AWS News Blog
New – Auto Recovery for Amazon EC2
An important rule when building a highly available and highly reliable system is to design for failure. In other words, your design model should assume that, as Amazon CTO Werner Vogels has said, “everything fails all the time.” Fortunately, modern data centers, networks, and servers are highly reliable, and failures are the exception rather than the rule. Nevertheless, you can build great systems if you take the occasional failure as a given and simply build a system that picks itself up and keeps going after something goes wrong.
New Auto Recovery
Today I would like to tell you about a new EC2 feature that will make it even easier for you to build systems that respond as desired when the hardware that hosts a particular EC2 instance becomes impaired. Behind the scenes, a number of system status checks (first introduced in 2012 and enhanced a couple of times since then) monitor the instance and the other components that need to be running in order for your instance to function as expected. Among other things, the checks look for loss of network connectivity, loss of system power, software issues on the physical host, and hardware issues on the physical host.
With this week’s launch, you can now arrange for automatic recovery of an EC2 instance when a system status check of the underlying hardware fails. The instance will be rebooted (on new hardware if necessary) but will retain its Instance Id, IP Address, Elastic IP Addresses, EBS Volume attachments, and other configuration details. In order for the recovery to be complete, you’ll need to make sure that the instance automatically starts up any services or applications as part of its initialization process.
Arranging for Auto Recovery
You can arrange for auto recovery of an existing instance with a couple of clicks (see the notes below for information on supported instance types and environments). Simply create a CloudWatch alarm for the metric StatusCheckFailed_System and choose the Recover this instance action.
First, find and select the metric for the instance of interest:
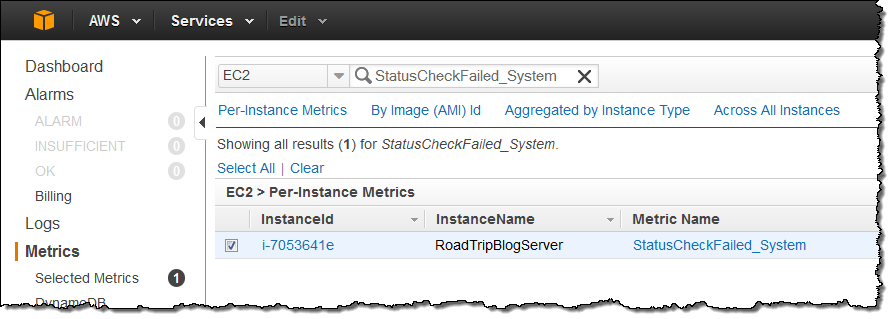
Next, click on the Create Alarm button:
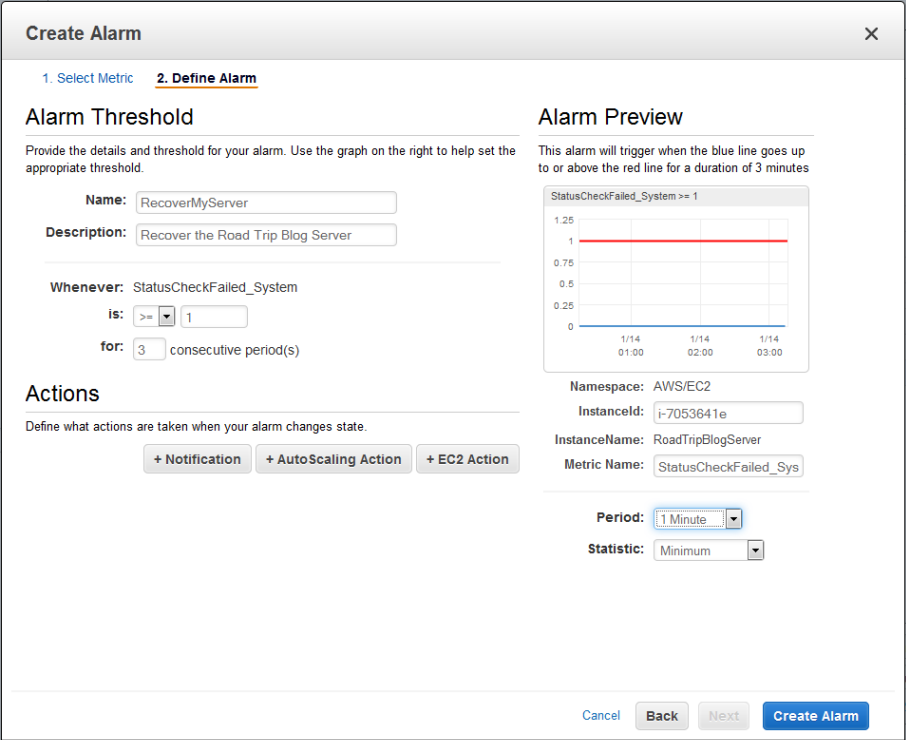
Delete the Notification action (unless you need it for some other reason) and add an EC2 action, then choose Recover this instance. Set the threshold value to be 1, set the Statistic to Minimum, and specify the number of consecutive periods to an appropriate value (two or three minutes is a good starting point, assuming that you are collecting metrics at one minute intervals):
Applicable Instance Types and Environments
This feature is currently available for the C3, C4, M3, R3, and T2 instance types running in the US East (N. Virginia) region; we plan to make it available in other regions as quickly as possible. The instances must be running within a VPC, must use EBS-backed storage, but cannot be Dedicated Instances.
There is no extra charge for the EC2 aspect of this feature. The usual CloudWatch charges apply (see the CloudWatch Pricing page for more information).
To learn more, read the Recover Your Instance documentation!
— Jeff;