AWS News Blog
Now Available – Amazon Aurora
We announced Amazon Aurora last year at AWS re:Invent (see Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon for more info). With storage replicated both within and across three Availability Zones, along with an update model driven by quorum writes, Amazon Aurora is designed to deliver high performance and 99.99% availability while easily and efficiently scaling to up to 64 TB of storage.
In the nine months since that announcement, a host of AWS customers have been putting Amazon Aurora through its paces. As they tested a wide variety of table configurations, access patterns, and queries on Amazon Aurora, they provided us with the feedback that we needed to have in order to fine-tune the service. Along the way, they verified that each Amazon Aurora instance is able to deliver on our performance target of up to 100,000 writes and 500,000 reads per second, along with a price to performance ratio that is 5 times better than previously available.
Now Available
Today I am happy to announce that Amazon Aurora is now available for use by all AWS customers, in three AWS regions. During the testing period we added some important features that will simplify your migration to Amazon Aurora. Since my original blog post provided a good introduction to many of the features and benefits of the core product, I’ll focus on the new features today.
Zero-Downtime Migration
If you are already using Amazon RDS for MySQL and want to migrate to Amazon Aurora, you can do a zero-downtime migration by taking advantage of Amazon Aurora’s new features. I will summarize the process here, but I do advise you to read the reference material below and to do a practice run first! Immediately after you migrate, you will begin to benefit from Amazon Aurora’s high throughput, security, and low cost. You will be in a position to spend less time thinking about the ins and outs of database scaling and administration, and more time to work on your application code.
If the database is active, start by enabling binary logging in the instance’s DB parameter group (see MySQL Database Log Files to learn how to do this). In certain cases, you may want to consider creating an RDS Read Replica and using it as the data source for the migration and replication (check out Replication with Amazon Aurora to learn more).
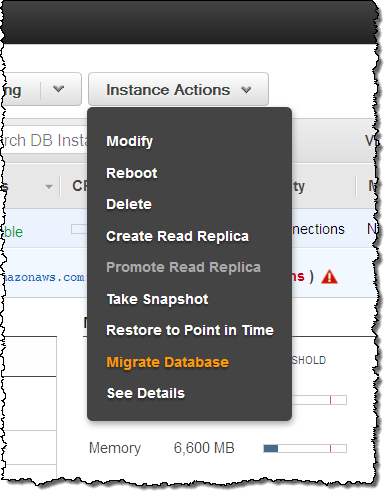
Open up the RDS Console, select your existing database instance, and choose Migrate Database from the Instance Actions menu:
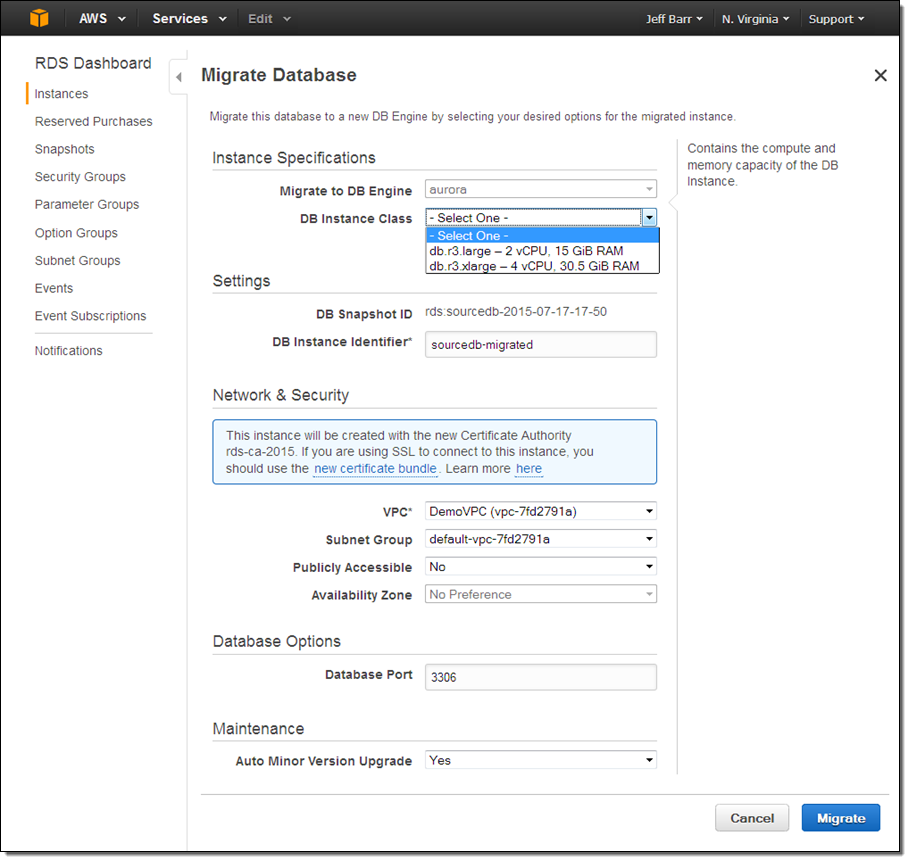
Fill in the form (in most cases you need do nothing more than choose the DB Instance Class) and click on the Migrate button:
Aurora will create a new DB instance and proceed with the migration:
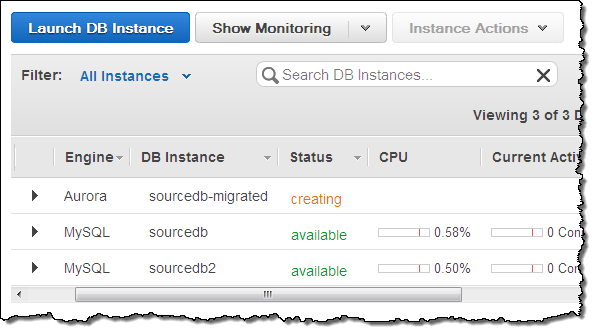
A little while later (a coffee break might be appropriate, depending on the size of your database), the Amazon Aurora instance will be available:
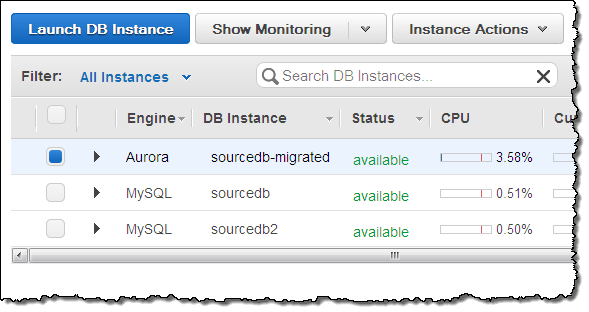
Now (assuming that the source database was actively changing) while you were creating the Amazon Aurora instance, replicate the changes to the new instance using the mysql.rds_set_external_master command, and then update your application to use the new Aurora endpoint!
