AWS Big Data Blog
Announcing Amazon Redshift data sharing (preview)
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to 3x better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as high-performance business intelligence (BI) reporting, dashboarding applications, data exploration, and real-time analytics.
We’re excited to launch the new Amazon Redshift data sharing capability, which enables you to securely and easily share live data across Amazon Redshift clusters. Data sharing allows you to extend the ease of use, performance, and cost benefits that Amazon Redshift offers in a single cluster to multi-cluster deployments while being able to share data. Data sharing enables instant, granular, and high-performance data access across Amazon Redshift clusters without the need to copy or move it. Data sharing provides live access to data so that your users always see the most up-to-date and consistent information as it’s updated in the data warehouse. There is no additional cost to use data sharing on your Amazon Redshift clusters.
In this post, we discuss the needs for data sharing in organizations, current challenges when it comes to sharing data, and how Amazon Redshift data sharing addresses these needs.
Need for sharing data in organizations and current challenges
We hear from our customers that they want to share data at many levels to enable broad and deep insights but also minimize complexity and cost. For example, data needs to be shared from a central data warehouse that loads and transforms constant streams of updates with BI and analytics clusters that serve a variety of workloads, such as dashboarding applications, ad-hoc queries, and data science. Multiple teams and business groups within an organization want to share and collaborate on data to gain differentiated insights that can help unlock new market opportunities, or analyze cross-group impact. As data becomes more valuable, many organizations are becoming data providers too and want to share data across organizations and offer analytics services to external consumers.
Before the launch of Amazon Redshift data sharing, in order to share data, you needed to unload data from one system (the producer) and copy it into another (the consumer). This approach can be expensive and introduce delays, especially as the number of consumers grow. It requires building and maintaining separate extract, transform, and load (ETL) jobs to provide relevant subsets of the data for each consumer. The complexity increases with the security practices that must be kept in place to regularly monitor business-critical data usage and ensure compliance. Additionally, this way of sharing doesn’t provide users with complete and up-to-date views of the data and limits insights. Organizations want a simple and secure way to share fresh, complete, and consistent views of data with any number of consumers.
Introduction to Amazon Redshift data sharing
Amazon Redshift data sharing allows you to securely and easily share data for read purposes across different Amazon Redshift clusters without the complexity and delays associated with data copies and data movement. Data can be shared at many levels, including schemas, tables, views, and user-defined functions, providing fine-grained access controls that can be tailored for different users and businesses that all need access to the data.
Consumers can discover shared data using standard SQL interfaces and query it with high performance from familiar BI and analytics tools. Users connect to an Amazon Redshift database in their cluster, and can perform queries by referring to objects from any other Amazon Redshift database that they have permissions to access, including the databases shared from remote clusters. Amazon Redshift enables sharing live and transactionally consistent views of the data, meaning that consumers always view the most up-to-date data, even when it’s continuously updated on the producer clusters. Amazon Redshift clusters that share data can be in the same or different AWS accounts, making it possible for you to share data across organizations and collaborate with external parties in a secure and governed manner. Amazon Redshift offers comprehensive auditing capabilities using system tables and AWS CloudTrail to allow you to monitor the data sharing permissions and the usage across all the consumers and revoke access instantly, when necessary.
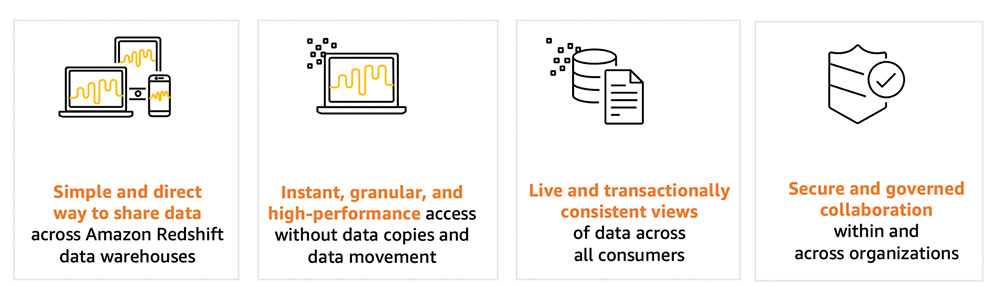
Data sharing provides high-performance access and workload isolation
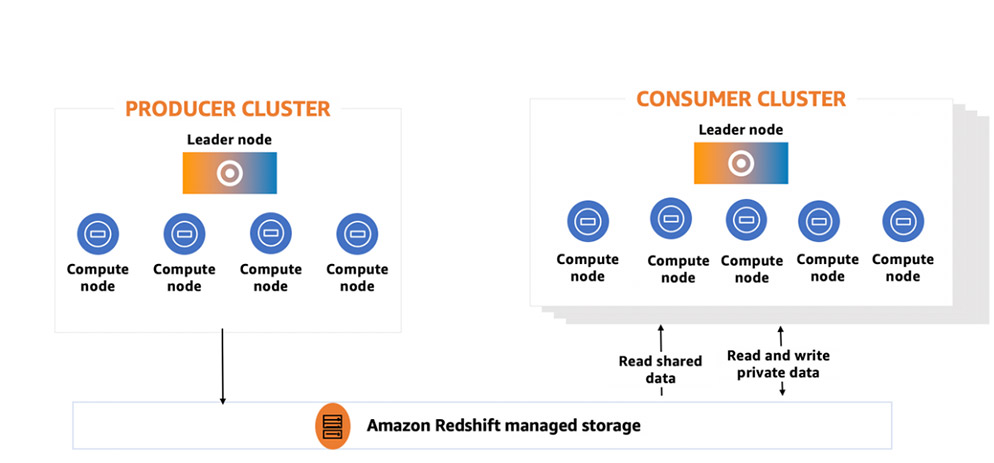
Data sharing builds on Amazon Redshift RA3 managed storage, which decouples storage and compute, allowing either of them to scale independently. With data sharing, workloads accessing shared data are isolated from each other. Queries accessing shared data run on the consumer cluster and read data from the Amazon Redshift managed storage layer directly without impacting the performance of the producer cluster.
