AWS News Blog
Amazon DynamoDB Update – Online Indexing & Reserved Capacity Improvements

|
Developers all over the world are using Amazon DynamoDB to build applications that take advantage of its ability to provide consistent low-latency performance. The developers that I have talked to enjoy the flexibility provided by DynamoDB’s schemaless model, along with the ability to scale capacity up and down as needed. They also benefit from the DynamoDB Reserved Capacity model in situations where they are able to forecast their need for read and write throughput ahead of time.
A little over a year ago we made DynamoDB more flexible by adding support for Global Secondary Indexes. This important feature moved DynamoDB far beyond its roots as a key-value store by allowing lookups on attributes other than the primary key.
Today we are making Global Secondary Indexes even more flexible by giving you the ability to add and delete them from existing tables on the fly.
We are also making it easier for you to purchase Reserved Capacity directly from the AWS Management Console. As part of this change to a self-service model, you can now purchase more modest amounts of Reserved Capacity than ever before.
Let’s zoom in for a closer look!
Global Secondary Indexes on the Fly
Up until now you had to define the Global Secondary Indexes for each of your DynamoDB tables at the time you created the table. This static model worked well in situations where you fully understood your data model and a good sense for the kinds of queries that you needed to use to build your application.
DynamoDB’s schemaless model means that you can add new attributes to an existing table by simply storing them. Perhaps your original table stored a first name, a last name, and an email address. Later, you decided to make your application location-aware by adding a zip code. With today’s release you can add a Global Secondary Index to the existing table. Even better, you can do this without taking the application offline or impacting the overall throughput of the table.
Here’s how you add a new index using the AWS Management Console. First, select the table and click on Create Index:
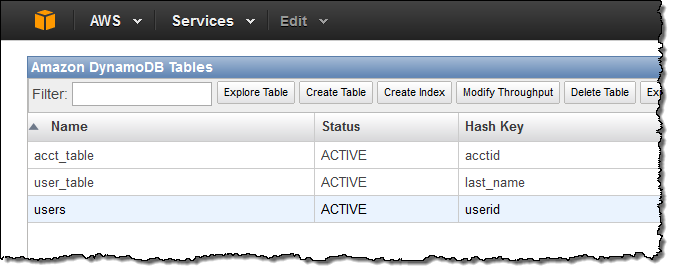
Then enter the details (you can use a hash key or a combination of a hash key and a range key):
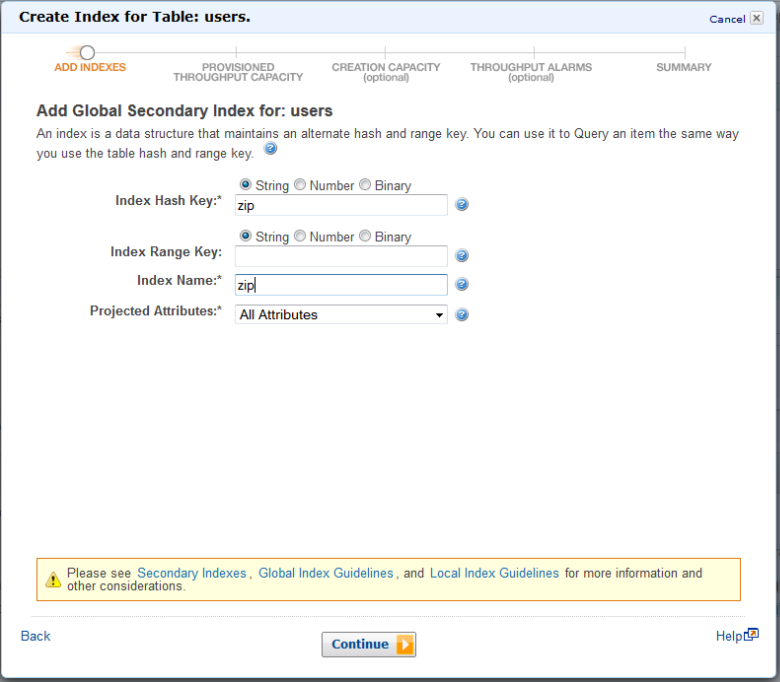
The index will be created and ready to go before too long (the exact time depends on the number of items in the table and the amount of provisioned capacity). You can also delete indexes that you no longer need. All of this functionality is also available through DynamoDB’s UpdateTable API.
There is no extra charge for this feature. However, you may need to provision additional write throughput in order to allow for the needs of the index creation process. You’ll pay the usual DynamoDB price for storage of the Global Secondary Indexes that you create.
Purchasing Reserved Capacity
DynamoDB’s unique provisioned capacity model makes it easy for you to build applications that can scale to any desired level of throughput. Instead of having to worry about adding hardware, tuning software, or rearchitecting your application as traffic grows, you can simply provision additional read or write capacity. The provisioning model even allows you to add capacity in anticipation of high traffic (perhaps your application is busiest during local business hours) and to remove it when it is not needed. This model allows you to create a cost structure that closely mirrors actual usage of your application and avoids unnecessary charges for idle resources.
