AWS News Blog
Tag: Amazon S3
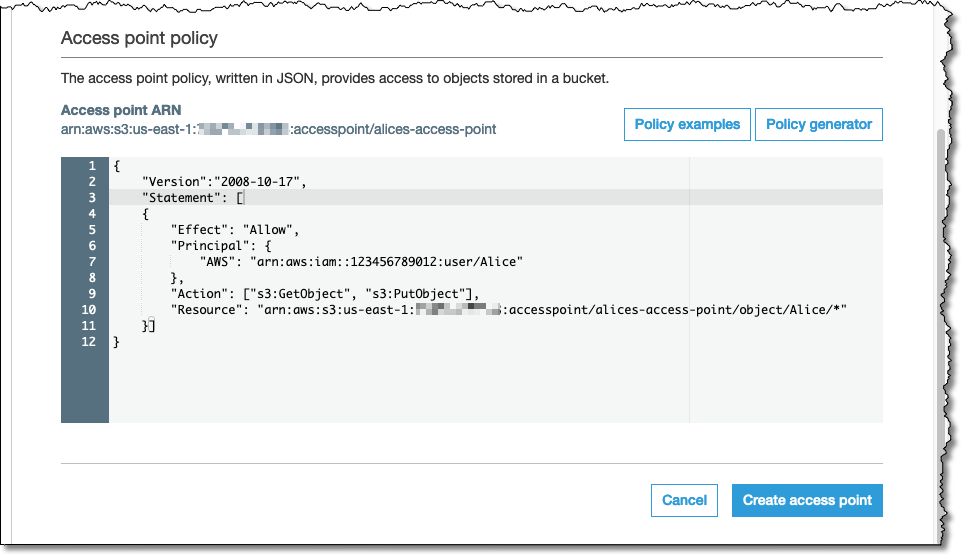
Easily Manage Shared Data Sets with Amazon S3 Access Points
Storage that is secure, scalable, durable, and highly available is a fundamental component of cloud computing. That’s why Amazon Simple Storage Service (S3) was the first service launched by AWS, back in 2006. It has been a building block of many of the more than 175 services that AWS now offers. As we approach the […]

Learn From Your VPC Flow Logs With Additional Meta-Data
Flow Logs for Amazon Virtual Private Cloud (Amazon VPC) enables you to capture information about the IP traffic going to and from network interfaces in your VPC. Flow Logs data can be published to Amazon CloudWatch Logs or Amazon Simple Storage Service (Amazon S3). Since we launched VPC Flow Logs in 2015, you have been […]

New – S3 Sync capability for EC2 Systems Manager: Query & Visualize Instance Software Inventory
It is now essential, with the fast paced lives we all seem to lead, to find tools to make it easier to manage our time, our home, and our work. With the pace of technology, the need for technologists to find management tools to easily manage their systems is just as important. With the introduction […]

Hightail — Empowering Creative Collaboration in the Cloud
Hightail – formerly YouSendIt – streamlines how creative work is reviewed, improved, and approved by helping more than 50 million professionals around the world get great content in front of their audiences faster. Since its debut in 2004 as a file sharing company, Hightail shifted its strategic direction to focus on delivering value-added creative collaboration […]
AWS Knowledge Center Video: Preparing to Send a Snowball Back to AWS
Do you know about the AWS Support Knowledge Center? It contains answers to some of the most frequently asked questions and other requests asked of our support team. Many of the answers even include a short video that serves to illustrate the process or to provide additional info on the topic. For example, I recently […]
File Interface to AWS Storage Gateway
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. I should probably have a blog category for “catching up from AWS re:Invent!” Last November we made a really important addition to the AWS Storage Gateway that I was too busy to research and write about at the time. As […]
Amazon Redshift Spectrum – Exabyte-Scale In-Place Queries of S3 Data
Now that we can launch cloud-based compute and storage resources with a couple of clicks, the challenge is to use these resources to go from raw data to actionable results as quickly and efficiently as possible. Amazon Redshift allows AWS customers to build petabyte-scale data warehouses that unify data from a variety of internal and […]
S3 Storage Management Update – Analytics, Object Tagging, Inventory, and Metrics
Today I would like to tell you about four S3 features that will give you detailed insights into your storage and your access patterns. You can see what and how much you are storing, how it is being used, and you can make informed decisions about the use of S3 storage classes as a result. […]