AWS Big Data Blog
How Goldman Sachs migrated from their on-premises Apache Kafka cluster to Amazon MSK
This is a guest post by Zachary Whitford, Associate, Richa Prajapati, Vice President and Aldo Piddiu, Vice President in the Global Investment Research engineering team at Goldman Sachs. To see how Goldman Sachs is innovating more with AWS visit Goldman Sachs Leading Cloud Innovator page.
The Global Investment Research (GIR) division at Goldman Sachs delivers client-focused research in the equity, fixed income, currency, and commodities markets. GIR analysts help the firm’s investor clients achieve superior returns through differentiated investment insights. This base foundation of GIR is now being leveraged as a firmwide publishing platform: GS Publishing.
In 2018, GIR was one of the first business units at Goldman Sachs that started using AWS, and began by first refactoring their already existing on-premises tech stack. To learn more about GIR’s journey, see, AWS on Air 2020: Voice of the Customer – Goldman Sachs and AWS re:Invent 2019: Tale of two cities: Goldman Sachs’s hybrid migration approach. GIR continues to consistently refactor portions of their on-premises tech stack, move the corresponding services and data stores to AWS, and retire the on-premises components. As a result, GIR has realized great agility, cost savings, elasticity, and operational stability from running on AWS. One of the most critical components of this tech stack is Apache Kafka.
Apache Kafka is an open-source, distributed event streaming platform commonly used for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. However, Apache Kafka clusters can be challenging to set up, scale, and manage in production. When you run Apache Kafka on your own, you need to provision servers, configure Apache Kafka manually, replace servers when they fail, orchestrate server patches and upgrades, architect the cluster for high availability, ensure data is durably stored and secured, set up monitoring and alarms, and carefully plan scaling events to support load changes.
GIR uses Apache Kafka as the backbone in its architecture to facilitate the exchange of messages between processes, and as a result, make the architecture loosely coupled. This backbone is responsible for orchestrating the publication workflow to ensure content reaches various distribution channels (such as portal, API, and mobile push notification). As a part of their cloud journey, GIR had already migrated applications to AWS that don’t rely on Apache Kafka. The next logical step was to move the Apache Kafka backbone to AWS. Amazon Managed Streaming for Apache Kafka (Amazon MSK) makes it easy for GIR to build and run production applications on Apache Kafka without needing Apache Kafka infrastructure management expertise, which provides GIR the freedom to focus on their application architecture and business requirements.
Migration options
While evaluating possible migration options, GIR focused on balancing the business impact that the time to migration would cause against causing potential disruptions by rushing the migration too prematurely. GIR operates on strict regulatory guidelines for research publication; any issues with publication results in significant regulatory, reputational, and monetary risk. GIR is in the 24/7 business for their clients, and can only have a finite, planned publication ingestion downtime window, so any option that they picked had to satisfy completion within that window. To achieve this, GIR evaluated the following two migration approaches:
- Option 1: Switch all services at once to point to Amazon MSK – Perform an atomic cutover of all the Apache Kafka dependent services to point to Amazon MSK in one go. A maintenance window with a hard downtime is planned to ensure that services aren’t actively processing requests during this cutover period.
- Option 2: Switch specific services individually to point to Amazon MSK – Only a specific subset of services is migrated to start using Amazon MSK. The overall application operates in a hybrid mode, in which some services connect to Amazon MSK and others to the on-premises Apache Kafka.
GIR thoroughly tested and evaluated both options by building out multiple proof of concepts and performing multiple analyses. In the end, GIR chose Option 1, because it allowed them to complete the migration within their stipulated planned downtime window and was the cleanest of the two options. Although GIR didn’t use Option 2 for their production migration, it’s a viable approach that you can consider for your migration.
In this post, we look at how GIR implemented Option 1. This post also discusses the specifics of how GIR carried out testing Option 2, with the goal of passing on the findings to you, which may help you with your migration planning. Both strategies relied on using Apache Kafka MirrorMaker 2.0 (MM2) for the migration.