In situations where you have enough confidence in your usage model and your predictions for growth over time, you can reduce your DynamoDB costs even more by purchasing Reserved Capacity for a one or a three year term. After you pay the upfront fee, you will be billed monthly for the amount of capacity that you purchase. By purchasing capacity up front, you will save 53% (one year term) or 76% (three year term) over the regular hourly rates.
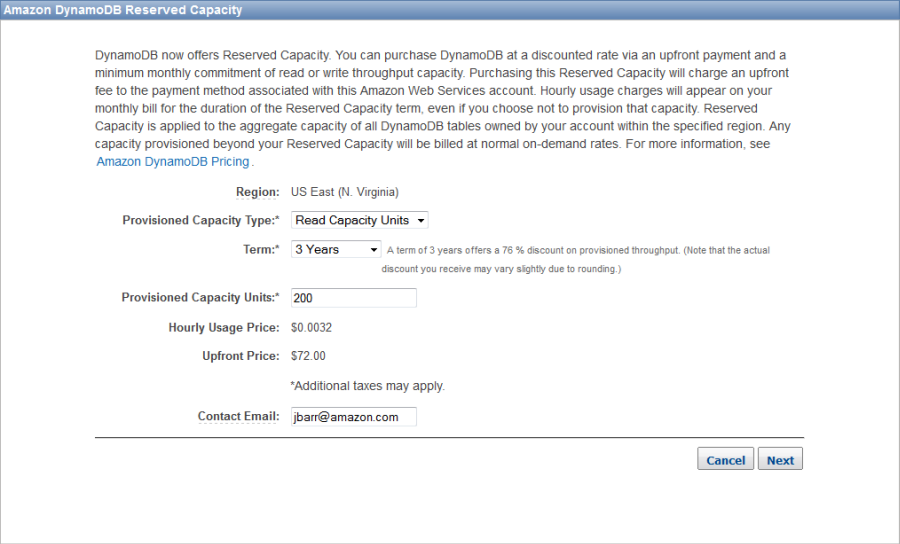
In order to make Reserved Capacity accessible to more DynamoDB users, we have made two important changes. First, we have simplified the purchase process and made it accessible from within the Console. Second, we have reduced the minimum purchase to just 100 read or write capacity units. To purchase Reserved Capacity within a particular AWS region, open up the Console, choose the region, and click on the Reserved Capacity button:
Select the amount of read and/or write capacity that you need (in units of 100), choose a term, and fill in your email address:
Your purchases are visible in the Console:
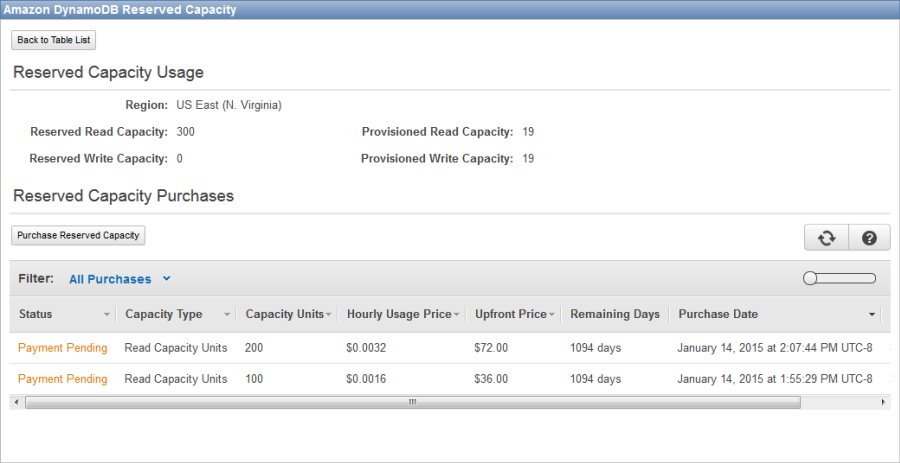
You can read more about this feature in the recent post, On DynamoDB Provisioning: Simple, Flexible, and Affordable, in the AWS Startup Collection.
From our Customers
AWS customer Eddie Dingels (Lead Architect for Earth Networks) is already taking advantage of on-the-fly indexing and the new pricing model! In his words:
With online indexing, we can re-index tables to run new queries whenever we want. DynamoDB handles consistently changing the index while taking live traffic without a performance impact even on large data sets.
He’s also saving money:
DynamoDB has a very simple and innovative approach to database provisioning, it is truly pay as you go. Reserved capacity ends up dropping DynamoDB throughput costs by up to 76%, and today’s announcement makes it easier than ever for us to perform incremental purchases as we grow.
Availability
The new Reserved Capacity pricing model is available today in all regions. Online indexing is available today in the Asia Pacific (Tokyo), Asia Pacific (Singapore), Europe (Ireland), US East (N. Virginia), US West (Oregon), and US West (N. California) regions. We expect to make it available in the Europe (Frankfurt), South America (São Paulo), China (Beijing), and AWS GovCloud (US) regions within a week or so.
— Jeff;
PS – Some of our developers put together a new article to show you how to Build a Mars Rover Application With DynamoDB. The code in this article takes advantage of the new JSON support and is a great way to exercise DynamoDB’s expanded free tier.