AWS Big Data Blog
Analyze Amazon Ion datasets using Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Amazon Ion is a richly typed, self-describing, hierarchical data serialization format offering interchangeable binary and text representations. The text format extends JSON (meaning all JSON files are valid Ion files), and is easy to read and author, supporting rapid prototyping. The binary representation is efficient to store, transmit, and skip-scan parse. The rich type system provides unambiguous semantics for long-term preservation of data that can survive multiple generations of software evolution.
Athena now supports querying and writing data in Ion format. The Ion format is currently used by internal Amazon teams, by external services such as Amazon Quantum Ledger Database (Amazon QLDB) and Amazon DynamoDB (which can be exported into Ion), and in the open-source SQL query language PartiQL.
In this post, we discuss use cases and the unique features Ion offers, followed by examples of querying Ion with Athena. For demonstration purposes, we use the transformed version of the City Lots San Francisco dataset.
Features of Ion
In this section, we discuss some of the unique features that Ion offers:
- Type system
- Dual format
- Efficiency gains
- Skip scanning
Type system
Ion extends JSON, adding support for more precise data types to improve interpretability, simplify processing, and avoid rounding errors. These high precision numeric types are essential for financial services, where fractions of a cent on every transaction add up. Data types that are added are arbitrary-size integers, binary floating-point numbers, infinite-precision decimals, timestamps, CLOBS, and BLOBS.
Dual format
Users can be presented with a familiar text-based representation while benefiting from the performance efficiencies of a binary format. The interoperability between the two formats enables you to rapidly discover, digest, and interpret data in a familiar JSON-like representation, while underlying applications benefit from a reduction in storage, memory, network bandwidth, and latency from the binary format. This means you can write plain text queries that run against both text-based and binary-based Ion. You can rewrite parts of your data in text-based Ion when you need human readable data during development and switch to binary in production.
When debugging a process, the ability for systems engineers to locate data and understand it as quickly as possible is vital. Ion provides mechanisms to move between binary and a text-based representation, optimizing for both the human and the machine. Athena supports querying and writing data in both of these Ion formats. The following is an example Ion text document taken from the transformed version of the citylots dataset:
Efficiency gains
Binary-encoded Ion reduces file size by moving repeated values, such as field names, into a symbol table. Symbol tables reduce CPU and read latency by limiting the validation of character encoding to the single instance of the value in the symbol table.
For example, a company that operates at Amazon’s scale can produce large volumes of application logs. When compressing Ion and JSON logs, we noticed approximately 35% less CPU time to compress the log, which produced an average of roughly 26% smaller files. Log files are critical when needed but costly to retain, so the reduction in file sizes combined with the read performance gains from symbol tables helps when handling these logs. The following is an example of file size reduction with the citylots JSON dataset when converted to Ion binary with GZIP and ZSTD compression:
Skip-scanning
In a textual format, every byte must be read and interpreted, but because Ion’s binary format is a TLV (type-length-value) encoding, an application may skip over elements that aren’t needed. This reduces query and application processing costs correlated with the proportion of unexamined fields.
For example, forensic analysis of application log data involves reading large volumes of data where only a fraction of the data is needed for diagnosis. In these scenarios, skip-scanning allows the binary Ion reader to move past irrelevant fields without the cost of reading the element stored within a field. This results in users experiencing lower resource usage and quicker response times.
Query Ion datasets using Athena
Athena now supports querying and creating Ion-formatted datasets via an Ion-specific SerDe, which in conjunction with IonInputFormat and IonOutputFormat allows you to read and write valid Ion data. Deserialization allows you to run SELECT queries on the Ion data so that it can be queried to gain insights. Serialization through CTAS or INSERT INTO queries allows you to copy datasets from existing tables’ values or generate new data in the Ion format.
The interchangeable nature of Ion text and Ion binary means that Athena can read datasets that contain both types of files. Because Ion is a superset of JSON, a table using the Ion SerDe can also include JSON files. Unlike the JSON SerDe, where every new line character indicates a new row, the Ion SerDe uses a combination of closing brackets and new line characters to determine new rows. This means that if each JSON record in your source documents isn’t on a single line, these files can now be read in Athena via the Ion SerDe.
Create external tables
Athena supports querying Ion-based datasets by defining AWS Glue tables with the user-defined metadata. Let’s start with an example of creating an external table for a dataset stored in Ion text. The following is a sample row from the citylots dataset:
To create an external table that has its data stored in Ion, you have two syntactic options.