Apache Kafka MirrorMaker
Apache Kafka MirrorMaker is a standalone tool for copying data and configurations between two Apache Kafka clusters. This post focuses on MM2 because it provides specific features that GIR required for their migration. MM2 enables the replication of messages and topic configurations, ACLs, consumer groups, and offsets between Apache Kafka clusters with either unidirectional or bidirectional mirroring. It migrates topic configurations (replication factor and partition count) from the source cluster to the destination cluster. It also enables you to control which topics are mirrored between clusters, as well as the naming pattern used for the mirrored topics. For information about using MirrorMaker with Amazon MSK, see Migrating Clusters Using Apache Kafka’s MirrorMaker and the hands-on lab MirrorMaker2 on Amazon EC2.
GIR’s migration strategy
At a high level, GIR’s migration and connectivity layout (as shown in the following diagram) required connectivity to the MSK cluster from on premises via AWS PrivateLink. Goldman Sachs’s on-premises network is connected to a specific AWS account called the GS Transit Account, and an application team like GIR drops an AWS PrivateLink endpoint into the transit VPC for on-premises clients to be able to connect to it.
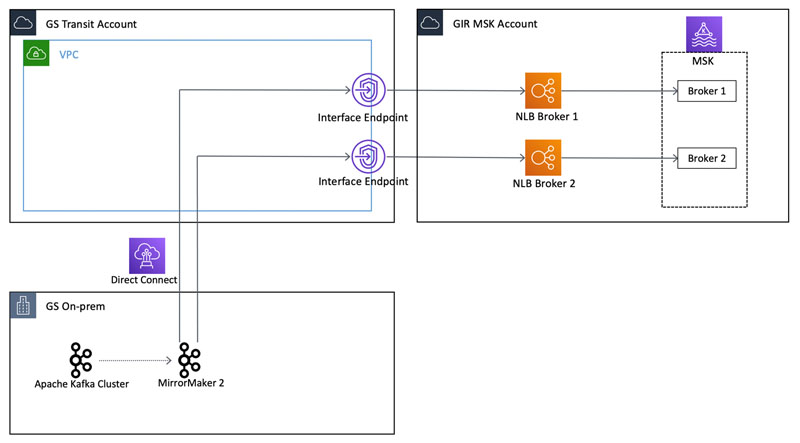
The specifics of why and how Goldman Sachs uses this network pattern is out of scope for this post, but more details about it is explained in the re:Invent 2020 presentation Security at scale: How Goldman Sachs manages network and access control.
GIR’s migration using Option 1
As discussed earlier in the post, GIR chose Option 1 to migrate their cluster to Amazon MSK—they planned a hard downtime and switched all their services to point to Amazon MSK all at once. The sequence of events that GIR implemented are depicted via the following functional diagram. For simple representation, this diagram only shows the interaction between components across on-premises services and AWS, and doesn’t show the specifics of network connectivity flows that was shown in the previous image.

The diagram depicts the following sequence of events:
- GIR uses Avro Schemas and a schema registry to validate the messages published to the Apache Kafka topics. These messages are validated against the registered schema using a schema registry service. Before starting any data migration, GIR hosted a schema registry service in AWS, which they started using for any new and AWS-only hosted applications connecting to Amazon MSK. Before switching any on-premises service connecting to Apache Kafka to use Amazon MSK, GIR migrated all the on-premises schemas to AWS. To accomplish this, GIR did the following:
- Deleted the existing
_schemastopic on Amazon MSK (after ensuring the services connected to Amazon MSK and the schema registry in AWS were stopped). - Mirrored the
_schemastopic and its configuration from on premises to Amazon MSK using unidirectional mirroring with MM2.
- Deleted the existing
GIR replicated the _schemas topic from the on-premises instance instead of manually registering the schema so that the Avro Schema IDs would be retained from on premises. This allows consumers to rewind and read old messages still within the retention period using the schema registry in AWS.
At the time of this migration, the AWS Glue Schema Registry wasn’t available. However, it’s available now and can be used in AWS. For more information, refer to Validate, evolve, and control schemas in Amazon MSK and Amazon Kinesis Data Streams with AWS Glue Schema Registry.
- After the schemas were migrated, GIR cut over all their on-premises applications to use the AWS hosted schema registry. This was an important step because they couldn’t fully decommission their on-premises Apache Kafka cluster without migrating their schema registry.
- The next step was to migrate the Kafka topics and topic configurations. GIR again used unidirectional mirroring to replicate the topics and messages from on-premises Kafka topics to Amazon MSK. One important note is that GIR overrode the MM2 default behavior of adding a prefix to the remote topics in order to keep the topic names the same as the on-premises topics. GIR achieved this by overriding the MM2 default replication policy with a custom replication policy class that created the topics without appending any prefix for the topic names on the remote cluster. GIR did this so that none of the applications would have to change the topics they produce or consume from when switching from on-premises Kafka to Amazon MSK. The whole migration process took around 5 hours and GIR encountered some issues during this migration, which are outlined later in this post.
