AWS News Blog
Quickly Filter Data in Amazon Redshift Using Interleaved Sorting
My colleague Tina Adams sent a guest post to introduce another cool and powerful feature for Amazon Redshift.
— Jeff;
Amazon Redshift, our fully managed data warehouse service, makes it fast and easy to analyze all your data. You can get started with a 160GB cluster for free for 2 months, and scale to a couple of petabytes for less than $1,000/TB/Year. Amazon Redshift uses a massively parallel processing, scale-out architecture to ensure compute resources grow with your data set size, and columnar, direct-attached storage to dramatically reduce I/O time. Many of our customers, including Pinterest, Euclid, Accordant Media, Asana and Coursera, have seen significant performance improvements with Amazon Redshift.
Reducing I/O is critical to improving data warehouse query performance. One way Amazon Redshift improves I/O performance is by using sorted tables to restrict the range of values that need to be scanned. When you sort a table, we use zone maps (cached in memory) to skip 1 MB blocks without relevant data. For example, if a table has five years of data sorted by date, 98% of the blocks can be eliminated when you query for a particular month.
But what if you need to filter by a column that is not in the sort key? Row-based systems deal with this by creating secondary indices to reduce the number of blocks accessed when filtering on a non-primary key column. Indices are less selective for columnar databases with larger block sizes. Instead, columnar systems often create projections, which are copies of the underlying table sorted in different ways. However, both indices and projections can require significant overhead. You have to maintain not only data you’re loading, but also indices and projections on top of that data. For example, with 3 projections, it may take 2-3 times longer to load your data. What’s more, the number of possible projections increases exponentially with the number of columns. With eight columns, you can have up to 40K possible projections.
New Interleaved Sort Keys
For fast filter queries without the need for indices or projections, Amazon Redshift now supports Interleaved Sort Keys, which will be deployed in every region over the next seven days. A table with interleaved keys arranges your data so each sort key column has equal importance. Interleaved sorts are most effective with highly selective queries that filter on multiple columns. Let’s say you have a table with 100,000 1 MB blocks per column, and you often filter on one or more of four columns (date, customer, product, geography). You can create a compound sort key, sorting first by date, then customer, product, and finally geography. This will work well if your query filters on date, but can require a table scan of all 100,000 blocks if you only filter by geographic region. Interleaved sorting provides fast filtering, no matter which sort key columns you specify in your WHERE clause. If you filter by any one of the four sort key columns, you scan 5,600 blocks, or 100,000(3/4). If you filter by two columns, you reduce the scan to 316 blocks or 100,000(2/4). Finally, if you filter on all four sort keys, you scan a single block.
Sound like magic? No, it’s just math. Let’s walk through another example. Imagine you run a website and want to analyze your top webpages and customers. You have two sort keys (customer ID and page ID) and data split across four blocks. How do you achieve fast analytics across both webpages and customers? You can choose to sort your data by customer ID and then by page ID via a compound sort key (the notation [1, 1] means that customer 1 viewed page 1):

This means pages viewed by a given customer are stored in the same block (orange rectangle). While you only need to scan one block to return the page views of a particular customer, you must scan all four blocks to return all customers that viewed a given page.
Alternatively, if you create an interleaved sort, both customer and page are treated the same:
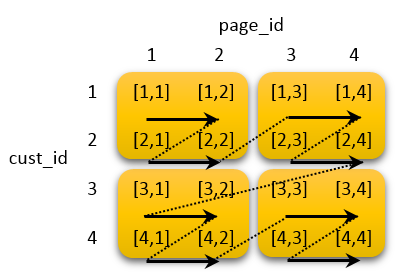
As you can see, the first two customer IDs are stored in the first block, along with the first two page IDs (arrows indicate the sort order). Therefore, you only scan 2 blocks to return data on a given customer or a given webpage.
The performance benefit of interleaved sorting increases with table size. If your table contains 1,000,000 blocks (1 TB per column) with an interleaved sort key of both customer ID and page ID, you scan 1,000 blocks when you filter on a specific customer or page, a speedup of 1000x compared to the unsorted case.
To create an interleaved sort, simply define your sort keys as INTERLEAVED in your CREATE TABLE statement, as shown below. You can specify up to eight sort keys.
CREATE TABLE PageViews (customerID INTEGER, pageURL VARCHAR(300), duration INTEGER)
INTERLEAVED SORTKEY (pageURL, customerID);
When we tuned a 45,000,000 row dataset with interleaved sort keys, queries on a subset of the sort columns ran 12x faster on average compared to using compound sort keys, as shown below.
SELECT COUNT(DISTINCT pageURL) FROM PageViews WHERE customerID = 57285;
Run time...
Compound Sort: 21.7 sec
Interleaved Sort: 1.7 sec
Interleaved sorting can even be useful for single-column keys. Our zone maps store the first eight bytes of sort key column values. When we generate a zone map on the pageURL column above using compound sort keys, the leading eight bytes would only cover “http://w”, which is not very selective. However, interleaved sorting compresses the key column, allowing 264 distinct URLs to fit in the zone map.
There are tradeoffs between using compound and interleaved sort keys. If the columns you query are always the same, you may be better off using compound sort keys. In the example above, a query filtering on the leading sort column, pageURL, runs 0.4 seconds faster using compound sort keys vs. interleaved sorting. This is not surprising, since compound keys favor leading columns. Depending on the nature of the dataset, vacuum time overheads can increase by 10-50% for interleaved sort keys vs. compound keys. If you have data that increases monotonically, such as dates, your interleaved sort order will skew over time, requiring you to run a vacuum operation to re-analyze the distribution and re-sort the data.
The interleaved sorting feature will be deployed in every region over the next seven days. The new cluster version will be 1.0.921.
Learn More
Our tutorial on Optimizing for Star Schemas with Amazon Redshift goes over how to make these trade-offs in more detail. APN business intelligence partner Looker has also written a great blog post about the performance benefits of interleaved sorting. For more information on defining sort keys, please review our documentation on Best Practices for Designing Tables. We’d also appreciate your feedback at redshift-feedback@amazon.com.
Stay Tuned
There’s more to come from Amazon Redshift, so stay tuned. To get the latest feature announcements, log in to the Amazon Redshift Forum and subscribe to the Amazon Redshift Announcements thread. Or use the Developer Guide History and the Management Guide History to track product updates.
— Tina Adams, Senior Product Manager