You can now rapidly onboard any number of workloads with diverse data access patterns and SLA requirements and not be concerned about resource contention. Workloads accessing shared data can be provisioned with flexible compute resources that meet their workload-specific price performance requirements and be scaled independently as needed in a self-service fashion. You can optionally allow these teams and business groups to pay for what they use with charge-back. With data sharing, the producer cluster pays for the managed storage cost of the shared data, and the consumer cluster pays for the compute. Data sharing itself doesn’t have any cost associated with it.
Consumer clusters are regular Amazon Redshift clusters. Although consumer clusters can only read the shared data, they can write their own private data and if desired, share it with other clusters, including back to the producer cluster. Building on a managed storage foundation also enables high-performance access to the data. The frequently accessed datasets are cached on the local compute nodes of the consumer cluster to speed up those queries. The following diagram illustrates this data sharing architecture.
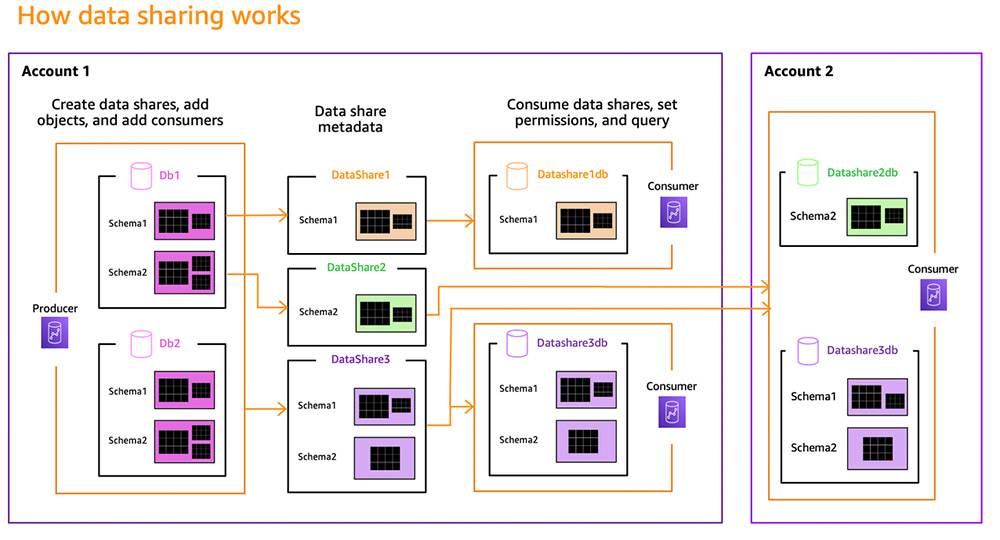
How data sharing works
Data sharing between Amazon Redshift clusters is a two-step process. First, the administrator of the producer cluster that wants to share data creates a data share, a new named object that serves as a unit of sharing. The administrator of the producer cluster and other privileged users add the needed database objects such as schemas, tables, views (regular, late binding, and materialized) to the data share and specify a list of consumers for sharing purposes. Consumers can be other Amazon Redshift clusters in the same AWS account or separate AWS accounts.
