AWS News Blog
Now Available – New C4 Instances

|
Late last year ago I told you about the New Compute-Optimized EC2 Instances and asked you to stay tuned for additional pricing and technical information. I am happy to announce that we are launching these instances today in seven AWS Regions!
The New C4 Instance Type
The new C4 instances are based on the Intel Xeon E5-2666 v3 (code name Haswell) processor. This custom processor, optimized for EC2, runs at a base speed of 2.9 GHz, and can achieve clock speeds as high as 3.5 GHz with Intel® Turbo Boost (complete specifications are available here). These instances are designed to deliver the highest level of processor performance on EC2. Here’s the complete lineup:
| Instance Name | vCPU Count | RAM | Network Performance | Dedicated EBS Throughput | Linux On-Demand Price |
| c4.large | 2 | 3.75 GiB | Moderate | 500 Mbps | $0.116/hour |
| c4.xlarge | 4 | 7.5 GiB | Moderate | 750 Mbps | $0.232/hour |
| c4.2xlarge | 8 | 15 GiB | High | 1,000 Mbps | $0.464/hour |
| c4.4xlarge | 16 | 30 GiB | High | 2,000 Mbps | $0.928/hour |
| c4.8xlarge | 36 | 60 GiB | 10 Gbps | 4,000 Mbps | $1.856/hour |
The prices listed above are for the US East (Northern Virginia) and US West (Oregon) regions (the instances are also available in the Europe (Ireland), Asia Pacific (Tokyo), US West (Northern California), Asia Pacific (Singapore), and Asia Pacific (Sydney) regions). For more pricing information, take a look at the EC2 Pricing page.
As I noted in my original post, EBS Optimization is enabled by default for all C4 instance sizes. This feature provides 500 Mbps to 4,000 Mbps of dedicated throughput to EBS above and beyond the general purpose network throughput provided to the instance, and is available to you at no extra charge. Like the existing C3 instances, the new C4 instances also provide Enhanced Networking for higher packet per second (PPS) performance, lower network jitter, and lower network latency. You can also run two or more C4 instances within a placement group in order to arrange for low-latency connectivity within the group.
c4.8xlarge Goodies
EC2 uses virtualization technology to provide secure compute, network, and block storage resources that are easy to manage through Web APIs. For a compute optimized instance family like C4, our goal is to provide as much of the performance of the underlying hardware as safely possible, while still providing virtualized I/O with very low jitter. We are always working to make our systems more efficient, and through that effort we are able to deliver more cores in the form of 36 vCPUs on the c4.8xlarge instance type (some operating systems have a limit of 32 vCPUs and may not be compatible with the c4.8xlarge instance type. For more information, refer to our documentation on Operating System Support).
Like earlier Intel processors, the Intel Xeon E5-2666 v3 in the C4 instances support Turbo Boost. This technology allows the processor to run faster than the rated speed (2.9 GHz) as long as it stays within its design limits for power consumption and heat generation. The effect depends on the number of cores in use and the exact workload, and can boost the clock speed to as high as 3.5 GHz under optimal conditions. In general, workloads that use just a few cores are the most likely to benefit from this speedup. Turbo Boost is enabled by default and your applications can benefit from it with no effort on your part.
Here’s an inside look at an actual Haswell micro architecture die (this photo is of a version of the die that is similar to, but not an exact match for, the one used in the C4 instances). The cache is in the middle, flanked to the top and the bottom by the CPU cores:
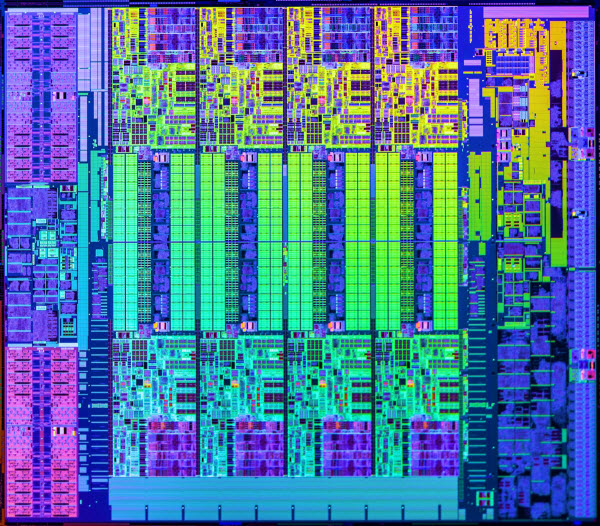
If your workload is able to take advantage of all of those cores, you’ll get the rated 2.9 GHz speed, with help from Turbo Boost whenever the processor decides that it is able to raise the clock speed without exceeding any of the processor’s design limits for heat generation and dissipation.
In some cases, your workload might not need all 18 of the cores (each of which runs two hyperthreads, for a total of 36 vCPUs on c4.8xlarge). To tune your application for better performance, you can manage the power consumption on a per-core basis. This is known as C-state management, and gives you control over the sleep level that a core may enter when idle. Let’s say that your code needs just two cores. Your operating system can set the other 16 cores to a state that draws little or no power, thereby creating some thermal headroom that will give the remaining cores an opportunity to Turbo Boost. You also have control over the desired performance (CPU clock frequency); this is known as P-state management. You should consider changing C-state settings to decrease CPU latency variability (cores in a sleep state consume less power, but deeper sleep states require longer to become active when needed) and consider changing P-state settings to adjust the variability in CPU frequency in order to best meet the needs of your application. Please note that C-state and P-state management requires operating system support and is currently available only when running Linux.
You can use the turbostat command (available on the Amazon Linux AMI) to display the processor frequency and C-state information.
Helpful resources for C-State and P-State management include Jeremy Eder’s post on processor.max_cstate, intel_idle.max_cstate and /dev/cpu_dma_latency, Dell’s technical white paper, Controlling Processor C-State Usage in Linux, and the discussion of Are hardware power management features causing latency spikes in my application? You should also read our new documentation on Processor State Control.
Intel® Xeon® Processor (E5-2666 v3) in Depth
The Intel Haswell micro architecture is a notable improvement on its predecessors. It is better at predicting branches and more efficient at prefetching instructions and data. It can also do a better job of taking advantage of opportunities to execute multiple instructions in parallel. This improves performance on integer math and on branches. This new processor also incorporates Intel’s Advanced Vector Extensions 2. AVX2 supports 256-bit integer vectors and can process 32 single precision or 16 double precision floating point operations per cycle. It also supports instructions for packing and extracting bit fields, decoding variable-length bit streams, gathering bits, arbitrary precision arithmetic, endian conversion, hashing, and cryptography. The AVX2 instructions and the updated microarchitecture can double the floating-point performance for compute-intensive workloads. The improvements to the microarchitecture can boost the performance of existing applications by 30% or more. In order to take advantage of these new features, you will need to use a development toolchain that knows how to generate code that makes use of these new instructions; see the Intel Developer Zone article, Write your First Program with Haswell new Instructions for more info.
Launch a C4 Instance Today
As I noted earlier, the new C4 instances are available today in seven AWS regions (and coming soon to the others). You can launch them as On-Demand, purchase Reserved Instances, and you can also access them via the Spot Market. You can also launch applications from the AWS Marketplace on C4 instances in any Region where they are supported.
We are always interested in hearing from our customers. If you have feedback on the C4 instance type and would like to share it with us, please send it to ec2-c4-feedback@amazon.com.
— Jeff;