First, you can specify STORED AS ION. This is a more concise method, and is best used for simple cases, when no additional properties are required. See the following code:
Alternatively, you can explicitly specify the Ion classpaths in ROW FORMAT SERDE, INPUTFORMAT, and OUTPUTFORMAT. Unlike the first method, you can specify a SERDEPROPERTIES clause here. In our example DDL, we added a SerDe property that allows values that are outside of the Hive data type ranges to overflow rather than fail the query:
Athena converts STORED AS ION into the explicit classpaths, so both tables look similar in the metastore. If we look in AWS Glue, we see both tables we just created have the same input format, output format, and SerDe serialization library.

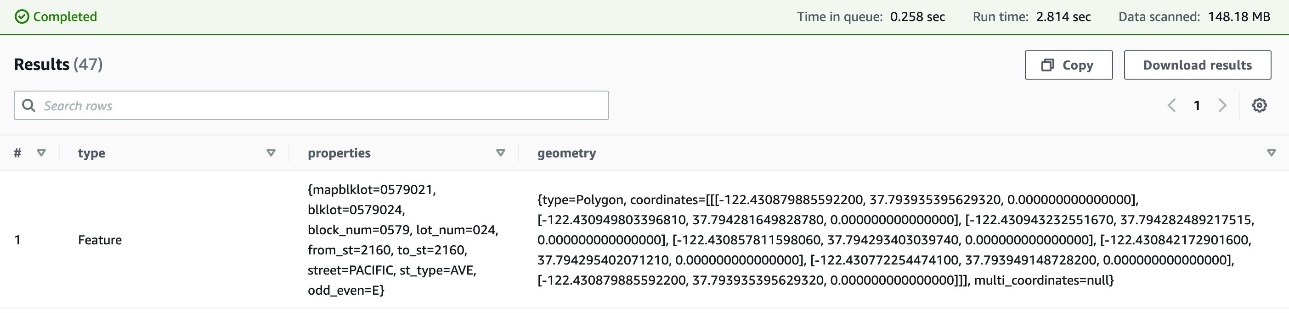
Now that our table is created, we can run standard SELECT queries on the city_lots_ion table. Let’s run a query that specifies the block_num from our example row of Ion data to verify that we can read from the table:
The following screenshot shows our results.
Use path extraction to read from specific fields
Athena supports further customization of how data is interpreted via SerDe properties. To specify these, you can add a WITH SERDEPROPERTIES clause, which is a subfield of the ROW FORMAT SERDE field.
In some situations, we may only care about some parts of the information. Let’s suppose we don’t want any of the geometry info from the citylots dataset, and only need a few of the fields in properties. One solution is to specify a search path using the path extractor SerDe property:
Path extractors are search paths that Athena uses to map the table columns to locations in the individual document. Full information on what can be done with path extractors is available on GitHub, but for our example, we focus on creating simple paths that use the names of each field as an index. In this case, the search path takes the form of a space-delimited set of indexes (and wraps it with parentheses) that indicate the location of each desired piece of information. We map the search paths to table columns by using the path extractor property.
By default, Athena builds path extractors dynamically based on column names unless overridden. This means that when we run our SELECT query on our city_lots_ion1 table, Athena builds the following search paths:
Assuming we only care about the block and lot information from the properties struct, and the geometry type from the geometry struct, we can build search paths that map the desired fields from the row of data to table columns. First let’s build the search paths:
Now let’s map these search paths to table columns using the path extractor SerDe property. Because the search paths specify where to look for data, we are able to flatten and rename our datasets to better serve our purpose. For this example, let’s rename the mapblklot field to map_block_lot, blklot to block_lot, and the geometry type to shape:
Let’s put all of this together and create the city_blocks table:
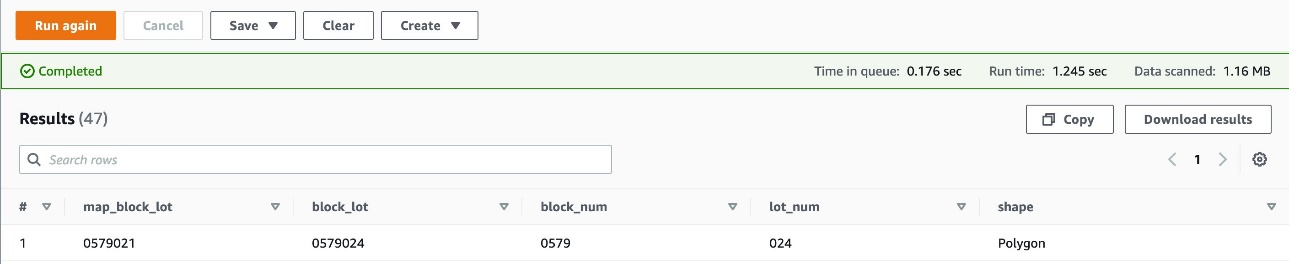
Now we can run a select query on the city_blocks table, and see the results:

Utilizing search paths in this way enables skip-scan parsing when reading from Ion binary files, which allows Athena to skip over the unneeded fields and reduces the overall time it takes to run the query.
