AWS News Blog
In The Works – Amazon Aurora Serverless
You may already know about Amazon Aurora. Available in editions that are either MySQL-compatible or PostgreSQL-compatible, Aurora is fully-managed and automatically scales to up to 64 TB of database storage. When you create an Aurora Database Instance, you choose the desired instance size and have the option to increase read throughput using read replicas. If your processing needs or your query rate changes you have the option to modify the instance size or to alter the number of read replicas as needed. This model works really well in an environment where the workload is predictable, with bounds on the request rate and processing requirement.
In some cases the workloads can be intermittent and/or unpredictable, with bursts of requests that might span just a few minutes or hours per day or per week. Flash sales, infrequent or one-time events, online gaming, reporting workloads (hourly or daily), dev/test, and brand-new applications all fit the bill. Arranging to have just the right amount of capacity can be a lot work; paying for it on steady-state basis might not be sensible.
Get Ready for Amazon Aurora Serverless
Today we are launching a preview (sign up now) of Amazon Aurora Serverless. Designed for workloads that are highly variable and subject to rapid change, this new configuration allows you to pay for the database resources you use, on a second-by-second basis.
This serverless model builds on the clean separation of processing and storage that’s an intrinsic part of the Aurora architecture (read Design Considerations for High-Throughput Cloud-Native Relational Databases to learn more). Instead of choosing your database instance size up front, you create an endpoint, set the desired minimum and maximum capacity if you like, and issue queries to the endpoint. The endpoint is a simple proxy that routes your queries to a rapidly scaled fleet of database resources. This allows your connections to remain intact even as scaling operations take place behind the scenes. Scaling is rapid, with new resources coming online within 5 seconds. Here’s how it all fits together:
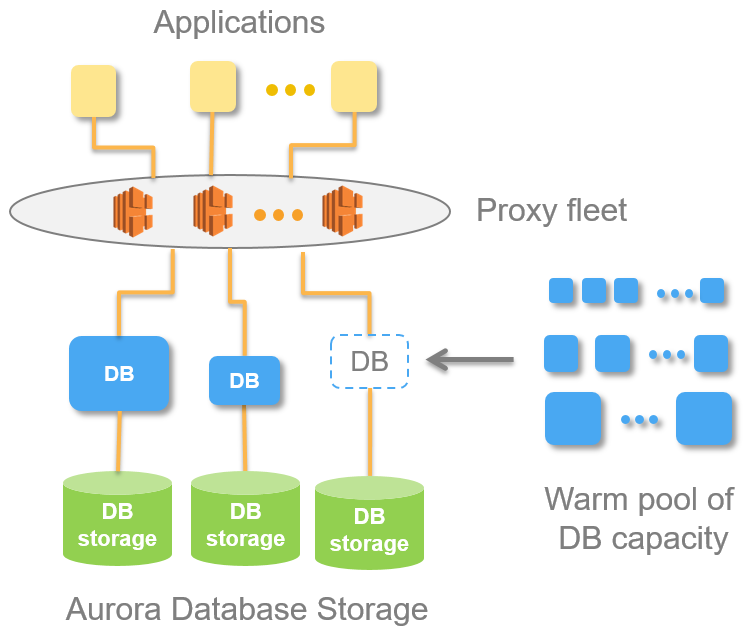
Because storage and processing are separate, you can scale all the way down to zero and pay only for storage. I think this is really cool, and I expect it to lead to the creations of new kinds of instant-on, transient applications. Scaling happens in seconds, building upon a pool of “warm” resources that are raring to go and eager to serve your requests. Special care is taken to build upon existing cached and buffered content so that newly added resources operate at full speed. You will be able to make your existing Aurora databases serverless with almost no effort.
Billing is based on Aurora Capacity Units, each representing a combination of compute power and memory. It is metered in 1-second increments, with a 1-minute minimum for each newly added resource.
Stay Tuned
I’ll be able to more information about Amazon Aurora Serverless in early 2018. Our current plan is to make it available in production form with MySQL compatibility in the first half, and to follow up with PostgreSQL compatibility later in the year. Today, you can sign up for the preview.
— Jeff;