Metrics Galore
Each Amazon Aurora instance reports a plethora of metrics to Amazon CloudWatch. You can view these from the Console and you can, as usual, set alarms and take actions as needed:
Easy and Fast Replication
Each Amazon Aurora instance can have up to 15 replicas, each of which adds additional read capacity. You can create a replica with a couple of clicks:
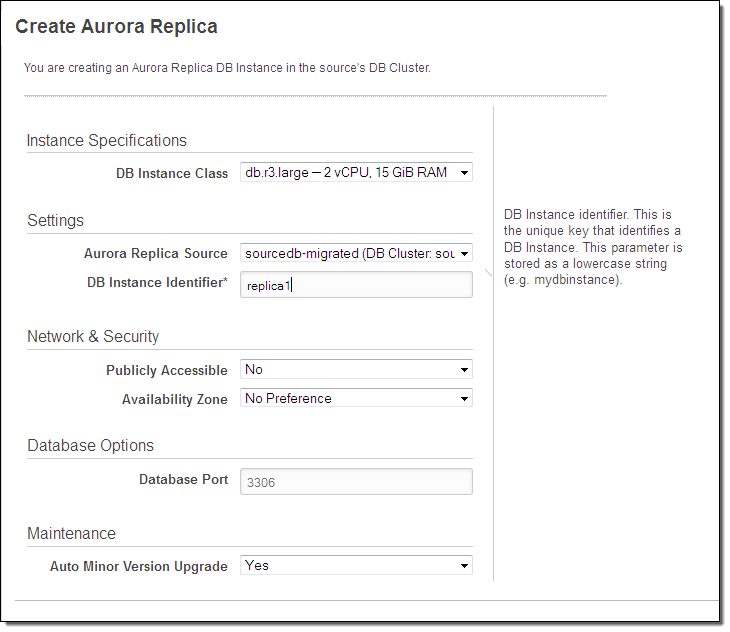
Due to Amazon Aurora’s unique storage architecture, replication lag is extremely low, typically between 10 ms and 20 ms.
5x Performance
When we first announced Amazon Aurora we expected to deliver a service that offered at least 4 times the price-performance of existing solutions. Now that we are ready to ship, I am happy to report that we’ve exceeded this goal, and that Amazon Aurora can deliver 5x the price-performance of a traditional relational database when run on the same class of hardware.
In general, this does not mean that individual queries will run 5x as fast as before (although Amazon Aurora’s fast, SSD-based storage certainly speeds things up). Instead, it means that Amazon Aurora is able to handle far more concurrent queries (both read and write) than other products. Amazon Aurora’s unique, highly parallelized access to storage reduces contention for stored data and allows it to process queries in a highly efficient fashion.
From our Partners
Members of the AWS Partner Network (APN) have been working to test their offerings and to gain operational and architectural experience with Amazon Aurora. Here’s what I know about already:
- Business Intelligence – Tableau, Zoomdata, and Looker.
- Data Integration – Talend, Attunity, and Informatica.
- Query and Monitoring – Webyog, Toad, and Navicat.
- SI and Consulting – 8K Miles, 2nd Watch, and Nordcloud.
- Content Management – Alfresco.
Ready to Roll
Our customers and partners have put Amazon Aurora to the test and it is now ready for your production workloads. We are launching in the US East (N. Virginia), US West (Oregon), and Europe (Ireland) regions, and will expand to others over time.
Pricing works like this:
- Database Instances – You pay by the hour for the primary instance and any replicas. Instances are available in 5 sizes, with 2 to 32 vCPUs and 15.25 to 244 GiB of memory. You can also use Reserved Instances to save money on your steady-state database workloads.
- Storage – You pay $0.10 per GB per month for storage, based on the actual number of bytes of storage consumed by your database, sampled hourly. For this price you get a total of six copies of your data, two copies in each of three Availability Zones.
- I/O – You pay $0.20 for every million I/O requests that your database makes.
See the Amazon Aurora Pricing page for more information.
Go For It
To learn more, visit the Amazon Aurora page and read the Amazon Aurora Documentation. You can also attend the upcoming Amazon Aurora Webinar to learn more and to see Aurora in action.
— Jeff;