Steps 1–3 happened before planned publication ingestion downtime and had no impact. Planned time started with Step 4.
- All services that were pointing to the on-premises Apache Kafka cluster were brought down to ensure that services weren’t actively processing requests and all messages were consumed during this cutover period. The services were modified to point to the DNS endpoints of the Amazon MSK brokers. The MM2 process was also turned off at this point because no new messages were expected to be mirrored from on premises from this point forward.
- The services, now pointing to Amazon MSK instead of on-premises Apache Kafka, were all brought up and tested end to end.
In this section, we saw how GIR implemented Option 1. Let’s look at how GIR evaluated Option 2 and discuss why GIR chose Option 1 over Option 2 for their migration, the challenges they faced overall, and lessons learned.
GIR’s evaluation of Option 2
As discussed earlier, one of the primary requirements for the migration was GIR’s ability to cut over their services from on-premises Apache Kafka to Amazon MSK without any business impact. To achieve this, GIR looked into Apache Kafka mirroring to enable an incremental migration of their services to Amazon MSK instead of a single, massive cutover that would require downtime. GIR found that because of their mesh of dependencies across different topics, the most resilient way to achieve this was by configuring bidirectional mirroring so that some services could point to Amazon MSK while other services continued pointing to on-premises Apache Kafka.
An important note to make here is that MM2 appends a naming prefix to all mirrored topics in the remote cluster (the cluster where the topic is being mirrored to) by default. With the default replication policy, although you can change the prefix value, you can’t remove it entirely. To counteract this without using a custom replication policy or having to change applications to use a different topic name after the cutover, GIR leveraged the ability of Apache Kafka clients to use a regex pattern to specify the topic names to use, rather than a specific topic name.
Let’s go into the specifics of how GIR implemented a proof of concept for Option 2 with an example. For their evaluation, GIR had two services, Service A and Service B, pointing to the on-premises Apache Kafka cluster. Both services were producing to and consuming from different topics, as shown in the following diagram.
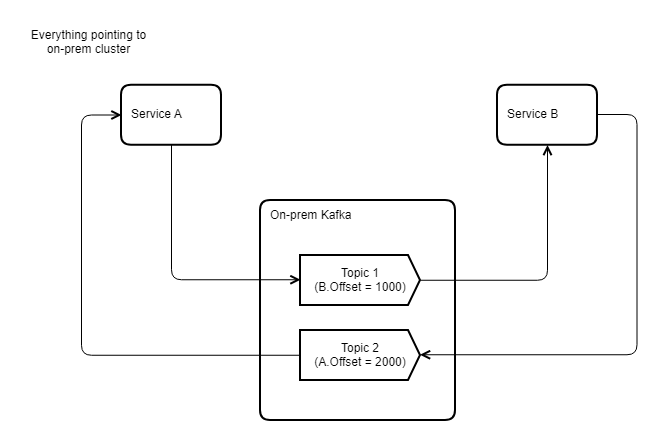
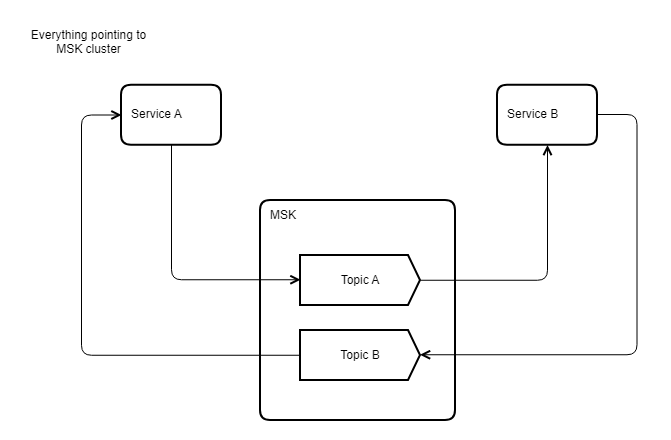
GIR wanted to switch Service B to point to Amazon MSK while Service A continued to point on premises. However, Service A still needed to consume the data produced by Service B on Topic 2. They could achieve this by mirroring the topic, Topic 2, to the on-premises cluster. GIR used MM2 to mirror this topic so Service A could listen to AWS.Topic2 and still consume the data that was produced on Amazon MSK Topic 2 by Service B, as shown in the following updated diagram. Similarly, GIR mirrored Topic 1 so that the data could be consumed by Service B from the mirrored Amazon MSK topic.
