AWS News Blog
New Scheduling Options for AWS Data Pipeline
The AWS Data Pipeline lets you automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking.
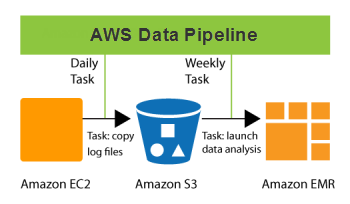
Today we are making the Data Pipeline more flexible and more useful with the addition of a new scheduling model that works at the level of an entire pipeline. This builds upon the existing model, which allows you to schedule the individual activities within a pipeline.
You can now choose between the following options for each pipeline that you build:
- Run once
- Run a defined number of times
- Run on activation
- Run indefinitely
- Run repeatedly within a date range
The schedule that you set for each pipeline will be inherited by every object in the pipeline. If you need to create multiple schedules for complex pipelines you can still set schedules for individual objects.
You can set the schedule from the AWS Management Console and from the Data Pipeline APIs. The console allows you to set the schedule when you create a new pipeline:
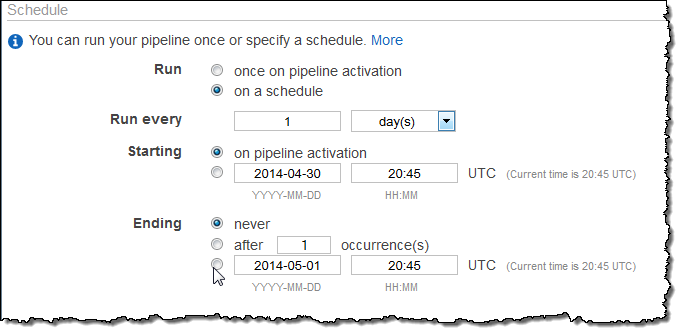
This new feature is available now and you can start using it today. You can read all about Data Pipeline Schedules to learn more.
— Jeff;