AWS News Blog
Vector search for Amazon DocumentDB (with MongoDB compatibility) is now generally available

|
Today, we are announcing the general availability of vector search for Amazon DocumentDB (with MongoDB compatibility), a new built-in capability that lets you store, index, and search millions of vectors with millisecond response times within your document database.
Vector search is an emerging technique used in machine learning (ML) to find similar data points to given data by comparing their vector representations using distance or similarity metrics. Vectors are numerical representation of unstructured data created from large language models (LLM) hosted in Amazon Bedrock, Amazon SageMaker, and other open source or proprietary ML services. This approach is useful in creating generative artificial intelligence (AI) applications, such as intuitive search, product recommendation, personalization, and chatbots using Retrieval Augmented Generation (RAG) model approach. For example, if your data set contained individual documents for movies, you could semantically search for movies similar to Titanic based on shared context such as “boats”, “tragedy”, or “movies based on true stories” instead of simply matching keywords.
With vector search for Amazon DocumentDB, you can effectively search the database based on nuanced meaning and context without spending time and cost to manage a separate vector database infrastructure. You also benefit from the fully managed, scalable, secure, and highly available JSON-based document database that Amazon DocumentDB provides.
Getting started with vector search on Amazon DocumentDB
The vector search feature is available on your Amazon DocumentDB 5.0 instance-based clusters. To implement a vector search application, you generate vectors using embedding models for fields inside your document and store vectors side by side your source data inside Amazon DocumentDB.
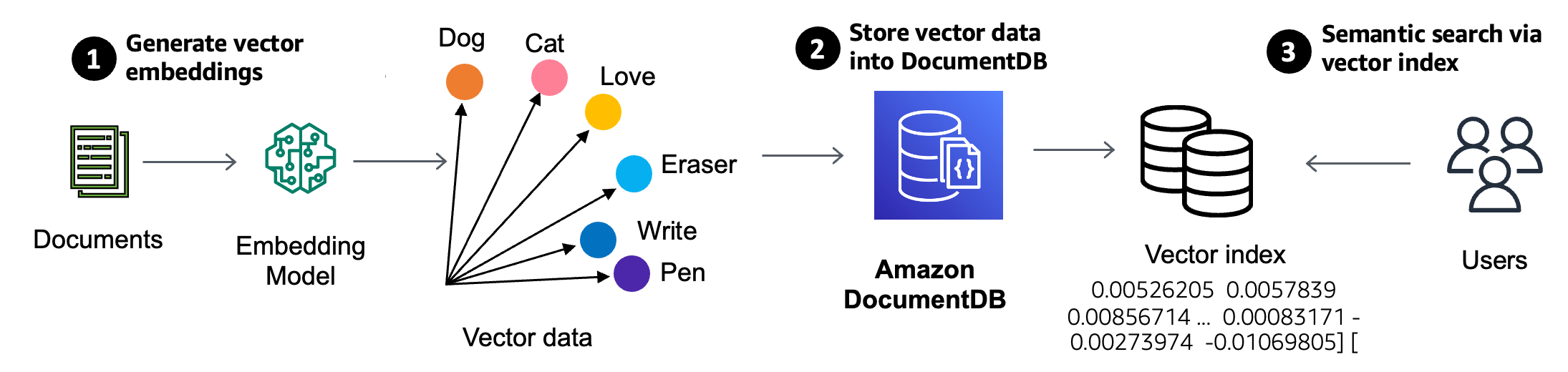
Next, you create a vector index on a vector field that will help retrieve similar vectors and can search the Amazon DocumentDB database using semantic search. Finally, user-submitted queries are converted to vectors using the same embedding model to get semantically similar documents and return them to the client.
Let’s look at how to implement a simple semantic search application using vector search on Amazon DocumentDB.
Step 1. Create vector embeddings using the Amazon Titan Embeddings model
Let’s use the Amazon Titan Embeddings model to create an embedding vector. Amazon Titan Embeddings model is available in Amazon Bedrock, a serverless generative AI service. You can easily access it using a single API and without managing any infrastructure.
prompt = "I love dog and cat."
response = bedrock_runtime.invoke_model(
body= json.dumps({"inputText": prompt}),
modelId='amazon.titan-embed-text-v1',
accept='application/json',
contentType='application/json'
)
response_body = json.loads(response['body'].read())
embedding = response_body.get('embedding')The returned vector embedding will look similar to this:
[0.82421875, -0.6953125, -0.115722656, 0.87890625, 0.05883789, -0.020385742, 0.32421875, -0.00078201294, -0.40234375, 0.44140625, ...]
Step 2. Insert vector embeddings and create a vector index
You can add generated vector embeddings using the insertMany( [{},...,{}] ) operation with a list of the documents that you want added to your collection in Amazon DocumentDB.
db.collection.insertMany([
{sentence: "I love a dog and cat.", vectorField: [0.82421875, -0.6953125,...]},
{sentence: "My dog is very cute.", vectorField: [0.05883789, -0.020385742,...]},
{sentence: "I write with a pen.", vectorField: [-0.020385742, 0.32421875,...]},
...
]);
You can create a vector index using the createIndex command. Amazon DocumentDB performs an approximate nearest neighbor (ANN) search using the inverted file with flat compression (IVFFLAT) vector index. The feature supports three distance metrics: euclidean, cosine, and inner product. We will use the euclidean distance, a measure of the straight-line distance between two points in space. The smaller the euclidean distance, the closer the vectors are to each other.
db.collection.createIndex (
{ vectorField: "vector" },
{ "name": "index name",
"vectorOptions": {
"dimensions": 100, // the number of vector data dimensions
"similarity": "euclidean", // Or cosine and dotProduct
"lists": 100
}
}
);Step 3. Search vector embeddings from Amazon DocumentDB
You can now search for similar vectors within your documents using a new aggregation pipeline operator within $search. The example code to search “I like pets” is as follows:
db.collection.aggregate ({
$search: {
"vectorSearch": {
"vector": [0.82421875, -0.6953125,...], // Search for ‘I like pets’
"path": vectorField,
"k": 5,
"similarity": "euclidean", // Or cosine and dotProduct
"probes": 1 // the number of clusters for vector search
}
}
});This returns search results such as “I love a dog and cat.” which is semantically similar.
To learn more, see Amazon DocumentDB documentation. To see a more practical example—a semantic movie search with Amazon DocumentDB—find the Python source codes and data-sets in the GitHub repository.
Now available
Vector search for Amazon DocumentDB is now available at no additional cost to all customers using Amazon DocumentDB 5.0 instance-based clusters in all AWS Regions where Amazon DocumentDB is available. Standard compute, I/O, storage, and backup charges will apply as you store, index, and search vector embeddings on Amazon DocumentDB.
To learn more, see the Amazon DocumentDB documentation and send feedback to AWS re:Post for Amazon DocumentDB or through your usual AWS Support contacts.
— Channy