This way, after Service B is switched from on-premises Apache Kafka to Amazon MSK, it starts consuming from the correct offset and maintains the at-least-once message consumption guarantee. A model like this allows an incremental migration of applications without a period of significant downtime.
The offsets of the mirrored messages may not be the same as the source cluster. This could be a result of network issues in the MirrorMaker process that can cause commit failures and subsequent retries, which can potentially cause duplication of messages. This could also be caused by expired messages on the source cluster not being mirrored onto the destination cluster. However, MirrorMaker keeps track of the committed offsets for a consumer group via an internal topic. When cutting over a consumer to the target cluster, GIR considered using RemoteClusterUtils, a new class available in Apache Kafka 2.4.0 and above, to look up the correct translated offset for the consumer group on the new cluster. This allows consumers to continue from where they left off after migration to the new cluster with zero to minimal processing of duplicate messages.

Another route that you can consider is using a custom replication policy and a background process to sync MM2 checkpointed offsets to the consumer_offsets internal topic at the destination. This requires no change to the consumer code. This does require a separate application that syncs offsets, runs in the background, and has a dependency on connect-mirror-client and kafka-clients available with Apache Kafka 2.5.0 and above. A recent enhancement to MM2 in version 2.7.0 of Apache Kafka now includes a feature to automatically sync the offsets from source to target. However, this feature wasn’t available during GIR’s proof of concept of this option.
Similar to Option 1, GIR utilized MM2’s unidirectional mirroring component for Avro schemas migration. This was in addition to using MM2 for topic data migration itself.
GIR then used bidirectional mirroring feature of MM2 to keep the two clusters in sync. After all services were successfully pointed to Amazon MSK, relying on the legacy Apache Kafka cluster and MM2 was no longer required (as shown in the following diagram), because no publishers or consumers were communicating with that cluster.
Why GIR chose Option 1
GIR’s stack had about 12 microservices spread over 30 instances that were in scope for this migration. In addition to the technical considerations, GIR had to weigh the time invested vs. the gain that would be realized with both options. If GIR had chosen Option 2, they would have had to rewrite some of their Spring Kafka library implementations, which further would have required an update and deployment of every service as a prerequisite to the migration. Rewriting the library functions would also incur regression and other compatibility costs. Lastly, they would have needed a meticulous migration plan in place to ensure all upstream dependencies were well understood, and some of those dependencies weren’t controlled by GIR.
On the contrary, the upside of Option 1 was its overall simplicity, because a fundamental knowledge of service and dependencies wasn’t necessary. Although this approach was relatively risky because a single error would result in rolling back the entire migration, it removed the overhead of operating in a hybrid mode.
Taking these factors into consideration, and assessing the risk appetite and timelines of the complete cutover, GIR decided to take the cleanest approach: Option 1. That being said, Option 2 is absolutely viable from a technical perspective, provided all the relevant external and internal factors are considered before making the final call.
Observations, challenges faced, and lessons learned
GIR learned several valuable takeaways from this migration journey.
Firstly, MM2 is extremely useful for migrations and disaster recovery because of its ability to replicate messages, topics, schemas, and synchronize offsets between clusters. This enables you to point producers and consumers to two different clusters—in GIR’s case, on-premises Apache Kafka and Amazon MSK—while retaining business functionality. In summary, MM2 in conjunction with Amazon MSK can be an effective strategy for migrating Apache Kafka-based workloads to the cloud with minimal or no business impact.
The entire migration took around 7 hours to complete, and a majority of this time was spent on the migration of the historical topic data to Amazon MSK and rebooting on-premises services.
While mirroring their production topics, GIR observed failures because of non-optimal configuration parameter values, specifically the following:
- MM2 timed out while flushing the messages. It threw an exception and stopped mirroring any messages. The default flush timeout in MM2 is 5,000 milliseconds, which wasn’t enough for mirroring GIR’s production data. GIR was able to fix it by increasing the timeout to 30,000 milliseconds.
