some absolutely amazing launches, Amazon SageMaker is my favorite service of re:Invent 2017. I absolutely cannot wait to see what our customers are able to accomplish with such an exciting suite of tools.
– Randall