Next, the administrator of the consumer cluster looks at the shared datasets and reviews the contents of each share. To consume shared data, the consumer cluster administrator creates an Amazon Redshift database from the data share object and assigns permissions to appropriate users and groups in the consumer cluster. Users and groups that have access to shared data can discover and query it using standard SQL and analytics tools. You can join shared data with local data and perform cross-database queries. We have introduced new metadata views and modified JDBC/ODBC drivers so that tools can seamlessly integrate with shared data. The following diagram illustrates this data sharing architecture.
Data sharing use cases
In this section, we discuss the common data sharing use cases:
- Sharing data from a central ETL cluster with multiple, isolated BI and analytics clusters in a hub-spoke architecture to provide read workload isolation and optional charge-back for costs.

- Sharing data among multiple business groups so they can collaborate for broader analytics and data science. Each Amazon Redshift cluster can be a producer of some data but also can be a consumer of other datasets.

- Sharing data in order to offer data and analytics as a service across the organization and with external parties.

- Sharing data between development, test, and production environments, at any granularity.

Amazon Redshift offers unparalleled compute flexibility
Amazon Redshift offers you the most flexibility than any other cloud data warehouse when it comes to organizing your workloads based on price performance, isolation, and charge-ability. Amazon Redshift efficiently utilizes compute resources in a cluster to maximize performance and throughput with automatic workload management (WLM). Specifying query priorities allows you to influence the usage of resources across multiple workloads based on business priorities. With Amazon Redshift concurrency scaling, you can elastically scale one or more workloads in a cluster automatically with extra capacity to handle high concurrency and query spikes without any application changes. And with data sharing, you can now handle diverse business-critical workloads that need flexible compute resources, isolation, and charge-ability with multi-cluster deployments while sharing data. You can use WLM and concurrency scaling on both data sharing producer and consumer clusters.
The combination of these capabilities allows you to evolve from single cluster to multi-cluster deployments easily and cost-efficiently.
Beyond sharing data across Amazon Redshift clusters
Along with sharing data across Amazon Redshift clusters, our vision is to evolve data sharing so you can share Amazon Redshift data with the Amazon Simple Storage Service (Amazon S3) data lake by publishing data shares to the AWS Lake Formation catalog. This enables other AWS analytics services to discover and access live and transactionally consistent data in Amazon Redshift managed storage. For example, you could incorporate live data from Amazon Redshift in an Amazon EMR Spark data pipeline, perform ad-hoc queries on Amazon Redshift data using Amazon Athena, or use clean and curated data in Amazon Redshift to build machine learning models with Amazon SageMaker. The following diagram illustrates this architecture.
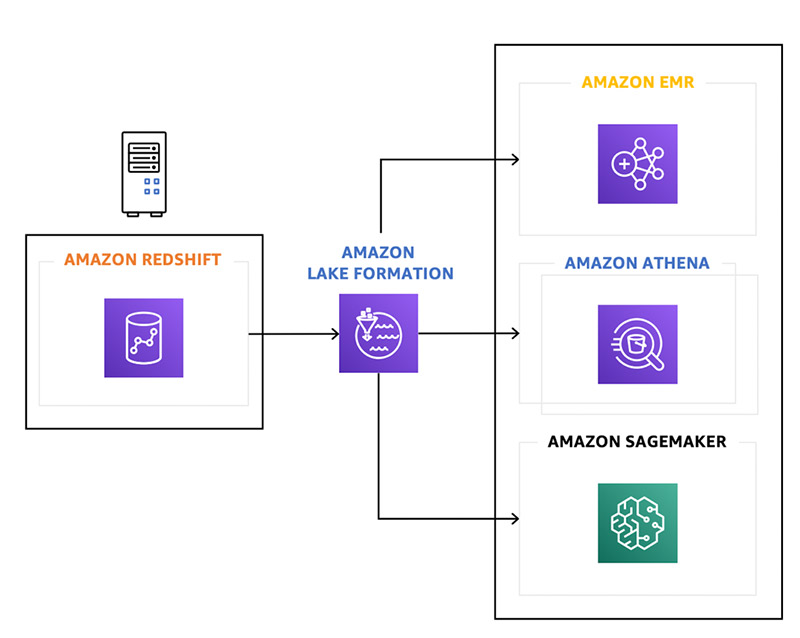
Amazon Redshift data sharing in customer environments
Data sharing across Amazon Redshift clusters within the same account is now available for preview. Sharing across clusters that are in different AWS accounts is coming soon. We worked closely with several customers and partners for an early preview of data sharing and they are excited about the results and possibilities.
“At Warner Bros. Games, we build and maintain complex data mobility infrastructures to manage data movements across single game clusters and consolidated business function clusters. However, developing and maintaining this system monopolizes valuable team resources and introduces delays that impede our ability to act on the data with agility and speed. Using the Redshift data sharing feature, we can remove the entire subsystem we built for data copying, movement, and loading between Redshift clusters. This will empower all of our business teams to make decisions on the right datasets more quickly and efficiently. Additionally, Redshift data sharing will also allow us to re-architect compute provisioning to more closely align with the resources needed to execute those functions’ SQL workloads—ultimately enabling simpler infrastructure operations.”