- MM2 didn’t flush messages correctly. At one point, GIR saw that MM2 was flushing zero messages even though all the messages weren’t mirrored yet. The reason for this was because the default request size was too small for GIR’s messages. This could be fixed by increasing max.request.size and max.message.bytes.
GIR also experienced timeouts while producing messages to Amazon MSK. As discussed earlier in this post, GIR connected to their MSK clusters using AWS PrivateLink and Network Load Balancers (NLB). When GIR switched their services to Amazon MSK, the Apache Kafka clients and services started observing timeouts from Amazon MSK. The reason for this was the default connection idle timeout configured on the Apache Kafka client library was 540 seconds, whereas the unconfigurable timeout for an NLB is 350 seconds, which meant that the NLB connections were timing out before the client connections. This resulted in the clients trying to send messages on a defunct connection and waiting for a timeout, which by default was 30 seconds. After the timeout, the clients were able to reestablish a connection and send messages, but there was the overall delay in sending messages after a period of idling. GIR was able to fix it by setting connections.max.idle.ms to less than 350 seconds.
GIR felt that MM2 should come with more out-of-the-box support for one-time migrations. To accomplish many of the behaviors needed for the migration, GIR had to override a significant number of configurations that violated some of the invariants of MM2’s Java templates. According to the spec, if a topic doesn’t exist in an upstream cluster, you should return a null value for the source cluster of said topic. GIR set every topic as having a source cluster of the mirror-from cluster, otherwise the mirroring of the topic properties wouldn’t work. This is a requirement of the custom replication policy.
Finally, GIR determined that MM2 should provide more visibility into the current state of mirroring between clusters as well as the overall progress, and they had an overall lack of comprehensive documentation on MM2.
Conclusion
In this post, we discussed how the Global Investment Research team at Goldman Sachs migrated from their on-premises Apache Kafka environment to Amazon MSK using MirrorMaker 2. We also discussed in detail an additional option that Goldman Sachs evaluated for this migration and why they ended up not choosing it. You can use this migration journey as a reference when considering migrating to an Amazon MSK environment.
Acknowledgments
The authors would like to thank the following members of the AWS and GS – Global Investment Research teams for their close collaboration and guidance through the various stages of this post’s journey:
- Harsha W Sharma, Solutions Architect, AWS
- Rajeev Chakrabarti, Principal Developer Advocate, Amazon MSK, AWS
- Steve Cooper, Principal Solutions Architect, AWS
- Abhishek Rai, Vice President, GIR
- Ankur Gurha, Vice President, GIR
- Victoria Ledda, Managing Director, GIR

About the Authors
 Zach Whitford is an Associate at Goldman Sachs in New York. Zach joined Goldman Sachs in 2018, graduating from the University of Michigan and has helped migrate GS applications to the cloud as well as onto Kafka. Zach is passionate about driving innovation in cloud systems and learning new technologies.
Zach Whitford is an Associate at Goldman Sachs in New York. Zach joined Goldman Sachs in 2018, graduating from the University of Michigan and has helped migrate GS applications to the cloud as well as onto Kafka. Zach is passionate about driving innovation in cloud systems and learning new technologies.
 Richa Prajapati is a Vice President at Goldman Sachs in New York. Richa joined Goldman Sachs in 2015 and has been responsible for building micro-services and event-driven architectures for firm’s Research platform. Most recently, Richa worked on migrating many on-premise services to AWS and building new systems which are completely hosted in AWS.
Richa Prajapati is a Vice President at Goldman Sachs in New York. Richa joined Goldman Sachs in 2015 and has been responsible for building micro-services and event-driven architectures for firm’s Research platform. Most recently, Richa worked on migrating many on-premise services to AWS and building new systems which are completely hosted in AWS.
 Aldo Piddiu is a Vice President at Goldman Sachs in London. Aldo joined Goldman Sachs in 2018 and has been responsible for building micro-services and event-driven architecture for ingesting content into firm’s Research Platform. Most recently, Aldo has been working on re-architecting portions of the Content Ingestion platform which will be hosted in AWS.
Aldo Piddiu is a Vice President at Goldman Sachs in London. Aldo joined Goldman Sachs in 2018 and has been responsible for building micro-services and event-driven architecture for ingesting content into firm’s Research Platform. Most recently, Aldo has been working on re-architecting portions of the Content Ingestion platform which will be hosted in AWS.