Use CTAS and UNLOAD for data transformation
Athena supports CREATE TABLE AS SELECT (CTAS), which creates a new table in Athena from the results of a SELECT statement from another query. Athena also supports UNLOAD, which writes query results to Amazon S3 from a SELECT statement to the specified data format.
Both CTAS and UNLOAD have a property to specify a format and a compression type. This allows you to easily convert Ion datasets to other data formats, such as Parquet or ORC, and vice versa, without needing to set up a complex extract, transform, and load (ETL) job. This is beneficial for situations when you want to transform your data, or know you will run repeated queries on a subset of your data and want to use some of the benefits inherent to columnar formats. Combining it with path extractors is especially helpful, because we’re only storing the data that we need in the new format.
Let’s use CTAS to convert our city_blocks table from Ion to Parquet, and compress it via GZIP. Because we have path extractors set up for the city_blocks table, we only need to convert a small portion of the original dataset:
We can now run queries against the city_block_parquet_gzip table, and should see the same result. To test this out, let’s run the same SELECT query we ran before on the Parquet table:
When converting tables from another format to Ion, Athena supports the following compression codecs: ZSTD, BZIP2, GZIP, SNAPPY, and NONE. In addition to adding Ion as a new format for CTAS, we added the ion_encoding property, which allows you to choose whether the output files are created in Ion text or Ion binary. This allows for serialization of data from other formats back into Ion.
Let’s convert the original city_lots JSON file back to Ion, but this time we specify that we want to use ZSTD compression and a binary encoding.
The JSON file can be found at following location: s3://aws-bigdata-blog/artifacts/athena-ion-blog/city_lots_json/
Because Ion is a superset of JSON, we can use the Ion SerDe to read this file:
Now let’s copy this table into our desired Ion binary form:
Finally, let’s run our verification SELECT statement to verify everything was created properly:

Use UNLOAD to store Ion data in Amazon S3
Sometimes we just want to reformat the data and don’t need to store the additional metadata to query the table. In this case, we can use UNLOAD, which stores the results of the query in the specified format in an S3 bucket.
Let’s test it out, using UNLOAD to convert the drivers_names table from Ion to ORC, compress it via ZLIB, and store it to an S3 bucket:
When you check in Amazon S3, you can find a new file in the ORC format.
Conclusion
This post talked about the new feature in Athena that allows you to query and create Ion datasets using standard SQL. We discussed use cases and unique features of the Ion format like type system, dual formats (Ion text and Ion binary), efficiency gains, and skip-scanning. You can get started with querying an Ion dataset stored in Amazon S3 by simply creating a table in Athena, and also converting existing datasets to Ion format and vice versa using CTAS and UNLOAD statements.
To learn more about querying Ion using Athena, refer to Amazon Ion Hive SerDe.
References
- Name of Dataset: City Lots San Francisco in .json
- Licenses and Notes: OG dataset under PDDL 1.0; Github .json version under MIT style license
- Link(s) to Dataset(s) (note – original dataset is NLA from DataSF)
- Location of transformed version
About the Authors
 Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
 Jacob Stein works on the Amazon Athena team as a Software Development Engineer. He led the project to add support for Ion in Athena. He loves working on technical problems unique to internet scale data, and is passionate about developing scalable solutions for distributed systems.
Jacob Stein works on the Amazon Athena team as a Software Development Engineer. He led the project to add support for Ion in Athena. He loves working on technical problems unique to internet scale data, and is passionate about developing scalable solutions for distributed systems.
 Giovanni Matteo Fumarola is the Engineering Manager of the Athena Data Lake and Storage team. He is an Apache Hadoop Committer and PMC member. He has been focusing in the big data analytics space since 2013.
Giovanni Matteo Fumarola is the Engineering Manager of the Athena Data Lake and Storage team. He is an Apache Hadoop Committer and PMC member. He has been focusing in the big data analytics space since 2013.
 Pete Ford is a Sr. Technical Program Manager at Amazon.
Pete Ford is a Sr. Technical Program Manager at Amazon.