— Kurt Larson, Technical Director, Warner Bros. Analytics
“The data sharing feature seamlessly allows multiple Redshift clusters to query data located in our RA3 clusters and their managed storage. This eliminates our concerns with delays in making data available for our teams, and reduces the amount of data duplication and associated backfill headache. We now can concentrate even more of our time making use of our data in Redshift and enable better collaboration instead of data orchestration.”
— Steven Moy, Engineer, Yelp
“At Fannie Mae, we adopted a de-centralized approach to data warehouse management with tens of Amazon Redshift clusters across many applications. While each team manages their own dataset, we often have use cases where an application needs to query the datasets from other applications and join with the data available locally. We currently unload and move data from one cluster to another cluster, and this introduces delays in providing timely access to data to our teams. We have had issues with unload operations spiking resource consumption on producer clusters, and data sharing allows us to skip this intermediate unload to Amazon S3, saving time and lowering consumption. Many applications are performing unloads currently in order to share datasets, and we plan to convert all such processes to leveraging the new data sharing feature. With data sharing, we can enable seamless sharing of data across application teams and give them common views of data without having to do ETL. We are also able to avoid the data copies between pre-prod, research, and production environments for each application. Data sharing made us more agile and gave us the flexibility to scale analytics in highly distributed environments like Fannie Mae.”
— Amy Tseng, Enterprise Databases Manager, Fannie Mae
“Shared storage allowed us to focus on what matters: making data available to end-users. Data is no longer stuck in a myriad of storage mediums or formats, or accessible only through select APIs, but rather in a single flavor of SQL.”
— Marco Couperus, Engineering Manager, home24
“We’re excited to launch our integration with Amazon Redshift data sharing, which is a game changer for analytics teams that are looking to improve analytics performance SLAs and reduce data processing delays for diverse workloads across organizations. By isolating workloads that have different access patterns, different SLA requirements such as BI reporting, dashboarding applications, ETL jobs, and data science workloads into separate clusters, customers will now get more control over compute resources and more predictability in their workload SLAs while still sharing common data. The integrations of Etleap with Amazon Redshift data sharing will make sharing data between clusters seamless as part of their existing data pipelines. We are thrilled to offer this integrated experience to our joint customers.”
— Christian Romming, Founder and CEO, Etleap
“We’re excited to partner with AWS to enable data sharing for Amazon Redshift within Aginity Pro. Amazon Redshift users can now navigate and explore shared data within Aginity products just like local data within their clusters. Users can then build reusable analytics that combine both local and shared data seamlessly using cross-database queries. Importantly, shared data query performance has the same high performance as local queries without the cost and performance penalty of traditional federation solutions. We’re thrilled to see how our customers will leverage the ability to securely share data across clusters.”
— Matthew Mullins, CTO, Aginity
Next steps
The preview for within account data sharing is available on Amazon Redshift RA3 node types in the following regions:
- US East (Ohio)
- US East (N. Virginia)
- US West (N. California)
- US West (Oregon)
- Asia Pacific (Seoul)
- Asia Pacific (Sydney)
- Asia Pacific (Tokyo)
- Europe (Frankfurt)
- Europe (Ireland)
For more information about how to get started with the preview, see documentation.
About the Authors
 Neeraja Rentachintala is a principal product manager with Amazon Redshift. She is a seasoned product management and GTM leader, bringing over 20 years of experience in product vision, strategy, and leadership roles in data products and platforms, and has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud.
Neeraja Rentachintala is a principal product manager with Amazon Redshift. She is a seasoned product management and GTM leader, bringing over 20 years of experience in product vision, strategy, and leadership roles in data products and platforms, and has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud.
 Ippokratis Pandis is a senior principal engineer at AWS. Ippokratis leads initiatives in AWS analytics and data lakes, especially in Amazon Redshift. He holds a Ph.D. in electrical engineering from Carnegie Mellon University.
Ippokratis Pandis is a senior principal engineer at AWS. Ippokratis leads initiatives in AWS analytics and data lakes, especially in Amazon Redshift. He holds a Ph.D. in electrical engineering from Carnegie Mellon University.
 Naresh Chainani is a senior software development manager with Amazon Redshift, where he leads Query Processing, Query Performance, Distributed Systems, and Workload Management with a strong team. He is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
Naresh Chainani is a senior software development manager with Amazon Redshift, where he leads Query Processing, Query Performance, Distributed Systems, and Workload Management with a strong team. He is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.